
rabbitmq简述
MQ定义
消息队列的目的是为了实现各个应用程序之间的通讯, 应用程序基于MQ实现消息的发送和接收, 实现应用程序之间的通讯。这样多个应用程序可以运行在不同的主机上, 通过MQ就可以实现跨网络的通信, 因此MQ实现了业务的解耦和异步机制
MQ使用场合
1. 削峰填谷: 主要解决瞬时写压力大于应用程序处理能力, 导致消息丢失, 系统崩溃等问题2. 系统解耦: 解决不同重要程度, 不同能力级别系统之间依赖, 避免一死全死3. 蓄流压测: 线上有些链路不好压测, 可以通过在MQ中堆积一定量消息, 再放开来压测
RabbitMQ简介
RabbitMQ 采用 Erlang 语言开发,Erlang 语言由 Ericson 设计,Erlang 在分布式编程和故障恢复方面表现出色,电信领域被广泛使用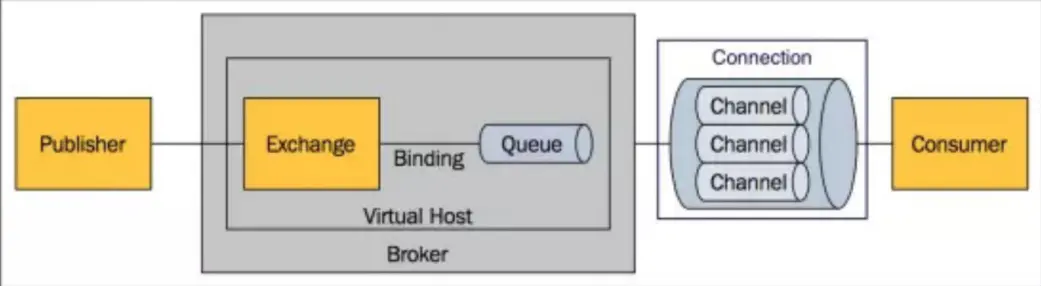
-
Broker: 接收和分发消息的应用,一个RabbitMQ Server 就是 Message Broker。
-
Virtual host: 出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类似于网络中的 namespace 概念,当多个不同的用户使用同一个RabbitMQ server 提供的服务时,可以划分出多个 vhost,每个用户在自己的 vhost创建 exchange/queue 等。通常每个业务会有一套RabbitMQ服务器, 因此, 一般RabbitMQ不会混用. 即使多套业务使用同一个RabbitMQ, 只要队列不冲突即可
-
Connection: publisher/consumer 和 broker 之间的 TCP 连接。Channel: 如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大时建立 TCPConnection 的开销将是巨大的,效率也较低。Channel 是在 connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个 thread 创建单独的channel 进行通讯,AMQP method 包含了 channel id 帮助客户端和 message broker识别 channel,所以 channel 之间是完全隔离的。Channel 作为轻量级的 Connection极大减少了操作系统建立 TCP connection 的开销。
-
Exchange: message 到达 broker 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到 queue 中去。常用的类型有:direct (point-to-point), topic (publishersubscribe) and fanout (multicast)。
-
Queue: 消息最终被送到这里等待 consumer 取走。Binding: exchange 和 queue 之间的虚拟连接,binding 中可以包含 routing key。
-
Binding 信息被保存到 exchange 中的查询表中,用于 message 的分发依据
基于 erlang 语言开发,具有高并发优点、支持分布式
具有消息确认机制、消息持久化机制,消息可靠性和集群可靠性高
简单易用、运行稳定、跨平台、多语言
开源
Queue 的特性
消息基于先进先出的原则进行顺序消费
消息可以持久化到磁盘节点服务器
消息可以缓存到内存节点服务器提高性能
https://rabbitmq.com/install-generic-unix.html rabbitmq官网,注意rabbitmq和erlang版本要配套。采用的是3.9.15
https://rabbitmq.com/which-erlang.html rabbitmq和erlang版本配套关系
https://github.com/rabbitmq/erlang-rpm/releases erlang-rpm包地址,采用的是23.3.4.10
| c1(mq1) | 192.168.10.10 |
| c2(mq2) | 192.168.10.11 |
| c3(mq3) | 192.168.10.12 |
[root@c1 ~]# rpm -ivh erlang-23.3.4.10-1.el7.x86_64.rpm 安装erlang
[root@c1 src]# tar xf rabbitmq-server-generic-unix-3.9.15.tar.xz -C /usr/local 解压二进制包到/usr/local
[root@c1 ~]#ln -sv rabbitmq_server-3.9.15/ rabbitmq_server 创建软链接,方便后续升级
[root@c1 src]# ln -sv /usr/local/rabbitmq_server/sbin/* /usr/bin 创建软链接,直接使用命令
[root@c1 ~]#rabbitmq-server -detached 后台启动
[root@c1 ~]#rabbitmq-plugins enable rabbitmq_management 开启web界面
至此单机节点完成
---------------------------------------------------------
