浅谈树链剖分
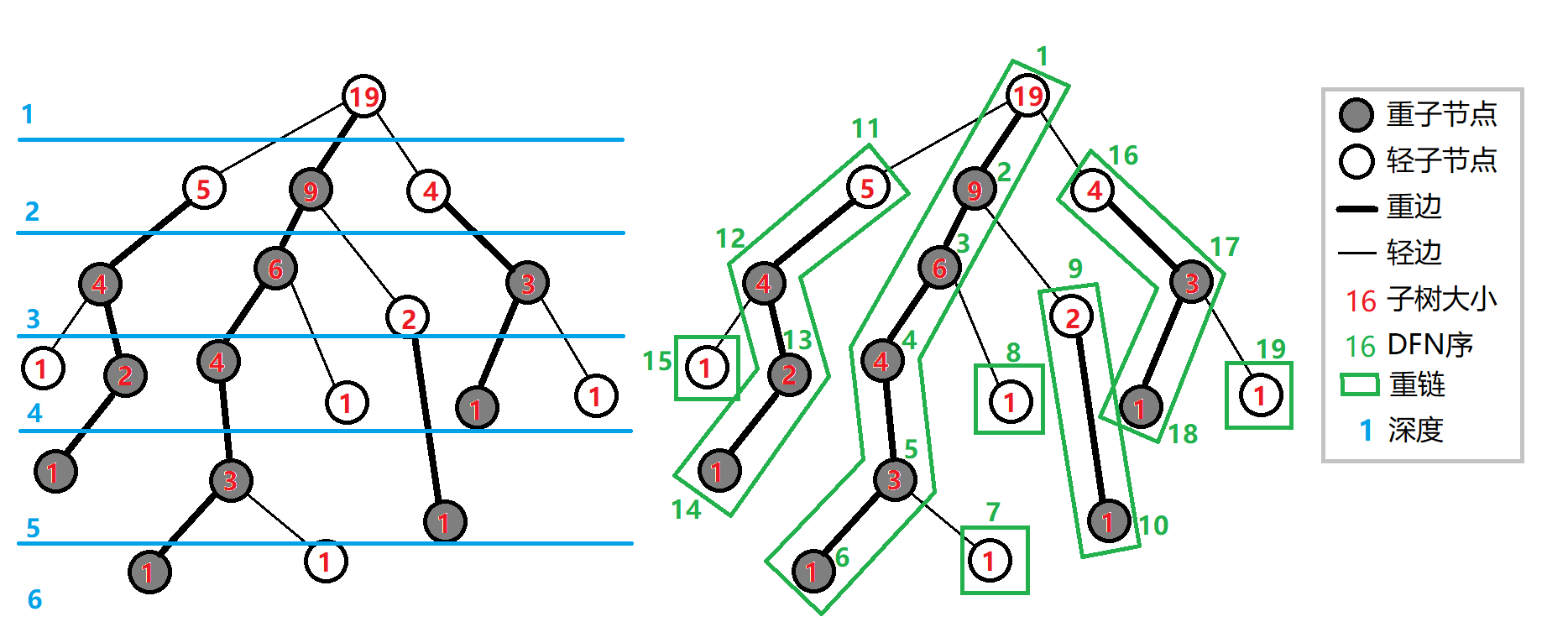
重链剖分
用途
- 路径上维护
- 子树维护
- 求最近公共祖先(LCA)
- 重剖的性质:
- 树上每个节点都属于且仅属于一条重链。
- 在剖分时 重边优先遍历,最后树的 DFS 序上,重链内的 DFS 序是连续的。按 DFN 排序后的序列即为剖分后的链。
定义
- 重儿子:对于每一个非叶子节点,它的儿子中以那个儿子为根的子树节点数最大的儿子为该节点的重儿子
- 轻儿子:对于每一个非叶子节点,它的儿子中 非重儿子 的剩下所有儿子即为轻儿子
- 叶子节点没有重儿子也没有轻儿子
- 重边:一个父亲连接他的重儿子的边称为重边
- 轻边:剩下的即为轻边
- 重链:相邻重边连起来的 连接一条重儿子 的链叫重链
- 对于叶子节点,若其为轻儿子,则有一条以自己为起点的长度为1的链
- 每一条重链以轻儿子为起点
两遍搜索
-
第一遍搜索
需要处理的数组
- 标记每个点的深度
dep[i] - 标记每个点的父亲
fa[i] - 标记每个非叶子节点的子树大小
size[i](含它自己) - 标记每个非叶子节点的重儿子编号
son[i]
inline void dfs1(int x,int f) { dep[x]=dep[f]+1;//标记深度 fa[x]=f;//标记父亲结点 siz[x]=1;//初始化字数大小 int hs=-1;//heavy son 重儿子子树内节点个数(包含 x ) for(int i=head[x];i;i=e[i].nxt) { int y=e[i].v; if(y==fa)continue; dfs(y,x); siz[x]+=siz[y]; if(siz[y]>hs)son[x]=y,hs=siz[y];//找重儿子 } } - 标记每个点的深度
-
第二遍搜索
需要处理的事情
- 标记每个点的新编号
id[i] - 赋值每个点的初始值到新编号
w[i]上 - 处理每个点所在链的顶端
top[i] - 处理每条链
inline void dfs2(int x,int h) { id[x]=++cnt;//标记每个点的新编号 w[cnt]=a[x];//赋值每个点的初始值到新编号上 top[x]=h;//处理每个点所在链的顶端 if(!son[x])return;//没有儿子,返回!!! dfs2(son[x],h);//由于需要重边优先遍历,所以先遍历重边 for(int i=head[x];i;i=e[i].nxt) { int y=e[i].v; if(y==fa[x]||y==son[x])continue; dfs(y,y);//考虑一条轻边组成的链只能由自己作为链的开始 } } - 标记每个点的新编号
求最近公共祖先
不断向上跳重链,当跳到同一条重链上时,深度较小的结点即为 LCA。
向上跳重链时需要先跳所在重链顶端深度较大的那个。
inline int lca(int u,int v)
{
while(top[u] != top[v])
{ //如果不在同一条链,就不断让深度更深的点跳到链头的父亲结点处
if(dep[top[u]]>dep[top[v]]) u=fa[top[u]];
else v=fa[top[v]];
}
return dep[u] > dep[v] ? v : u;//返回深度更浅的一个点
}
时间复杂度:\(O(\log_2{n})\)
复杂度证明:
可以发现,当我们向下经过一条 轻边 时,所在子树的大小至少会除以二(因该很显然易见吧,因为在只有一条重边和一条轻边:通过重边的定义,我们知道以重儿子为根的子树结点数一定大于以轻儿子为根子树结点数。如果有更多轻边,子树大小只会变小)。
