

kubernetes实战之部署一个接近生产环境的consul集群
前面我们介绍了如何在windows单机以及如何基于docker部署consul集群,看起来也不是很复杂,然而如果想要把consul部署到kubernetes集群中并充分利用kubernetes集群的伸缩和调度功能并非易事.前面我们首先部署一个节点,部署完成以后获取它的ip,然后其它的ip都join到这个ip里组成集群.
前面的部署方式存在以下问题:
- 集群易主
我们知道,在kubernetes里,当节点发生故障或者资源不足时,会根据策略杀掉节点的一些pod转而将pod移到其它节点上.这时候我们就需要重新获取主节点ip,然后将新的节点加入进去,以上做法不利于充分发挥kubernetes自身的伸缩功能.
- 新节点加入
不管是新节点加入或者失败后重新生成的节点重新加入集群,都需要知道主节点ip,这会产生和上面相同的问题,就是需要人工介入.
理想的状态是,当集群主节点切换时,新节点仍然能够在无需人工介入的情况下自动加入集群.我们解决这个问题的思路如下:使用kubernetes集群的dns功能,而不直接硬编码节点的ip.如果集群中有三个server,则这三个sever中必然有一个是主节点,我们可以依次尝试通过dns来解析到具体的节点,依次尝试加入每一个sever节点,尝试到真正的主节点时便能够加入集群.
我们首先创建服务,定义服务的文件名为consul-service.yml
apiVersion: v1
kind: Service
metadata:
name: consul
labels:
name: consul
spec:
type: ClusterIP
ports:
- name: http
port: 8500
targetPort: 8500
- name: https
port: 8443
targetPort: 8443
- name: rpc
port: 8400
targetPort: 8400
- name: serflan-tcp
protocol: "TCP"
port: 8301
targetPort: 8301
- name: serflan-udp
protocol: "UDP"
port: 8301
targetPort: 8301
- name: serfwan-tcp
protocol: "TCP"
port: 8302
targetPort: 8302
- name: serfwan-udp
protocol: "UDP"
port: 8302
targetPort: 8302
- name: server
port: 8300
targetPort: 8300
- name: consuldns
port: 8600
targetPort: 8600
selector:
app: consul
通过以上服务我们把pod的端口映射到集群中,通过名称我们可以看到每一个商品做什么类型通信用的.这个服务会选择标签为app: consul的pod.通过这个示例我们也可以看到,对于一些复杂的服务,采用nodeport类型的服务是很不可取的.这里使用的是clusterip类型的服务.后面我们会通过nginx ingress controller把http端口暴露到集群外,供外部调用.
我们通过kubectl create -f consul-service.yml来创建这个服务
这里我们采用的是statefulset的方式创建的server,这里之所以使用statefulset是因为statefulset包含的pod名称是固定的(普通pod以一定hash规则随机生成),如果命名规则固定,pod数量固定,则我们可以预先知道它们的dns规则,以便在自动加入集群中时使用. statefulset创建文件如下(名为consul-statefulset.yml)
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: consul
spec:
serviceName: consul
replicas: 3
template:
metadata:
labels:
app: consul
spec:
terminationGracePeriodSeconds: 10
containers:
- name: consul
image: consul:latest
args:
- "agent"
- "-server"
- "-bootstrap-expect=3"
- "-ui"
- "-data-dir=/consul/data"
- "-bind=0.0.0.0"
- "-client=0.0.0.0"
- "-advertise=$(PODIP)"
- "-retry-join=consul-0.consul.$(NAMESPACE).svc.cluster.local"
- "-retry-join=consul-1.consul.$(NAMESPACE).svc.cluster.local"
- "-retry-join=consul-2.consul.$(NAMESPACE).svc.cluster.local"
- "-domain=cluster.local"
- "-disable-host-node-id"
env:
- name: PODIP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- containerPort: 8500
name: ui-port
- containerPort: 8400
name: alt-port
- containerPort: 53
name: udp-port
- containerPort: 8443
name: https-port
- containerPort: 8080
name: http-port
- containerPort: 8301
name: serflan
- containerPort: 8302
name: serfwan
- containerPort: 8600
name: consuldns
- containerPort: 8300
name: server
通过以上定义文件我们可以看到,里面最核心的部分是--retry-join后面的dns规则,由于我们指定了pod名称为consul,并且有三个实例,因此它们的名称为consul-0,consul-1,consul-2,即便有节点失败,起来以后名称仍然是固定的,这样不管新起的podIp是多少,通过dns都能够正确解析到它.
