新闻项目——首页内容整体分析
第一步:点击排行后台处理
根据看页面的分析,将点击排行后台写入首页代码里index.views。
@index_blue.route("/") def index(): """" 首页渲染 1.处理右上角的逻辑 1.1获取session值(id) 1.2根据id查询到指定用户 2.点击排行部分处理 从数据库中进行新闻表查询,根据点击进行排序 3.构造数据交给前端进行渲染 """ # 首页渲染 # 1.处理右上角的逻辑 # 1.1获取session值(id) user_id = session.get("id") # 1.2根据id查询到指定用户 user = None try: user = User.query.filter_by(id=user_id).first() # user = User.query.filter_by(User.id == user_id).first() except Exception as e: current_app.logger.error(e) # 2.点击排行部分处理 # 从数据库中进行新闻表查询,根据点击进行排序 news_clicks = None try: news_clicks = News.queyr.order_by(News.clicks.desc()).limit(6) except Exception as e: current_app.logger.error(e) # 1.3将查询到的用户信息返回给前台进行渲染 context = { "user":user, "news_clicks":news_clicks } return render_template("news/index.html", context=context)
第二步:点击排行前台处理
前台的排行代码是写死的,所以我们先把它注释掉

然后我们需要用过滤器,这里去info.utils创建一个tools的文件来存放过滤器
def do_rank(index): """ 关于点击排行功能的class设置的过滤 :param index: 排行的数字 :return: 字符串,class的指定属性 """ if index == 1: return "first" if index == 2: return "second" if index == 3: return "third" else: return ""
过滤器写好还需要去info.init里注册
from info.utils.tools import do_rank app.add_template_filter(do_rank)
最后回到前台代码那加入
{% for new in context.news_click %}
<li><span class="{{ loop.index|rank }}">{{ loop.index }}</span><a href="#">{{ new.title }}</a></li>
{% endfor %}
第三步:首页新闻后台逻辑
接口设计
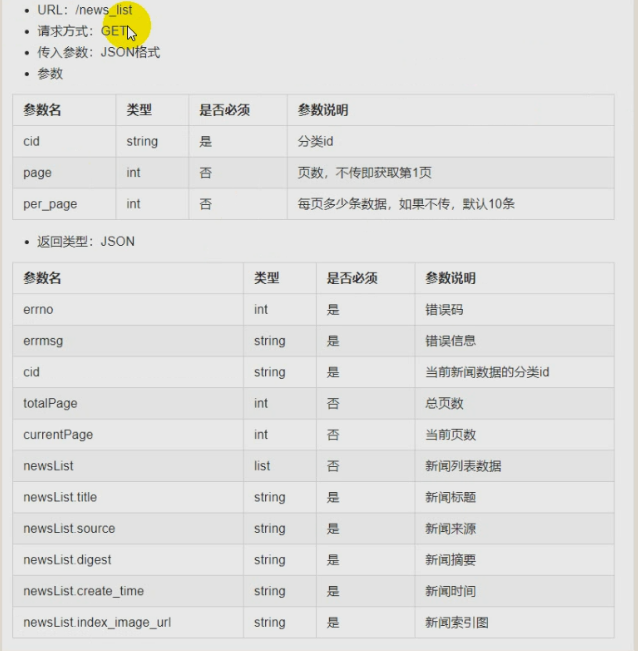
老规矩根据首页先分析逻辑再写代码
@index_blue.route("/news_list") def news_list(): """ 1获取参数(新闻分类id,页数,每页多少数据) 2.校验参数 判断传入的是否是数字,同时完成字符转换整形的操作 3.根据传入的数据完成相关内容的查找 4.返回值 :return: """ # 1获取参数(新闻分类id,页数,每页多少数据) cid = request.args.get("cid",1) page = request.args.get("page",1) per_page = request.args.get("per_page",10) # 2.校验参数 # 判断传入的是否是数字,同时完成字符转换整形的操作 try: cid = int(cid) page = int(page) per_page = int(per_page) except Exception as e: current_app.logger.error(e) return jsonify(errno=RET.PARAMERR,errmsg="参数错误") # 3.根据传入的数据完成相关内容的查找 if cid == 1: paginate = News.query.order_by(News.create_time.desc()).paginate(page=page, per_page=per_page) else: paginate = News.query.filter(News.category_id == cid).order_by(News.create_time.desc()).paginate(page=page, per_page=per_page) # paginate不是数据,是分页器 # 获取新闻数据 newsList = paginate.itmes # 获取总页数 totalPage = paginate.pages # 获取当前页数 currentPage = paginate.page # json可以识别的数据形式:字典,列表,列表和字典的混合形式 new_newsList = [] for new in new_newsList: new_newsList.append(new.to_basic_dict()) context = { "newsList": new_newsList, "totalPage": totalPage, "currentPage": currentPage } # 4.返回值 return jsonify(errno=RET.OK,errmsg="新闻获取成功",context=context)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号