因此,对于树上的任意一条路径,把它拆分成从 LCA 分别向两边往下走,分别最多走 \(log_2n\) 次,因此,树上的每条路径都可以被拆分成不超过 \(\log_2n\) 条重链。
路径上维护
维护路径和与修改树上路径。
因为链上的 DFS 序是连续的,所以可以使用线段树、树状数组维护。
当我们要处理任意两点间路径时:
设所在链顶端的深度更深的那个点为 \(x\) 点
- \(ans\) 加上 \(x\) 点到 \(x\) 所在链顶端 这一段区间的点权和
- 把 \(x\) 跳到 \(x\) 所在链顶端的那个点的上面一个点
不停执行这两个步骤,直到两个点处于一条链上,这时再加上此时两个点的区间和。
子树维护
有时会要求,维护子树上的信息。
将以 \(x\) 为根的子树的所有结点的权值增加 \(v\) 。
在 DFS 搜索的时候,子树中的结点的 DFS 序 \([id[x],id[x]+siz[x]-1]\) 是连续的。
每一个结点记录所在子树连续区间末端的结点,这样就把子树信息转化为连续的一段区间信息,也就用线段树或树状数组维护啦。。。
模板代码
#include <bits/stdc++.h>
using namespace std;
#define ls (x<<1)
#define rs ((x<<1)|1)
const int N=1e5+5;
int n,m,rt,p,tt[N],a[N];
struct edge
{
int v,nxt;
}e[N<<2];
int et=0,head[N],son[N],siz[N],dep[N],fa[N],cnt=0,top[N];
int id[N],len[N<<2];
inline void addedge(int u,int v)
{
et++;
e[et].v=v,e[et].nxt=head[u];
head[u]=et;
}
inline void dfs1(int x,int f)//第一次dfs
{
dep[x]=dep[f]+1;
fa[x]=f;
siz[x]=1;
int hs=-1;//heavy son
for(int i=head[x];i;i=e[i].nxt)
{
int y=e[i].v;
if(y==f)continue;
dfs1(y,x);
siz[x]+=siz[y];
if(siz[y]>hs)hs=siz[y],son[x]=y;
}
}
inline void dfs2(int x,int h)//第二次dfs
{
id[x]=++cnt;
a[cnt]=tt[x];
top[x]=h;
if(!son[x])return;
dfs2(son[x],h);
for(int i=head[x];i;i=e[i].nxt)
{
int y=e[i].v;
if(y==fa[x]||y==son[x])continue;
dfs2(y,y);
}
}
long long t[N<<2],lz[N<<2];
inline void build(int x,int l,int r)
{
len[x]=r-l+1;
lz[x]=0;
if(l==r)
{
t[x]=a[l];
return;
}
int mid=(l+r)>>1;
build(ls,l,mid);
build(rs,mid+1,r);
t[x]=(t[ls]+t[rs])%p;
}
inline void pd(int x)//下传
{
t[ls]+=lz[x]*len[ls];
lz[ls]+=lz[x];
t[rs]+=lz[x]*len[rs];
lz[rs]+=lz[x];
t[ls]%=p;
t[rs]%=p;