5672: 消费者访问的端口 15672: web管理端口 25672: 集群状态通信端口
登录web界面,rabbitmq从3.3.0开始, 禁止使用guest/guest权限通过除localhost外的访问, 直接访问报错如下
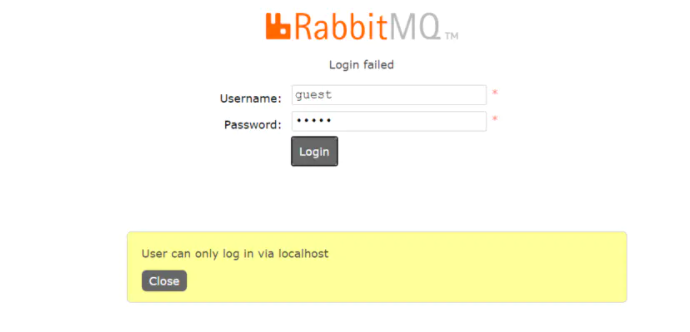
1修改配置文件
[root@c1 src]# find /usr/local -name 'rabbit.app'
/usr/local/rabbitmq_server-3.9.15/plugins/rabbit-3.9.15/ebin/rabbit.app
[root@c1 src]#vim /usr/local/rabbitmq_server-3.9.15/plugins/rabbit-3.9.15/ebin/rabbit.app
37 {default_user_tags, [administrator]},
38 {default_vhost, <<"/">>},
39 {default_permissions, [<<".*">>, <<".*">>, <<".*">>]},
40 {loopback_users, []}, 修改此行,把guest去掉
41 {password_hashing_module, rabbit_password_hashing_sha256},
42 {server_properties, []},
2重启服务
[root@c1 src]#rabbitmqctl stop
[root@c1 src]#rabbitmq-server -detached
集群部署
所有节点都要进行以下操作
1
[root@c1 ~]#rpm -ivh erlang-23.3.4.10-1.el7.x86_64.rpm
[root@c1 ~]#tar xf rabbitmq-server-generic-unix-3.9.15.tar.xz -C /usr/local
[root@c1 ~]#ln -sv rabbitmq_server-3.9.15/ rabbitmq_server
[root@c1 ~]#ln -sv /usr/local/rabbitmq_server/sbin/* /usr/bin
[root@c1 ~]#rabbitmq-server -detached
[root@c1 ~]#rabbitmq-plugins enable rabbitmq_management
2每个节点都要配置hosts文件,因为mq是通过主机名解析的
[root@c1 src]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.10 c1
192.168.10.11 c2
192.168.10.12 c3
3同步cookie
RabbitMQ的集群是依赖于Erlang的集群来工作的, 所以必须先构建起Erlang的集群环境, 而Erlang的集群中,各节点是通过一个magic cookie来实现的, 如果是apt安装的RabbitMQ, 这个cookie存放在/var/lib/rabbitmq/.erlang.cookie中, 文件是400权限, 所以必须保证各节点cookie保持一致, 否则节点之间就无法通信
cookie文件会在安装RabbitMQ是自动创建, 但是cookie内容是随机的, 因此要确保集群之间一致, 可以关闭所有RabbitMQ服务后, 将cookie文件从一个节点, 拷贝到其余节点, 实现统一
[root@c1 src]# find / -name ".erlang.cookie"
/root/.erlang.cookie
[root@c1 src]# rabbitmqctl stop
[root@c2 src]# rabbitmqctl stop
[root@c3 src]# rabbitmqctl stop
[root@c1 src]# scp /root/.erlang.cookie 192.168.10.11:/root/
[root@c1 src]# scp /root/.erlang.cookie 192.168.10.12:/root/
[root@c1 src]# rabbitmqctl start
[root@c2 src]# rabbitmqctl start
[root@c3 src]# rabbitmqctl start
4 将c2和c3加入到c1的集群中,集群可以在任何节点执行。要停止节点的app服务,清空元数据
[root@c2 src]#rabbitmqctl stop_app
[root@c2 src]#rabbitmqctl reset
[root@c2 src]#rabbitmqctl join_cluster rabbit@c1 --ram 以内存的形式加入[root@c3 src]#rabbitmqctl stop_app
[root@c3 src]#rabbitmqctl reset
[root@c3 src]#rabbitmqctl join_cluster rabbit@c1 --ram 以内存的形式加入[root@c3 src]#rabbitmqctl start_app
[root@c2 local]# rabbitmqctl cluster_status
Cluster status of node rabbit@c2 ...
