
5详解awk中的NR==FNR
将两个文件具有相同列的行进行合并
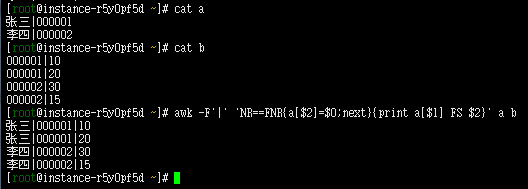
[root@tyjs09 ~]# cat a
张三|000001
李四|000002
[root@tyjs09 ~]# cat b
000001|10
000001|20
000002|30
000002|15
[root@tyjs09 ~]# awk -F'|' 'NR==FNR{a[$2]=$0;next}{print a[$1] FS $2}' a b
张三|000001|10
张三|000001|20
李四|000002|30
李四|000002|15
解释:
NR会将2个文件是为一个整体进行行计数,FNR会将每个文件是为一个整体进行技术,例如:
NR===>>123,456
FNR===>>123,123
本例中,当NR==FNR是为真,反之为假;为真时运行第一个动作{},不为真时就跳过第一个{},执行第二个{}。
$0表示整行,$1表示第一列,$2表示第二列
代码解说:
当为真时,执行第一个文件a,a的文件内容如下你:
张三|000001
李四|000002
那么a[$2]=$0其实就是定义了一个变量,即:a[000001] = 张三|000001
next表示执行下一行或者下一个周期。
awk -F'|' 'NR==FNR{a[$2]=$0;next}{print a[$1] FS $2}' a b
当NR!=FNR时,说明第一个文件已经执行完了,开始执行第二个文件了,第二个文件的内容如下:
000001|10
000001|20
000002|30
000002|15
那么a[$1]==a[00001]
请看两个红色的区域,将两个文件相同的内容作为每个文件的key值,a[$2], a[$1]其实这两个key都是a[000001]
定义第一个文件的key值等于整行内容 a[$2]=$0 ====>> a[000001] = 张三|000001
然后在执行第二个文件时用这个key进行取值a[$1](因为我们事先定义好的$1就是000001),
最后把文件2中剩下的内容进行拼接
{print a[$1] FS $2}
所以就有了上面的结果!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号