腾讯 AICR : 智能化代码评审技术探索与应用实践(上)
引言
基于大模型技术为 AI 智能代码评审(AI Code Review,以下简称 AICR)带来了新的机遇与挑战,腾讯 AI 代码助手团队和 CR 团队基于腾讯集团开发人员与腾讯云广大开发人员/企业客户的 MR/CR 场景 (MR: Merge Request;CR:Code Review),结合大模型技术推出了智能代码评审解决方案,包括基于 diff 片段、file 文件、edior 编辑文件的 AI 辅助评审、code suggestion、生成 MR commit message ,此外在腾讯集团内部还在源代码管理平台实践了基于 AI 实现 MR 摘要生成、智能评审意见生成、代码问题 AI评审修复意见生成等功能,全面助力广大开发人员提升评审效率和代码质量。
CR背景与挑战
CR背景
代码评审 (Code Review, 以下简称 CR) 是确保代码质量的重要途径之一。在软件开发过程中,尤其在大型开发团队开发过程,业务需求/问题修复的发布上线涉及多个开发人员的协作以及一套完整的版本管理质量保障体系,避免出现协作、代码风格等不一致带来的交付延期和代码质量影响。
通常,开发人员利用版本控制系统(如 Git)来减轻协作过程中出现的错误率和确保代码质量一致性,因此产生了分支管理,以 Gitflow workflow 分支管理规范为例,可看出研发协作过程是非常复杂的,伴随每次的业务需求开发、问题修复每次都会创建一个分支,每次分支间的合并都会产生一次合并请求,合并请求简称为 MR (Merge Request),在研发过程中高频的 MR 请求也就涉及到高频的 CR 需求。
