腾讯 AICR : 智能化代码评审技术探索与应用实践(下)
上文概要
上篇文章,我们介绍了腾讯基于 AI 大模型完成了智能代码评审( AICR)的大规模落地与实践,为数万腾讯开发者提供了生成摘要、发现代码问题、生成评审意见与修复建议等能力,大大提升了评审效率与代码质量。本篇将为你分享腾讯 AICR 建设过程遇到的技术挑战以及解决方案。
技术挑战
在真实落地过程中,我们面临了大量挑战,主要为三点:
挑战一 高质量的 CR 数据更难获取
代码评审过程中,主要涉及三种类型数据,即:代码、代码变更、代码评论。它们各自特点如下:
代码:数据完整、高度结构化、语法特征清晰、无二义性,解析工具成熟,例如:基于 tree-sitter 的 AST 解析等
代码变更:数据碎片化,包含代码演化信息,解析工具较为成熟,例如:GumTree,ClDiff等
代码评论:自然语言形式,结构松散,有二义性,解析工具较少
相较于代码补全生成等代码大模型的生成任务而言,代码评审所涉及的数据类型更丰富、更复杂,也更加难获取与处理;
挑战二 CR 需要更高层次的领域知识
高质量的 CR 需具备特定的领域知识和业务背景,不同的业务团队对 CR 规范可能不同,难以泛化。
挑战三 大模型的 CR 能力难以评估
CR 的概念宽泛,涉及评审范围广,在评估大模型的 CR 能力时,由于 CR 天然的主观特性,对 CR 模型的生成效果判断难以量化,结果偏向主观性。
CR模型实践
构造高质量 CR 模型数据
如上所述,CR 的高质量数据相较于其他代码数据而言,更加难以获取与构造。首先,我们分析一下开源社区中的 CR 数据现状。如图所示,开源社区的代码评审数据一般为开发人员之间的对话流,第一、评论格式为自然语言的对话流,存在严重口语化与逻辑链条缺失等问题;其次,开源社区的评论需要结合上下文进行理解,包括代码的上下文以及项目背景知识;最后,开源社区的 CR 数据缺少有效的评审信息,夹杂大量的类似“问询”或“社交”等噪音数据。

而在大模型的精调训练中,对于精调数据的质量有很高的要求,一般而言,结构化特征越明显的高质量数据更易被模型所理解,而松散、低质量的训练数据难以激发模型在特定任务上的泛化能力。