Basics
Cluster name: rabbit@c2
Disk Nodes
rabbit@c1 磁盘形式,相当于数据保存在磁盘上
RAM Nodes
rabbit@c2 内存形式,数据在内存上
rabbit@c3
Running Nodes
rabbit@c1
rabbit@c2
rabbit@c3
Versions
rabbit@c1: RabbitMQ 3.9.15 on Erlang 23.3.4.10
rabbit@c2: RabbitMQ 3.9.15 on Erlang 23.3.4.10
rabbit@c3: RabbitMQ 3.9.15 on Erlang 23.3.4.10
Maintenance status
Node: rabbit@c1, status: not under maintenance
Node: rabbit@c2, status: not under maintenance
Node: rabbit@c3, status: not under maintenance
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@c1, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@c1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@c1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@c2, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@c2, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@c2, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@c3, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@c3, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@c3, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Feature flags
Flag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: stream_queue, state: enabled
Flag: user_limits, state: enabled
Flag: virtual_host_metadata, state: enabled
6设置成镜像模式,在任意一个节点执行就行。相当于任何一个节点都会进行数据同步
[root@c1:~]# rabbitmqctl set_policy ha-all "#" '{"ha-mode":"all"}'
7登录web界面
![]()
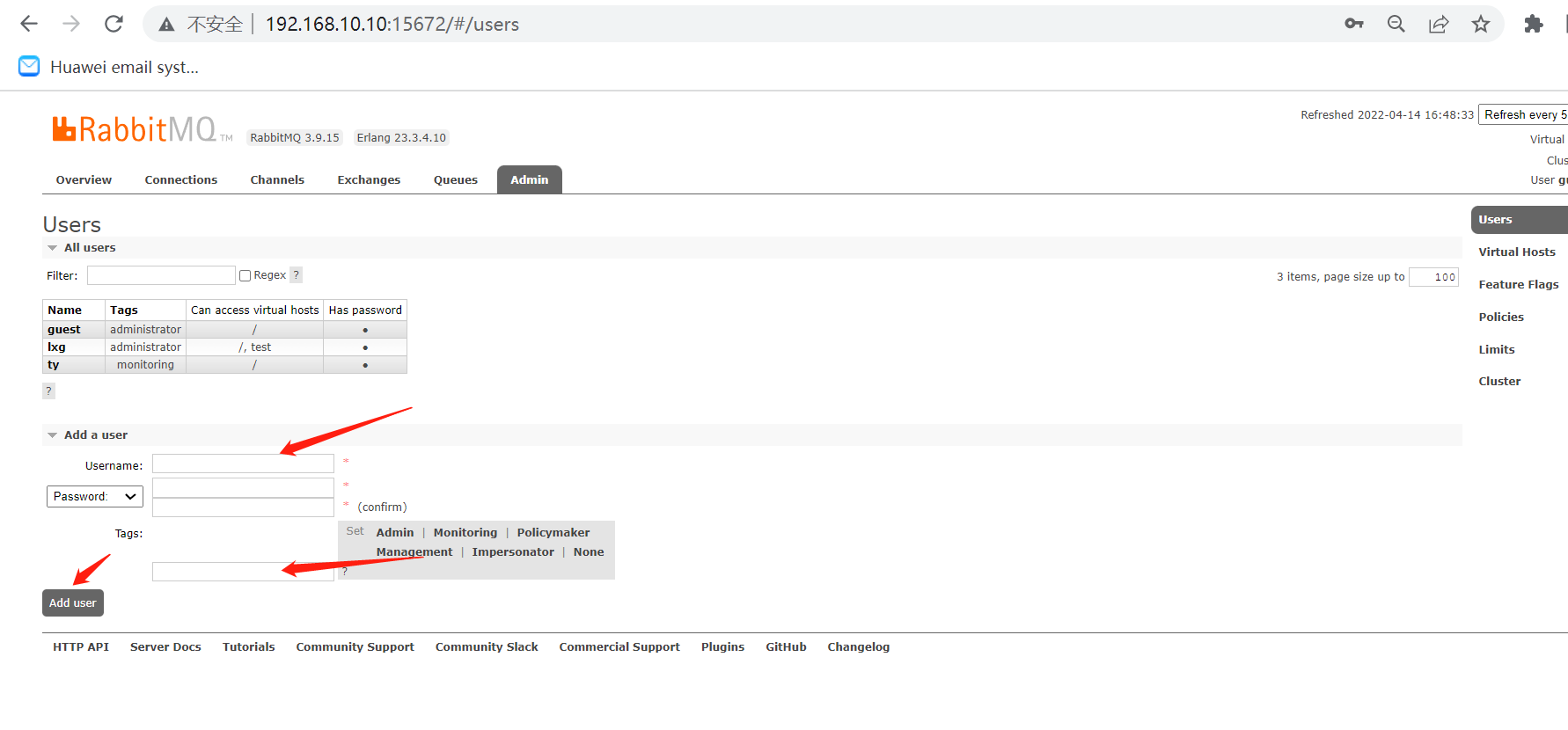
9监控集群状态脚本
#!/usr/bin/python3 #coding:utf-8 import subprocess running_list = [] error_list = [] false = "false" true = "true" def get_status(): obj = subprocess.Popen(("curl -s -u guest:guest http://localhost:15672/api/nodes &> /dev/null"), shell=True,stdout=subprocess.PIPE) data = obj.stdout.read() data1 = eval(data) for i in data1: if i.get("running") == "true": running_list.append(i.get("name")) else: error_list.append(i.get("name")) def count_server(): if len(running_list) < 3: # 可以判断错误列表大于 0 或者运行列表小于 3,3为总计的节点数量 print(100) # 100 就是集群内有节点运行不正常了 else: print(50) # 50 为所有节点全部运行正常 def main(): get_status() count_server() if __name__ == "__main__": main()
10生产写入数据脚本
#!/usr/bin/python3
#coding:utf-8 import pika #RabbitMQ用户名密码 cert = pika.PlainCredentials("lxg","123456") #连接到服务器 conn = pika.BlockingConnection(pika.ConnectionParameters("192.168.10.10",5672,"/",cert)) #创建频道 channel = conn.channel() #声明消息队列,如果不存在就创建, 存在就将消息在此队列中创建, 如果将消息发送到不存在的队列, 则RabbitMQ会自动清除这些消息 channel.queue_declare(queue="helloworld") #exchange告诉消息去往的队列, routing key是队列名, body是要传递的消息内容 for i in range(10000): #通过循环写入1万条消息 # num = "%s" % i channel.basic_publish(exchange="", routing_key="helloworld", body="hello world %d!" % i) print("消息%s写入成功!" % i) #消息写入完成,关闭连接 conn.close()
#!/usr/bin/python3
#coding:utf-8 import pika #RabbitMQ用户名密码 cert = pika.PlainCredentials("admin","admin") #连接到服务器 conn = pika.BlockingConnection(pika.ConnectionParameters("192.168.10.12",5672,"/",cert)) #创建频道 channel = conn.channel() #声明消息队列,如果不存在就创建 channel.queue_declare(queue="helloworld") #定义一个回调函数, 将信息打印出来 def callback(ch,method,properties,body): print("[x] Received %r" % body) channel.basic_consume("helloworld",callback, auto_ack=False, exclusive=False, consumer_tag=None, arguments=None) print(" [*] Waiting for messages. To exit press CTRL+C") #开始接收消息, 并进入阻塞状态, 队列里有信息才会调用callback进行处理, 按ctrl+c退出 channel.start_consuming()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号