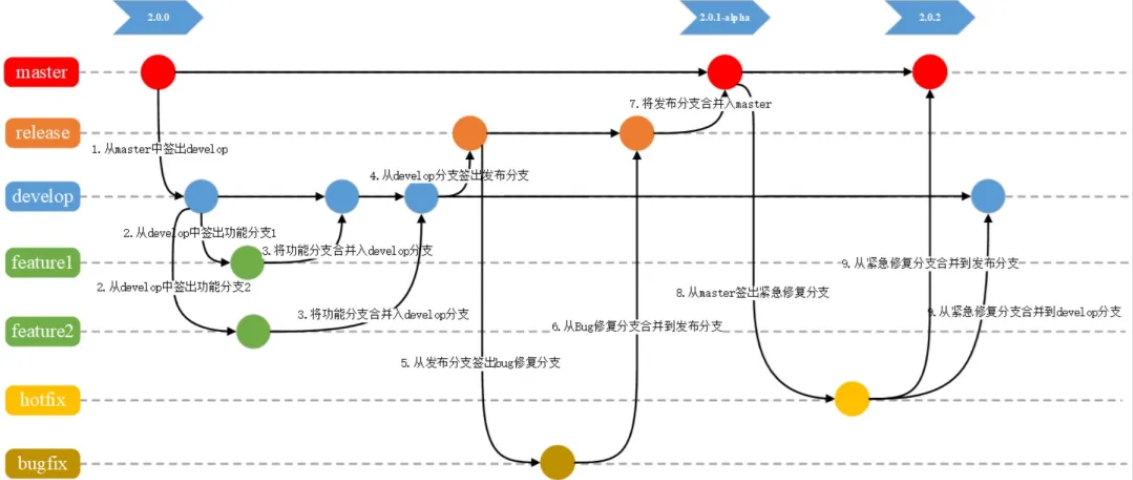
分支定义:分支可以被看作是项目历史的轻量级移动指针,也是开发人员编码内容的载体。当你创建一个分支时,Git 会创建一个新的指针指向当前分支的最新提交(commit)。之后,当你在这个新分支上进行提交时,这个分支的指针会向前移动,而其他分支的指针保持不变。
人工 CR 挑战
代码评审 (Code Review, CR) ,是软件开发过程中至关重要的一部分,是保障代码编码过程中最后一道质量保障, 传统人工 CR 流程。长期以来,频繁的 CR 以及沟通协作,造成评审低效且难把控,开发与评审者面临系列挑战,具体表现为:
- MR 评审描述不规范,出问题难追溯
- CR 不及时,需等待评审者时间,导致评审周期较长,会造成不必要的成本浪费
- CR 遗漏或难监管,缺乏有效评审机制监管
- 缺乏代码上下文信息或代码复杂,评审者难以理解,造成 CR 耗时耗力
- 频繁的 CR 或 单次 CR 内容多,存评审耗时和评审者疲劳,影响评审效率和质量
- 存覆盖面不足问题,如代码编码规范、代码设计逻辑、缺失注释说明、测试用例未覆盖及内存泄露等问题未覆盖全,导致 CR 质量低下
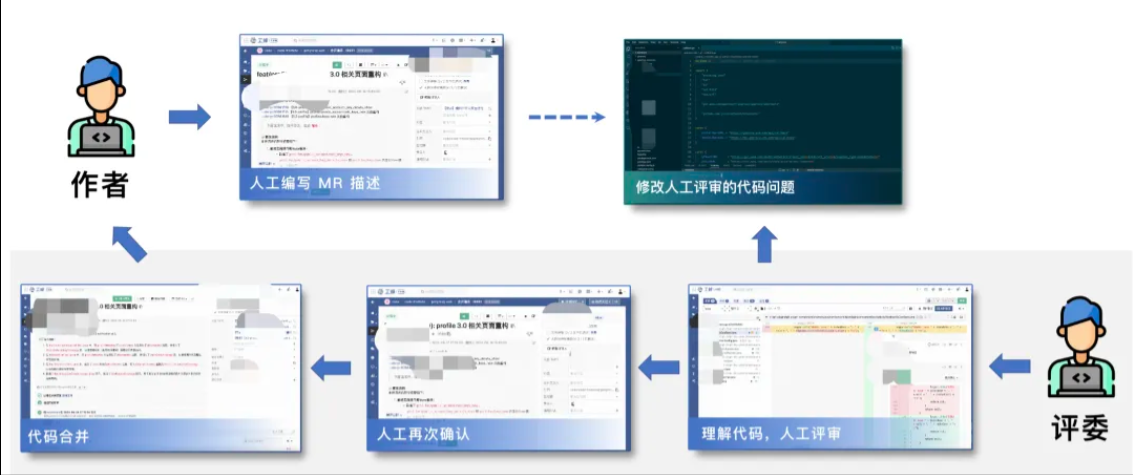
AICR介绍
结合大模型技术,将人工评审转为采用智能代码评审,通过 AICR 辅助评审,开发人员可快速识别和修复代码中的潜在代码质量问题,同时生成规范的合流 MR 摘要信息,为源代码管理和协作流程带来更高效的体验。
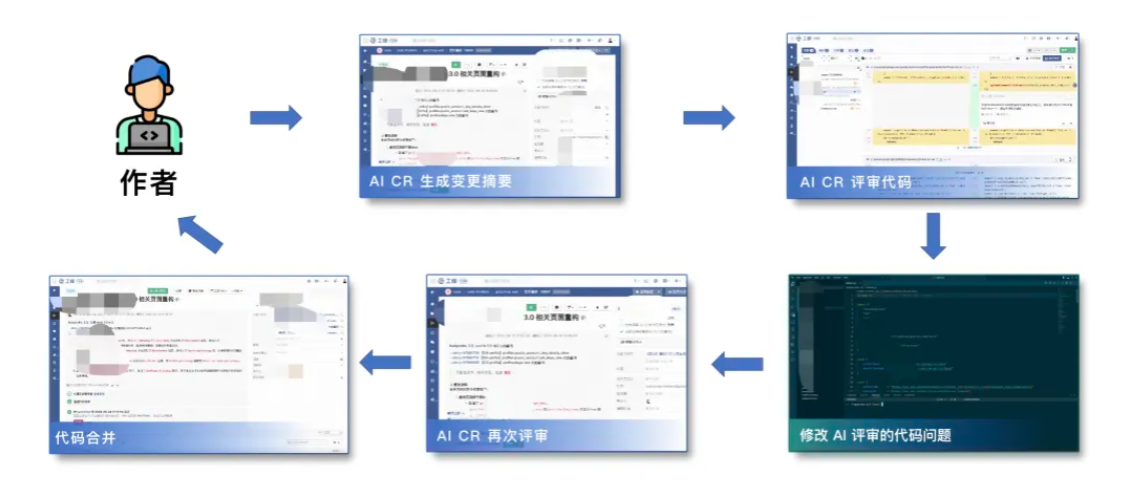
AICR 带来的高效体验,具有体现在以下方面:
- 随时自评审,无需等待,降低浪费
