3.使用xshell进行配置Hadoop
一.预备准备
1.关闭防火墙
关闭防火墙的命令
systemctl stop firewalld.service
关闭防火墙的开机自启
systemctl disable firewalld.service

2.新建文件夹(放置安装好的文件)
mkdir -p /opt/apps /opt/
3.解压文件
输入命令解压java和Hadoop
tar -zxvf 地址/jdk-8u221-linux-x64.tar.gz -C /opt/apps/
tar -zxvf 地址/hadoop-2.7.7.tar.gz -C /opt/apps/
成功后如下图
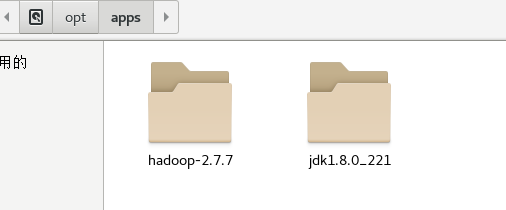
4.修改hosts文件
vim /etc/hosts
在末尾添加
主机IP 主机名
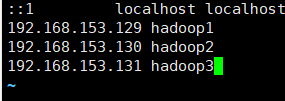
5.权限设置
vim /etc/sudoers
在 下插入
下插入
hadoop1 ALL=(ALL) NOPASSWD:ALL

二.jdk配置
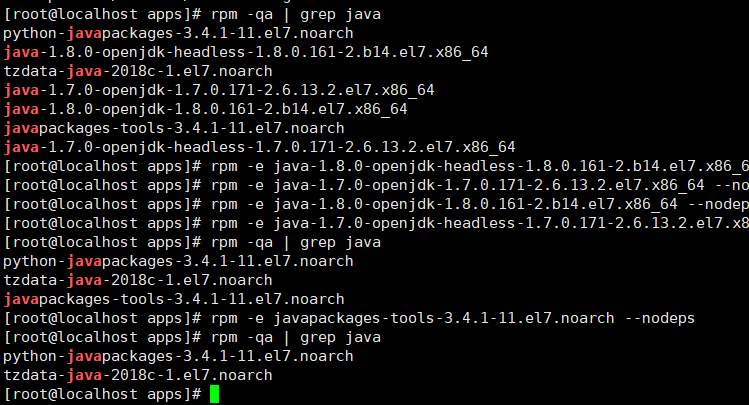
1.删除原有java
查询已经安装的java
rpm -qa | grep java
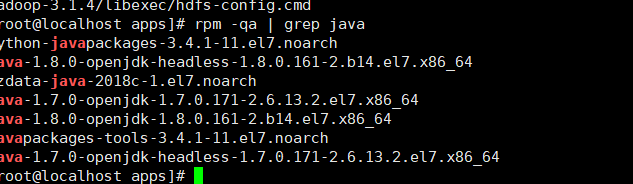
命令删除
rpm -e ** --nodeps
2.配置profile
进入profile
sudo vim /etc/profile
在末尾添加
export JAVA_HOME=/opt/apps/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
更新profile
source /etc/profile

查看配置是否成功
java -version
如图成功

3.拍摄快照(防止后面操作失误【可不进行】)

三.配置hdoop的profile
进入profile
sudo vim /etc/profile
末尾添加
export HADOOP_HOME=/opt/apps/hadoop-2.7.7
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

刷新配置
source /etc/profile
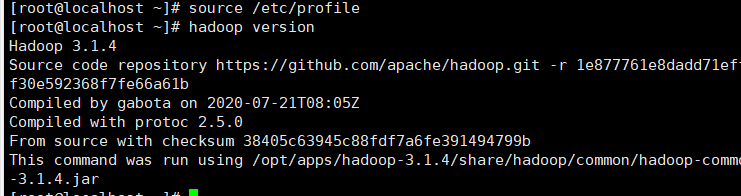
验证hadoop是否配置成功
hadoop version
四.克隆虚拟机
1.更改主机名
hostnamectl set-hostname xxx