因此,我们将开源 CR 数据的质量提升等价为一个文本总结任务。如图所示,我们首先通过数据爬取的手段获得代码评论对话流以及对应的代码提交,然后通过补全代码上下文,输入到大模型中,最后,通过大模型进行文本总结,得到结构化的 CR 数据。

在构造高质量 CR 训练数据过程中,我们发现,使用思维链可显著提升模型表现。具体地,大模型总结 CR 数据的 prompt 的思维链遵循的基本原则为:1)判断:是否存在代码问题;2)位置:代码问题在 diff 片段中的位置;3)问题:具体存在什么样的代码问题;4)修改:有什么修改建议。此外,除了需要遵循思维链格式外,prompt 中还加一些高质量的 CR 示例,通过优秀的 CR 案例,进一步提升大模型总结低质量 CR 数据的效果,从而获取高质量的 CR 训练数据;最终生成的 CR 训练数据的基本格式图所示:

私有业务领域的 CR 训练
如上所述,高质量 CR 需更高层次的领域知识。本质上 CR 是极其专业的知识密集型的 AIGC 任务。涉及的知识主要分为三类:
- 特定领域知识:指特定的业务项目知识或行业背景知识。如:游戏开发、社交领域、电商平台、网络通信、嵌入式开发等特定领域;
- 通用编程知识:指通用的编程相关知识。如:需求管理/分解、软件/架构设计、编程语法规则、代码重构/优化、缺陷/漏洞检测、最佳实践/规范等;
- 特定开发知识:指公司内部特定开发的知识。例如:内部的开发框架、内部的第三方库、团队的特定开发规范等;
在落地特定业务的 CR 时,需结合上述三类知识,然而,仍存在一些技术难点,包括:
- 由于特定业务的数据安全问题,因此,大模型训练中无法拿到私域数据进行预训练/微调;
- 特定业务有特定的业务规范,具备强烈的领域特性,如对每个业务进行模型定制化,则成本代价太大,且不利于模型更新迭代;
- 特定业务的 CR prompt 需扩充上下文,包括当前 CR 涉及的代码上下文和特定领域的业务知识,如缺乏相关上下文,则会导致大模型产生大量“幻觉”;
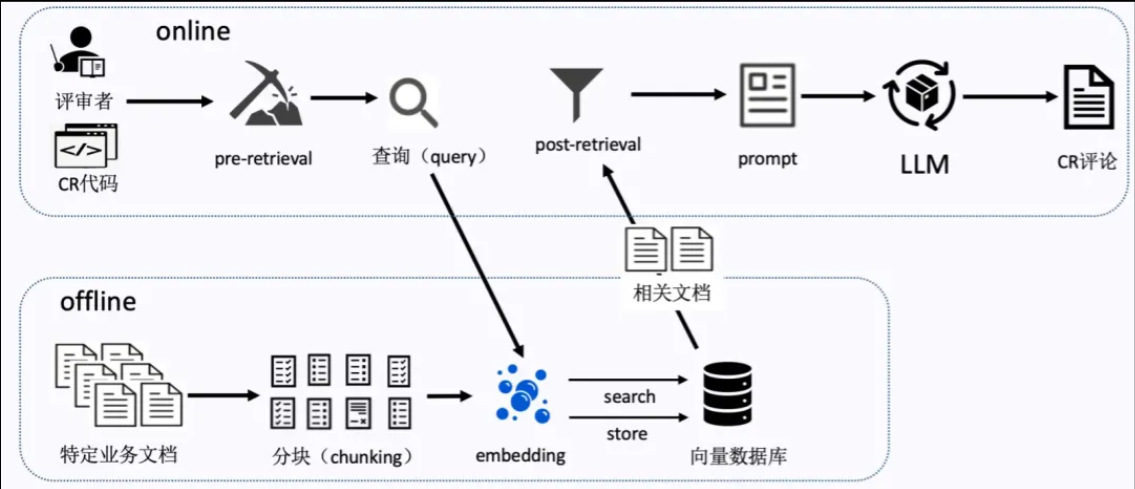
为解决上述难点,我们采用当前主流的 RAG 的技术手段提升特定业务的 CR 效果,具体流程如下图所示:
此外,为了更进一步地贴合具体业务的 CR 场景,我们对 CR 智能化模型进行微调对齐以及数据飞轮建设,具体流程如图所示:

首先,对 CR 模型进行 prompt 的调试,其中 prompt 包含基本格式和扩展格式。在基本格式中,要求指令要清晰并且遵循思维链,并且将待 CR 的代码块进行了基本的上下文处理,保证待 CR 的代码片段完整性;在扩展格式中,会对当前代码进行上下文的扩充,包括 RAG 知识库及代码分析搜索出的相关代码片段。
模型上线后,会建立用户反馈机制,收集用户反馈的 good/bad case,定期对 bad case 进行修复,包括对 bad case 进行分类和归因,通过数据迭代和优化,来减少 bad case 的产生。
对于模型微调,采用 SFT 的方式,进行指令对齐,其中,高质量的训练数据的数据量在 1k 到 3k 条不等,训练方式为全量微调或者 Lora 方式的微调。
智能化 CR 模型的评测
如上所述,由于代码评审天然存在主观性,因此在评价大模型的 CR 能力时,很难量化判断模型的生成效果。此外,由于代码评审涉及大量的其他相关概念,如,缺陷检测、漏洞扫描、编程规范等,因此,大模型的 CR 能力评测更加困难。为全面、客观、准确的评测 CR智能化模型的效果,我们构建了一个多级分类的评测集,如下图所示:
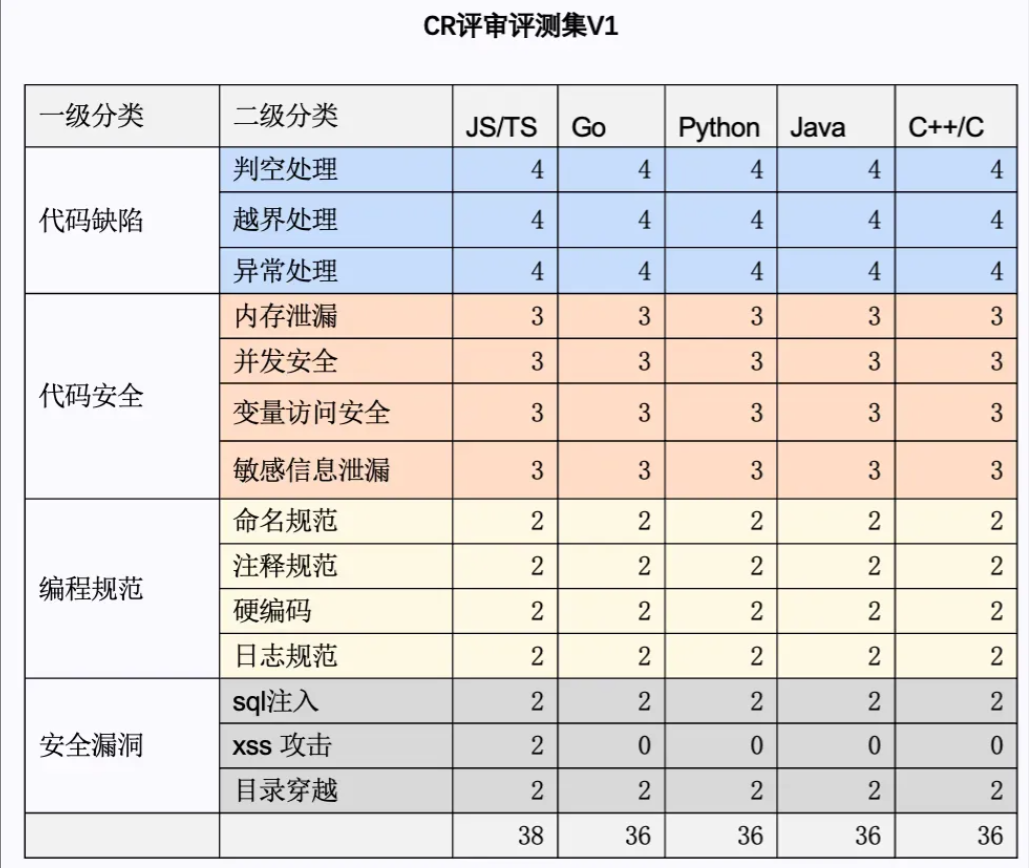
在评价模型 CR 能力时,会重点关注代码缺陷、代码安全、编程规范和安全漏洞的代码评审。其中,会对一级分类的 case 再进一步地细分二级分类,优先涵盖五大主流语言的评审 case。
此外,提出五档评分的评测法,具体五档评分(AICR 评测版)如下:
超出预期:在【复杂题目】上能生成完全覆盖参考答案的点,并给出正确合理分析和问题修复建议
满意:模型答案能完全覆盖参考答案中指出的问题,并给出正确合理分析
基本满意:模型答案命中参考答案,对于参考答案中指出的问题有遗漏,遗漏 <2 条,但给出了正确问题分析
不满意:模型答案未命中参考答案,或存在许多错误,或未按要求格式输出
不可接受:模型拒绝回答问题,或完全理解错题意,或给出了完全错误的分析
通过构建多级分类的评测集以及人工评测的五档评分法,可相对客观、全面准确的评测大模型的 CR 能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号