lz[x]=0;
}
inline void upd(int x,int l,int r,int L,int R,int k)
{
if(r<L||R<l)return;
if(L<=l&&r<=R)
{
t[x]+=k*(r-l+1);
lz[x]+=k;
return;
}
pd(x);
int mid=(l+r)>>1;
upd(ls,l,mid,L,R,k);
upd(rs,mid+1,r,L,R,k);
t[x]=(t[ls]+t[rs])%p;
}
inline int query(int x,int l,int r,int L,int R)
{
if(r<L||R<l)return 0;
if(L<=l&&r<=R)
{
return t[x]%p;
}
pd(x);
int mid=(l+r)>>1;
int res=0;
res=(res+query(ls,l,mid,L,R))%p;
res=(res+query(rs,mid+1,r,L,R))%p;
return res;
}
//-----------------------------------线段树
inline void add(int x,int y,int k)
{
k%=p;
while(top[x]!=top[y])
{
if(dep[top[x]]<dep[top[y]])swap(x,y);
upd(1,1,n,id[top[x]],id[x],k);
x=fa[top[x]];
}
if(dep[x]>dep[y])swap(x,y);
upd(1,1,n,id[x],id[y],k);
}
inline void add1(int x,int z)
{
upd(1,1,n,id[x],id[x]+siz[x]-1,z);
}
inline int ask(int x,int y)
{
int ans=0;
while(top[x]!=top[y])
{
if(dep[top[x]]<dep[top[y]])swap(x,y);
ans=(ans+query(1,1,n,id[top[x]],id[x]))%p;
x=fa[top[x]];
}
if(dep[x]>dep[y])swap(x,y);
ans=(ans+query(1,1,n,id[x],id[y]))%p;
return ans;
}
inline int ask1(int x)
{
return query(1,1,n,id[x],id[x]+siz[x]-1);
}
int main()
{
scanf("%d%d%d%d",&n,&m,&rt,&p);
for(int i=1;i<=n;i++)
{
scanf("%d",&tt[i]);
}
for(int i=1,u,v;i<n;i++)
{
scanf("%d%d",&u,&v);
addedge(u,v);
addedge(v,u);
}
dfs1(rt,0);
dfs2(rt,rt);
build(1,1,n);
for(int i=1,op,x,y,z;i<=m;i++)
{
scanf("%d%d",&op,&x);
if(op==1)
{
scanf("%d%d",&y,&z);
add(x,y,z);
}
if(op==2)
{
scanf("%d",&y);
cout<<ask(x,y)<<'\n';
}
if(op==3)
{
scanf("%d",&z);
add1(x,z);
}
if(op==4)
{
cout<<ask1(x)<<'\n';
}
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号