这里的data-dir以前没有提到过,很容易理解,就是consul持久化数据存储的位置.我们前面说过server节点的数据都是要持久化存储的,这个data-dir便是持久化数据存储的位置.
我们可以通过进入到pod内部来查看consul集群的成员信息
[centos@k8s-master ~]$ clear
[centos@k8s-master ~]$ kubectl exec -it consul-0 /bin/sh
/ # consul members
Node Address Status Type Build Protocol DC Segment
consul-0 10.244.1.53:8301 alive server 1.4.4 2 dc1 <all>
consul-1 10.244.1.54:8301 alive server 1.4.4 2 dc1 <all>
consul-2 10.244.1.58:8301 alive server 1.4.4 2 dc1 <all>
/ #
通过以上大家可以看到,Ip 53和54是相邻的,但是58是跳跃的,这是因为我故意删除了其中的一个pod,由于我们在创建statefulset的时候指定的副本集个数为3,因此kubernetes会重新创建一个pod,经过测试这个新创建的pod仍然能够正确加入集群,符合我们的需求.
我们在容器内执行curl localhost:8500的时候,会出现以下结果
<a href="/ui/">Moved Permanently</a>.
不用担心,以上结果是正确的,因为通过浏览器访问的话,localhost:8500会自动跳转到http://localhost:8500/ui/dc1/services默认ui展示界面,由于curl无法模拟浏览器交互跳转行为,因此显示以上内容永久重定向.
以上节本完成了demo演示,但是仍然有两个问题
- 第一,我们直接把data存储到了容器内,如果容器被销毁然后重新创建,则数据会丢失.这样显然是存在风险的,正确的做法是把容器内持久化数据的目录挂载到宿主机上,但是由于我的测试集群中有一主一从,因此把容器目录挂载到宿主机会造成目录冲突,所以这里没有把存储内容挂载到宿主机.
其它有状态服务也要把持久化数据目录挂载到宿主机上
- 我们在部署server的时候为了保证高可用,两个或以上server不能部署到同一台机器或者由于故障出现被转移到了相同机器,这样一方面增加了server的压力,同时另一方面也降低了可用性,因为宿主机宕机时上面的节点都会宕掉,这样与多server部署高可用的初衷相违背的.实际上,部署其它有状态的服务也要考虑到这个问题.在kubernetes里,解决这个问题使用的是pod的反亲和属性,亲和pod和主动靠拢,反亲和属性的pod则恰恰相反,它们之间相互排斥.利用这个特性可以满足我们的需求.这里之所以没有使用反亲和的原因也是集群的节点不够,如果节点相互排斥就无法部署成功了.
下面贴出完整的配置
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: consul
spec:
serviceName: consul
replicas: 3
template:
metadata:
labels:
app: consul
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- consul
topologyKey: kubernetes.io/hostname
terminationGracePeriodSeconds: 10
containers:
- name: consul
image: consul:latest
args:
- "agent"
- "-server"
- "-bootstrap-expect=3"
- "-ui"
- "-data-dir=/consul/data"
- "-bind=0.0.0.0"
- "-client=0.0.0.0"
- "-advertise=$(PODIP)"
- "-retry-join=consul-0.consul.$(NAMESPACE).svc.cluster.local"
- "-retry-join=consul-1.consul.$(NAMESPACE).svc.cluster.local"
- "-retry-join=consul-2.consul.$(NAMESPACE).svc.cluster.local"
- "-domain=cluster.local"
- "-disable-host-node-id"
volumeMounts:
- name: data
mountPath: /consul/data
env:
- name: PODIP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- containerPort: 8500
name: ui-port
- containerPort: 8400
name: alt-port
- containerPort: 53
name: udp-port
- containerPort: 8443
name: https-port
- containerPort: 8080
name: http-port
- containerPort: 8301
name: serflan
- containerPort: 8302
name: serfwan
- containerPort: 8600
name: consuldns
- containerPort: 8300
name: server
volumes:
- name: data
hostPath:
path: /home/data
以上需要注意的是,要挂载到的宿主机的目录必须是预先存在的,kubernetes并不会在宿主机上创建需要的目录.