重复修改剩下的主机
2.更改网络IP
vi /etc/sysconfig/network-scripts/ifcfg-ens33

更新网络
service network restart
重复修改剩下的主机
五.配置ssh免密
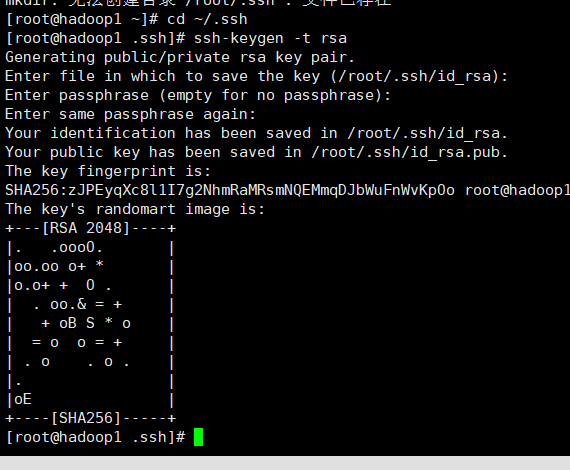
生成公钥
ssh-keygen -t rsa
全部回车
拷贝公钥
ssh-copy-id 要拷贝到的机器ip
完成主节点通从节点,从节点通主节点
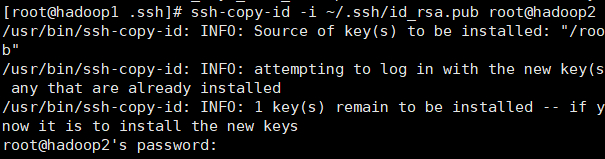
测试是否成功

六.配置hdoop
进入hadoop配置文件处
cd /opt/apps/hadoop-2.7.7/etc/hadoop
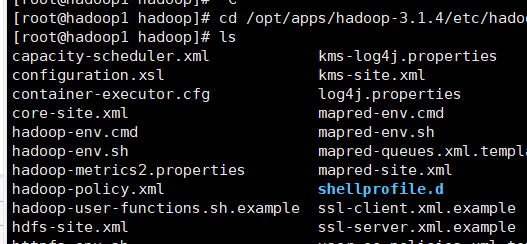
1.配置 hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/opt/apps/jdk1.8.0_221

2.配置core-site.xml
该文件用于指定Namenode
vim core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/home/apps/hadoop-2.7.7/data/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://tang1:9000</value>
</property>
tang1 为主节点主机名
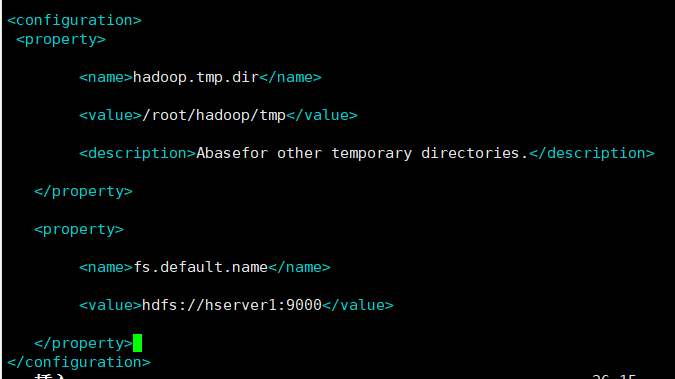
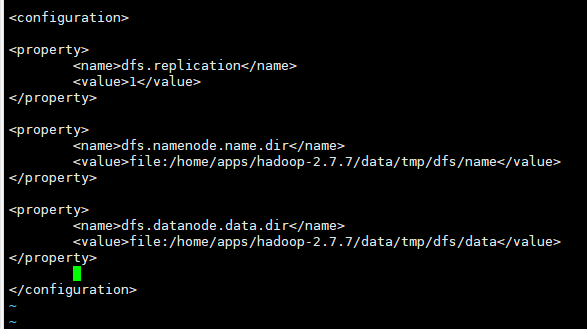
3.配置hdfs-site.xml
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/apps/hadoop-2.7.7/data/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/apps/hadoop-2.7.7/data/tmp/dfs/data</value>
</property>
4.配置mapred-site.xml
cp -i mapred-site.xml.template mapred-site.xml

vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>tang1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>tang1:19888</value>
</property>
tang1为主节点主机名
5.配置slaves
vi slaves
hadoop1 #主节点
hadoop2 #从节点
hadoop3 #从节点
6.拷贝hdoop到从节点
scp -r 地址/hadoop** **:/地址

三.启动Hadoop
1.格式化
hdfs namenode -format
启动Hadoop所有进程。
start-all.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号