
4.Spark-3.1.2搭建
一.下载或放置压缩文件

二.解压文件
tar -zxf 被解压文件路径 -C 解压文件放置路径
三.配置文件
1.profile
vim /etc/profile
- 末尾添加
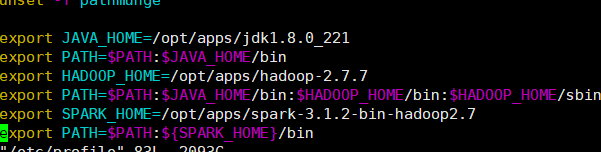
export SPARK_HOME=/opt/apps/spark-3.1.2-bin-hadoop2.7
export PATH=$PATH:${SPARK_HOME}/bin
-
按ESC键输入
:wq保存退出
![]()
-
更新profile
source /etc/profile
2.spark-env.sh配置
- 进入目录spark/conf
cd /opt/apps/spark-3.1.2-bin-hadoop2.7/conf
- 复制spark-env.sh.template 名命为spark-env.sh进行配置
cp -i spark-env.sh.template spark-env.sh
- 进入spark-env.sh
vim spark-env.sh
- 末尾添加代码
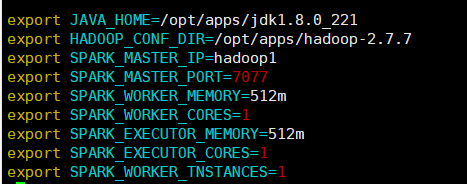
export JAVA_HOME=/opt/apps/jdk1.8.0_221
export HADOOP_CONF_DIR=/opt/apps/hadoop-2.7.7
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=1
export SPARK_EXECUTOR_MEMORY=512m
export SPARK_EXECUTOR_CORES=1
export SPARK_WORKER_TNSTANCES=1
- 按ESC键输入
:wq保存退出
(2)函数解析
| 函数 | = | 对应参数 |
| --- | --- | --- | --- |
| export JAVA_HOME | = | jdk目录 |
| export HADOOP_CONF_DIR | = | Hadoop目录 |
| export SPARK_MASTER_IP | = | 主节点名 |
| export SPARK _MASTER_PORT | = | 主节点端口号 |
| export SPARK_WORKER_MEMORY | = | 工作节点给Executors的内存 |
| export SPARK_WORKER_CORES | = | 节点核数 |
| export SPARK_EXECUTOR_MEMORY | = | 每个Executor的内存 |
| export SPARK_EXECUTOR_CORES | = | Execytor的核数 |
| export SPARK_WORKER_TNSTANCES | = | 节点的工作进程数 |
3.配置slave
- vim 创建slaves在本目录下
vim slaves
- 末尾添加内容
hadoop1
hadoop2
Hadoop3

按ESC键输入:wq保存退出
代码解析
| 代码 | 意义 |
|---|---|
| hadoop1 | 主节点名(可用主节点IP) |
| hadoop2 | 从节点名(可用从节点IP) |
| Hadoop3 | 从节点名(可用从节点IP) |
4.配置spark-defaults.conf
- 复制spark-defaults.conf.template名为spark-defaults.conf保存到当前目录
cp -i spark-defaults.conf.template spark-defaults.conf
- 进入spark-defaults.conf
vim spark-defaults.conf
- 在 #Example:下面覆盖为以下内容
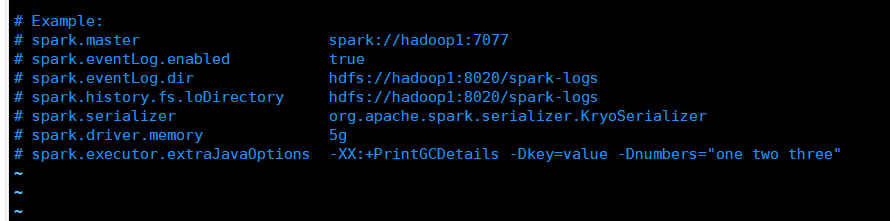
spark.master spark://hadoop1:7077
spark.eventLog.enabled true
spark.eventLog.dir dfs://hadoop1:8020/spark-logs
spark.history.fs.loDirectory hdfs://hadoop1:8020/spark-logs
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 5g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
注:#是要保留的
- 按ESC键输入
:wq保存退出
参数解析
| 参数 | 解释 | 默认 |
|---|---|---|
| spark.master | 主节点所在机器端口 | spark:// |
| spark.eventLog.enabled | 是否打开日志文件 | flase (不打开) |
| spark.eventLog.dir | 任务日志存放位置,(配置HDFS路径) | 无 |
| spark.history.fs.logDirectory | 存放历史应用日志文件的目录 | 无 |
拷贝spark
scp -r /opt/apps/spark-3.1.2-bin-hadoop2.7/ hadoop2:/opt/apps
scp -r /opt/apps/spark-3.1.2-bin-hadoop2.7/ hadoop3:/opt/apps
启动集群
- 先启动Hadoop
- 进入spark的sbin目录
cd /opt/apps/spark-2.4.7-bin-hadoop2.7/sbin
- 输入
./start-all.sh
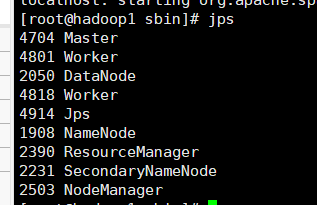
验证
启动Spark
spark-shell
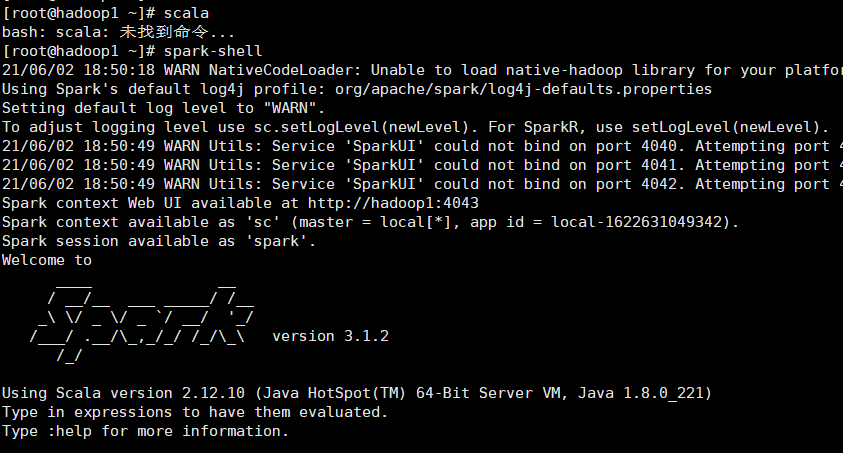
- 输入
:quit退出
集群启动
1.启动Hadoop集群
start-all.sh
2.启动Spark集群
cd /opt/apps/spark-3.1.2-bin-hadoop2.7/sbin
./start-all.sh
网页输入
- url
http://hadoop1:8080/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号