由于主机节不能容纳普通pod,因此要完成以上高可用部署,需要集群中至少有四个节点.(如果不使用完整配置,则只需要一主一从即可)
通过以上配置,我们便可以在kubernetes集群内部访问consul集群了,但是如果想要在集群外部访问.还需要将服务暴露到集群外部,前面章节我们也讲到过如何将服务暴露到集群外部.这里我们使用 nginx-ingress 方式将服务暴露到外部.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-consul
namespace: default
annotations:
kubernets.io/ingress.class: "nginx"
spec:
rules:
- host: consul.my.com.local
http:
paths:
- path:
backend:
serviceName: consul
servicePort: 8500
由于我没有申请域名,因此我使用的hosts里添加映射的方式来访问的.我已经在hosts文件里添加了映射,这里直接打开浏览器访问
我们点击Nodes可以看到一共有三个节点
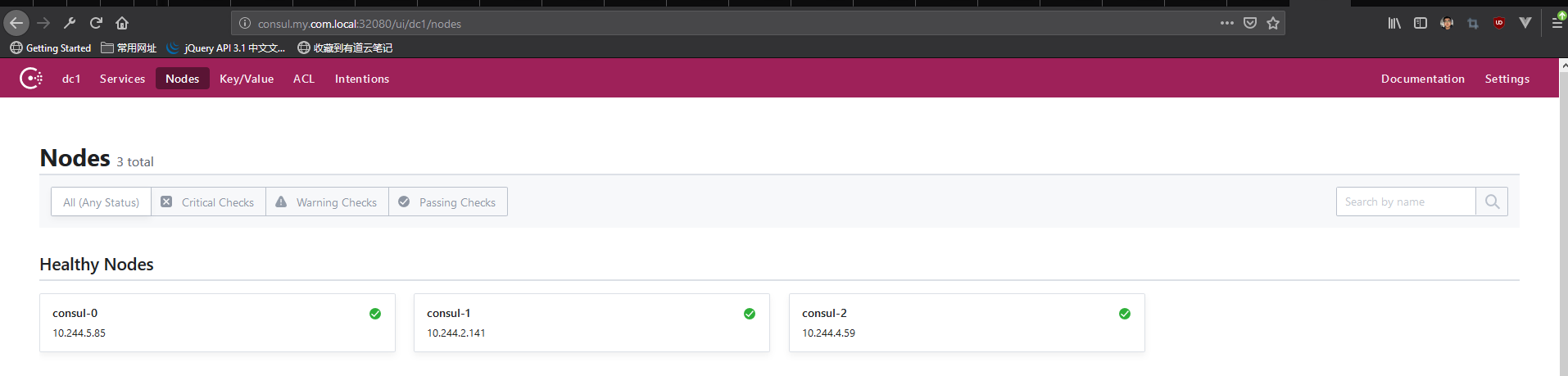
节点后面的绿色对号标识表示服务的状态是可用的
节点挂掉后新启动节点自动加入集群
如果集群中有节点挂掉后,存活的节点仍然符合法定数量(构建一个consul集群至少需要两个存活节点进行仲裁),由于statefulset规定的副本集的数量是3,因此k8s会保证有3个数量的副本集在运行,当k8s集群发现运行的副本数量少于规定数量时,便会根据调度策略重新启动一定数量pod以保证运行副本集数量和规定数量相符.由于在编排consul部署时使用了retry-join参数,因此有新增节点会自动尝试重新加入集群(传统方式是根据ip来加入集群),同样如果挂掉的是master节点也不用担心,如果存活节点数量仍然符合法定数量(这里的法定数量并不是指statefulset副本集数量,而是consul组成集群所需要最小节点数量),consul会依据一定策略重新选择master节点.
