selenium-获取一组数组进行操作(七)
selenium-获取一组数组进行操作
以 纵横中文网 中获取24小时畅销榜的书单为例
此文仅做 selenium 在自动化测试中怎么获取一组数据进行说明,不做网络爬虫解释
当然,使用爬虫得到本文的结果会简单快捷的多
区别 selenium 中的 elements 与 element
例如:list.find_elements_by_class_name('rank_i_bname') # 获得 class name 为 rank_i_bname 的所有数据
list.find_element_by_class_name('rank_i_p_tit') # # 获得 class name 为 rank_i_p_tit 的一个数据,如果有多个则只取第一个
步骤:
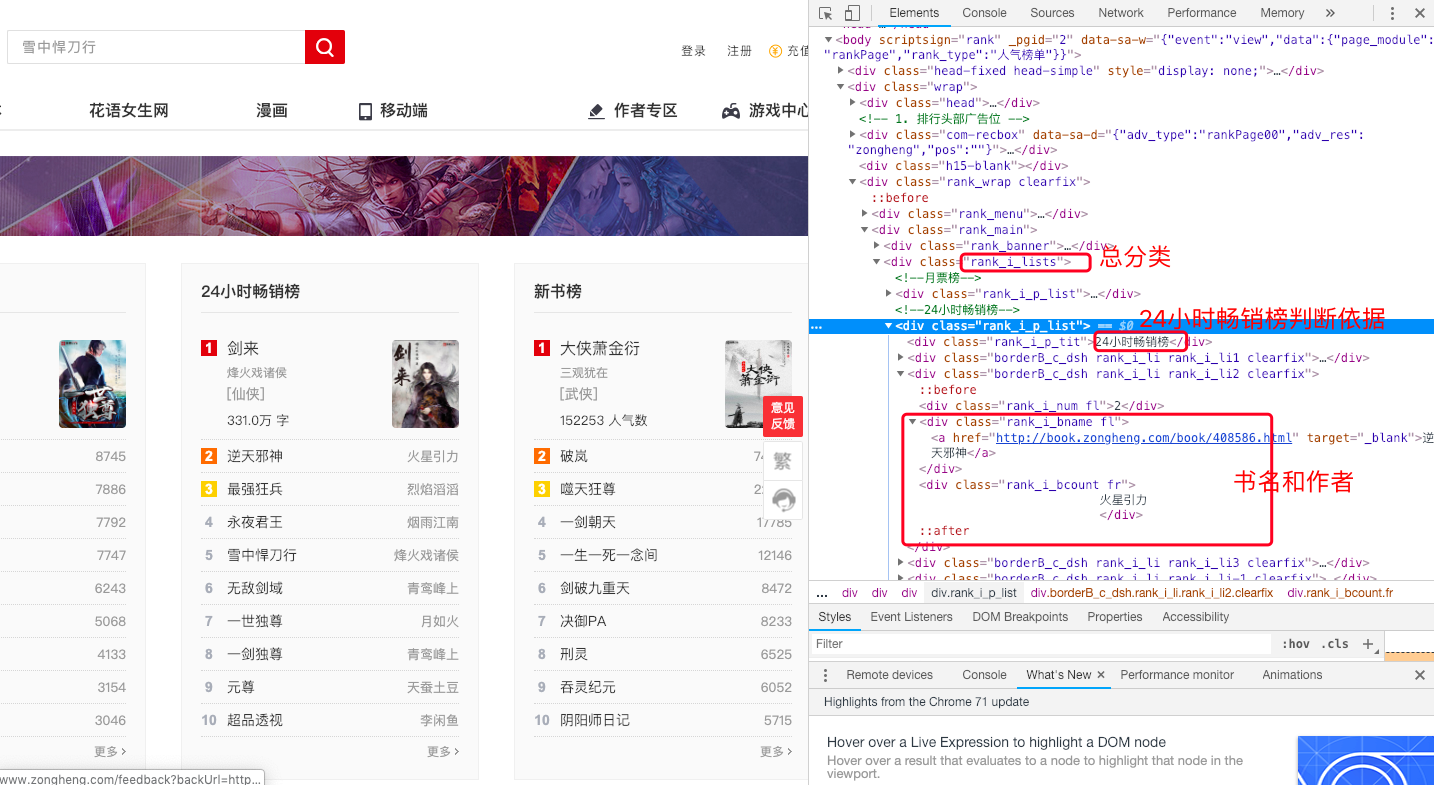
使用 selenium 定位到总分类
然后通过判断24小时畅销榜,进入到24小时畅销榜的书目录
最后获得书名和作者
如下图
代码如下:
1 #coding=utf-8 2 3 from selenium import webdriver 4 import unittest 5 6 7 class getListall(unittest.TestCase): 8 9 def setUp(self): 10 11 # 纵横小说中文网 12 base_url = 'http://book.zongheng.com/rank.html' 13 self.driver = webdriver.Chrome() 14 self.driver.implicitly_wait(10) 15 self.driver.get(base_url) 16 17 def test_get_list_all(self): 18 u"""获取数组""" 19 driver = self.driver 