【语音AI】语音识别ASR逻辑摸索与测试验证方法
在公司待了快四年时间了,针对这块涉及的内容会做个系列的说明,可以供参考
一语音识别的原理
语音识别的本质是一种基于语音特征参数的模式识别,即通过学习,系统能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果。
虽然只有一句话,但这里面涉及的信息非常多。
简单来说,自动语音识别技术(Automatic Speech Recognition)是一种将人的语音转换为文本的技术。
所谓语音识别,就是将一段语音信号转换成相对应的文本信息,系统主要包含特征提取、声学模型,语言模型以及字典与解码四大部分。(此模块可以单纯理解成是做语音识别。)
此外为了更有效地提取特征往往还需要对所采集到的声音信号进行滤波、分帧等音频数据预处理工作,将需要分析的音频信号从原始信号中合适地提取出来。
特征提取工作将声音信号从时域转换到频域,为声学模型提供合适的特征向量。(此模块可以理解成是在做信号处理)
声学模型中再根据声学特性计算每一个特征向量在声学特征上的得分,而语言模型则根据语言学相关的理论,计算该声音信号对应可能词组序列的概率。
最后根据已有的字典,对词组序列进行解码,得到最后可能的文本表示。
二语音识别的流程
1.预处理
在实际应用中,送到这块的音频实际上是做完信号处理,得到最优化的音频数据。拿到音频通过vad切除静音音频,并且将非静音音频切割成小段去做特征向量提取。
2.特征提取
将每一帧的波形变成一个包含声音信息的多维向量。
3.声学模型,语言模型
输出音素信息和字词相关联的概率
4.字典匹配
字或者词与音素的对应, 简单来说, 中文就是拼音和汉字的对应,英文就是音标与单词的对应。
5.解码
搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这称之为“解码”。
三识别率评估标准
1.1句错率
- 句错误率:Sentence Error Rate
- 解释:句子识别错误的的个数,除以总的句子个数即为SER
-
计算公式:(所有公式省了 * 100%)
SER = 错误句数 / 总句数
1.2句正确率
- 句正确率:Sentence Correct
-
计算公式:
S.Corr = 1 - SER = 正确句数 / 总句数
1.3、词/字错率(WER/CER)
WER,Word error rate,词错率,但一般称为字错率,是语音识别领域的关键性评估指标,WER越低表示效果越好!
CER,Character Error Rate,字符错误率,中文一般用CER来表示字错率
1.4.1 、计算原理
字符串编辑距离(Levenshtein距离)算法
1.4.2、计算公式(重要)
WER = (S(替换) + D(删除) + I(插入) ) / N = (S + D + I ) / (S + D + H(正确) )
- S 为替换的字数,常用缩写WS
- D 为删除的字数,常用缩写WD
- I 为插入的字数,常用缩写WI
- H 为正确的字数,维基百科是C,但我统一改用H
- N 为(S替换+ D删除+ H正确)的字数
具体计算可以参考
https://testerhome.com/topics/27270
四HResults介绍
隐马尔可夫模型工具包(HTK)是用于构建和处理隐马尔可夫模型的便携式工具包。 HTK主要用于语音识别研究,尽管它已用于许多其他应用程序,包括语音合成,字符识别和DNA测序的研究。 HTK已在全球数百个站点中使用。 HTK包含以C源代码形式提供的一组库模块和工具。这些工具为语音分析,HMM培训,测试和结果分析提供了完善的工具。该软件支持使用连续密度混合高斯和离散分布的HMM,并可用于构建复杂的HMM系统。 HTK版本包含大量的文档和示例。
主页
五HResults样例解析
关于HResult的用法如下
USAGE: HResults [options] labelList recFiles...
Option Default
-a s Redefine string level label SENT
-b s Redefine unitlevel label WORD
-c Ignore case differences off
-d N Find best of N levels 1
-e s t Label t is equivalent to s
-f Enable full results off
-g fmt Set test label format to fmt HTK
-h Enable NIST style formatting off
-k s Results per spkr using mask s off
-m N Process only the first N rec files all
-n Use NIST alignment procedure off
-p Output phoneme statistics off
-s Strip triphone contexts off
-t Output time aligned transcriptions off
-u f False alarm time units (hours) 1.0
-w Enable word spotting analysis off
-z s Redefine null class name to s ???
-A Print command line arguments off
-C cf Set config file to cf default
-D Display configuration variables off
-G fmt Set source label format to fmt as config
-I mlf Load master label file mlf
-L dir Set input label (or net) dir current
-S f Set script file to f none
-T N Set trace flags to N 0
-V Print version information off
-X ext Set input label (or net) file ext lab
常用参数
-t 指标注和测试集对比的log日志,能看到每一条音频下的对比结果
-h 启用NIST样式格式
...
补充下测试集和标注集
#!MLF!# "*no1.lab" 查 查 小 贝 今 天 比 赛 时 间 . "*no2.lab" 今 天 恒 大 队 和 国 安 队 的 比 分 是 多 少 . #!MLF!# "*no1.rec" 查 查 小 卫 今 天 比 赛 . "*no2.rec" 今 天 恒 大 队 和 国 安 队 的 比 分 是 多 少 .
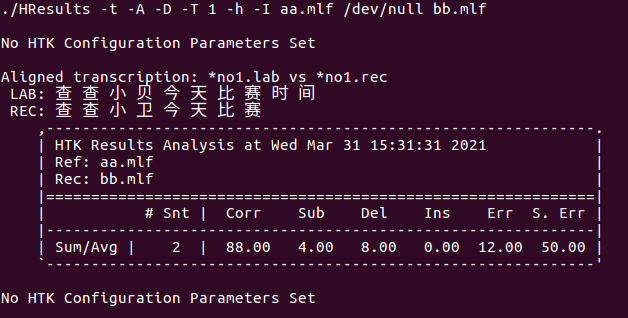
打印了错误的对比log日志和相关结果的表格
Snt:拢共对比了2条音频
Corr:正确率88%
Sub:替换的字符
Del:删除的字符
Ins:插入的字符
字错误率:12%
句错误率:50%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号