我们先来看一下集群中pod状态
[root@k8s-master consul]# kubectl get pod
NAME READY STATUS RESTARTS AGE
consul-0 1/1 Running 0 9m20s
consul-1 1/1 Running 0 9m19s
consul-2 1/1 Running 0 9m17s
easymock-dep-84767b6f75-57qm2 1/1 Running 1708 35d
easymock-dep-84767b6f75-mnfzp 1/1 Running 1492 40d
mvcpoc-dep-5856db545b-qndrr 1/1 Running 1 46d
sagent-b4dd8b5b9-5m2jc 1/1 Running 3 54d
sagent-b4dd8b5b9-brdn5 1/1 Running 1 40d
sagent-b4dd8b5b9-hfmjx 1/1 Running 2 50d
stock-dep-5766dfd785-gtlzr 1/1 Running 0 5d18h
stodagent-6f47976ccb-8fzmv 1/1 Running 3 56d
stodagent-6f47976ccb-cv8rg 1/1 Running 2 50d
stodagent-6f47976ccb-vf7kx 1/1 Running 3 56d
trackingapi-gateway-dep-79bb86bb57-x9xzp 1/1 Running 3 56d
www 1/1 Running 1 48d
我们看到有三个consul pod在运行
下面我们手动杀掉一个pod,来模拟故障.
[root@k8s-master consul]# kubectl delete pod consul-0
pod "consul-0" deleted
由于consul-0被干掉,因此consul集群中consul-0变得不可用
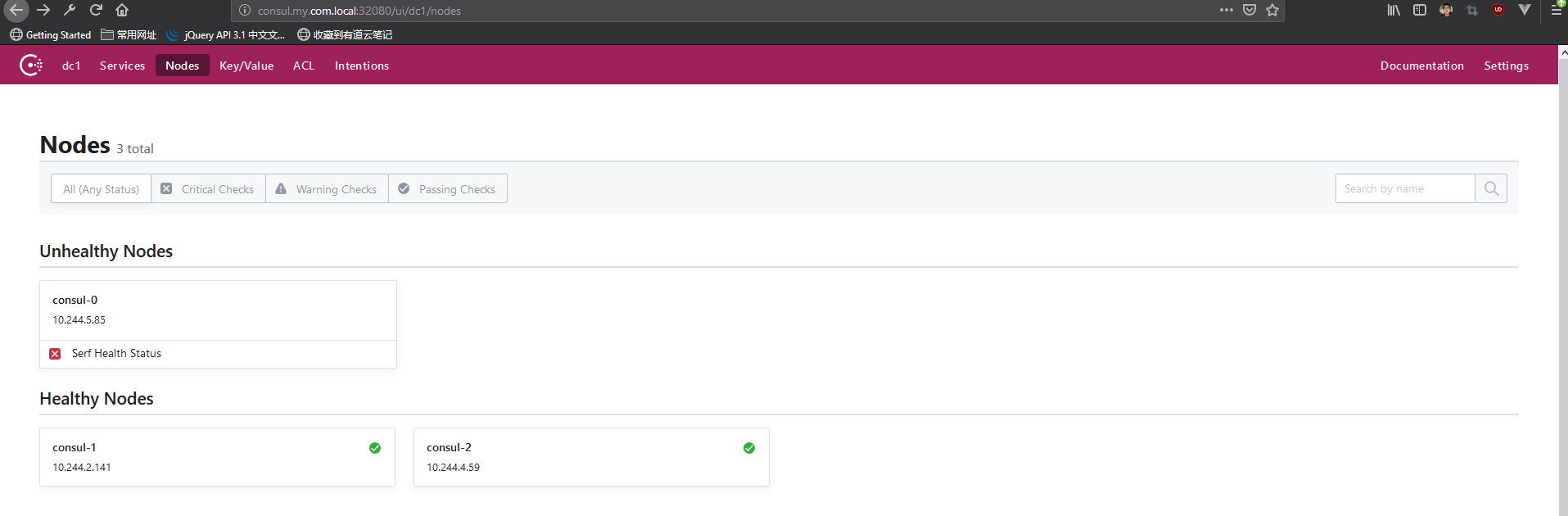
过一段时间后,k8s检测到运行的pod数量少于stateful规定的数量,便会重新再启动一个pod(需要注意的是,这里的重新启动并不是把原来pod重新启动,而是重新再调度一个全新的pod到集群中,这个pod与挂掉的pod无任何关系,当然ip也是不一样的,如果仍然依赖ip,则会带来无限麻烦)
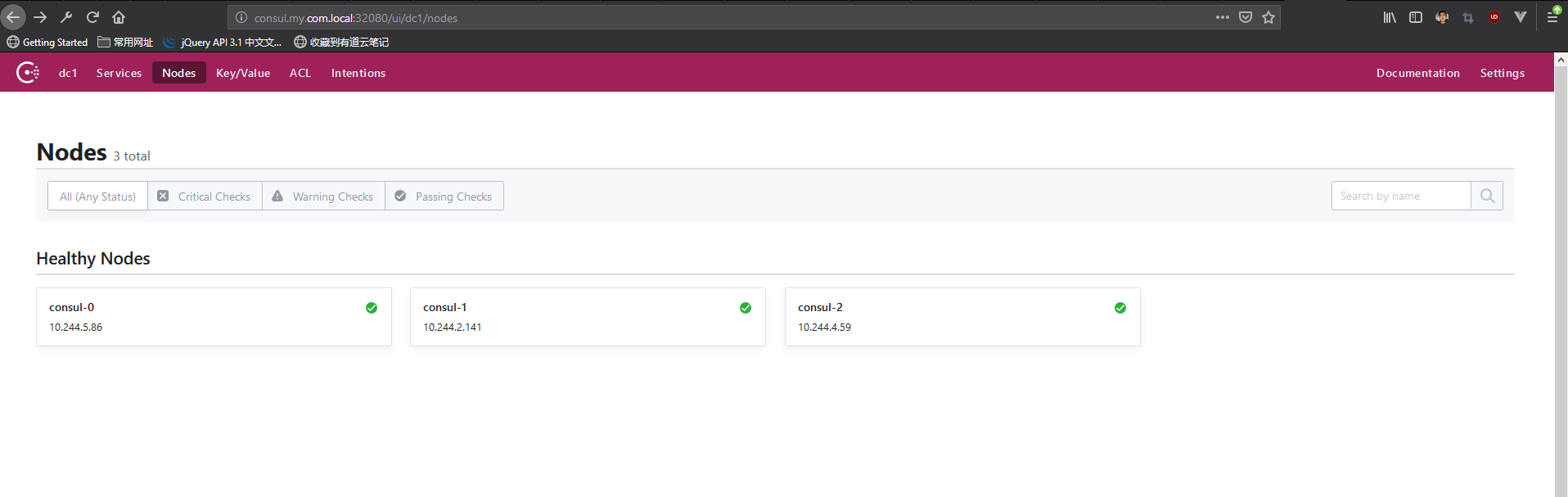
我们可以看到,这时候consul-0服务的ip已经变成了86(前面是85)
部署nginx ingress可能并不是一件非常容易的事,由其是对使用单节点docker on windows的朋友来说,如果有的朋友不想部署nginx ingress,仅做为测试使用,也可以把服务的类型由
ClusterIP更改为NodePort类型,这样就可以像docker一样把服务的端口映射到宿主机端口,方便测试.
本节涉及到的内容比较多,也相对比较复杂(前面也多次说过,部署有状态服务是难点),因此后面会专门再开一节来详细讲解本文中的一些细节,有问题的朋友也可以留言或者通过其它方式联系我,大家共同交流


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通