20 # 获取所有分类 21 lists = driver.find_elements_by_class_name('rank_i_p_list') 22 for list in lists: 23 # 获取24小时畅销榜下的书 24 if list.find_element_by_class_name('rank_i_p_tit').text == "24小时畅销榜": 25 26 # 获取书 27 names = list.find_elements_by_class_name('rank_i_bname') 28 authors = list.find_elements_by_class_name('rank_i_bcount') 29 30 # 打印获取的数据 31 for name,author in zip(names,authors): 32 print(name.text + "," + author.text + ";") 33 34 35 def tearDown(self): 36 self.driver.quit() 37 38 39 if __name__ == '__main__': 40 unittest.main()
运行结果
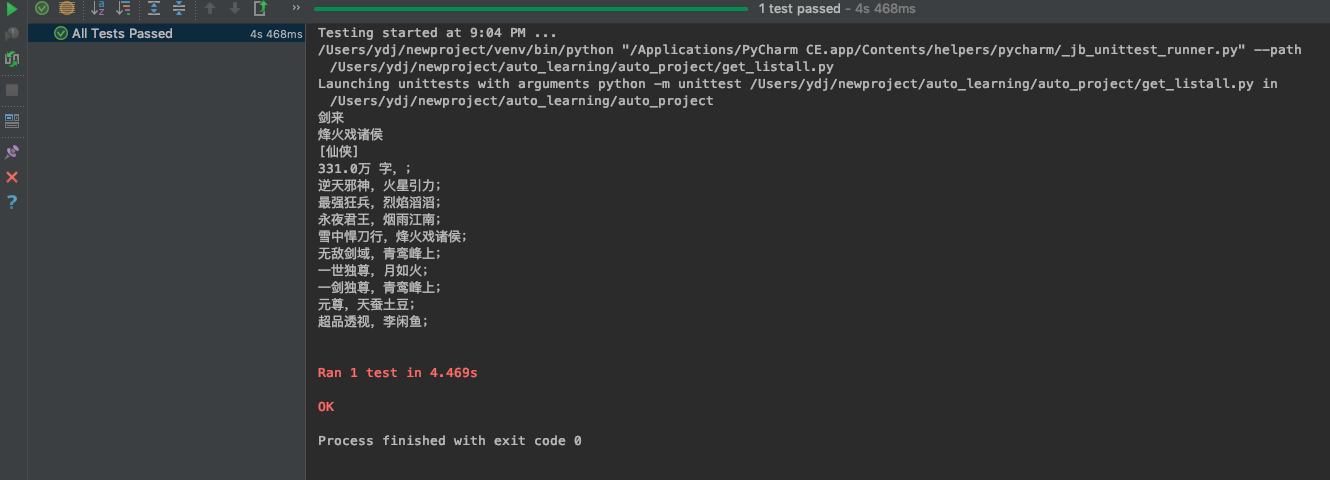
结果分析
分析结果会发现,第一个书单所获取的信息和其他的书单信息不一致
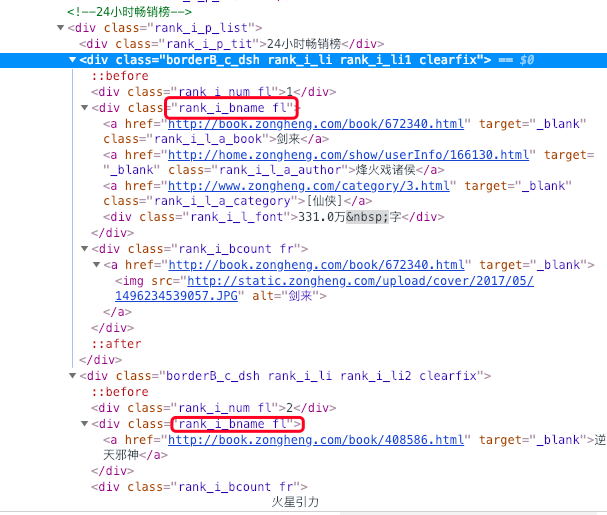
原因:查看网页html便可知
class=“rank_i_bname” 下的 text ,第一个书单和其他书单的信息是不一样的
如果看起来不美观可以将第一个书单提取处理单独进行定位获取信息进行打印
然后在 for 循环中将获取到的书单的第一个信息不要打印
问题解决

 浙公网安备 33010602011771号
浙公网安备 33010602011771号