- 规范 MR 评审描述,评审者快速理解
- 降低人工频繁的 CR,提升评审效率和质量
- 评审更全面,提升评审覆盖面
- 提供修复建议,评审质量与解决问题有保障
- 具备 IDE / 代码仓库 两种场景评审,更全面
- 内置评审管理配置,可优先 AI 辅助评审
腾讯 AICR 落地方案
源起
自大模型时代的到来,及腾讯集团研发效能委员会对于 CR 的重视程度不断的提升,经调研,大量开发人员反馈花费在 CR 上的时间也逐渐的增多,在日常研发工作排期中,除原本的编码时间、联调时间之外,还需预留 CR 的时间。以 QQ 业务团队为例,效能平台数据显示,人均评审耗时高达 80 分钟,经采访调研验证该观点。
从 23年3月 开始,基于大模型的能力,腾讯集团 AI 代码助手团队和 CR 等团队,针对腾讯内外部开发人员进行调研,并针对编码场景进行了 AI 实践,其中 AICR 就是比较重要实践之一,并取得一定的效果。
技术方案
接下来,将具体介绍如何采用大模型相关技术解决上述挑战与问题。腾讯智能化 CR 服务的整体技术架构上分为三个层次:
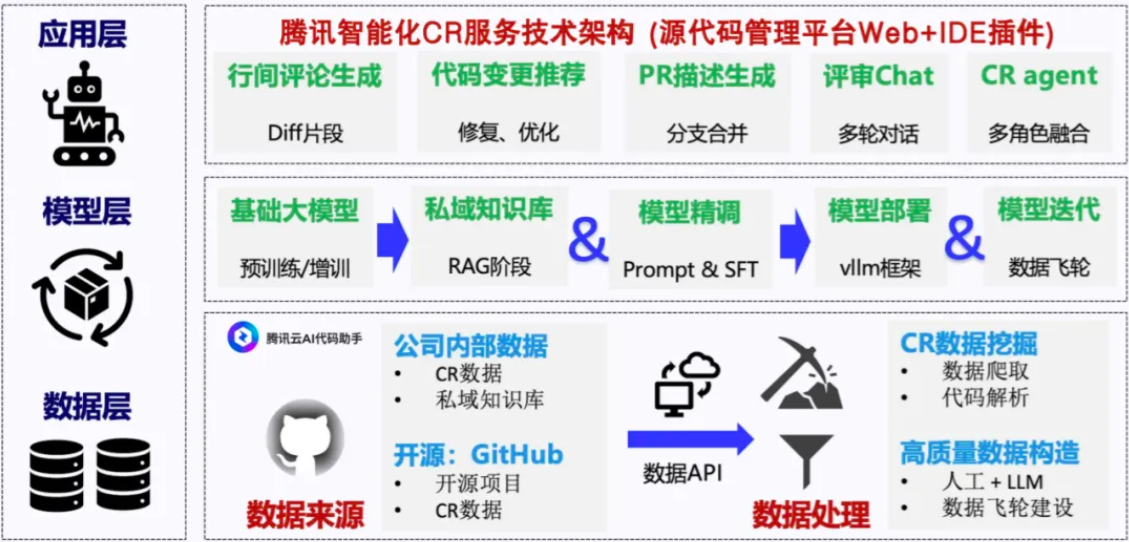
数据层:在数据层,主要工作为数据获取与数据处理。具体地,数据来源来自两个方面。一方面,从公司内部的开源项目中,收集了部分 CR 数据,以及和具体业务团队对接,收集私域数据;另一方面,主要数据来源来自外部开源的 CR 数据。在数据处理方面,我们会对 CR 数据进行挖掘清洗与解析处理,更进一步地,我们会基于大规模数据进行高质量训练数据的构造,其中构造方法包括人工标注、模型蒸馏和数据飞轮建设等;
模型层:在模型层,我们的主要工作为 RAG、模型精调对齐、模型部署与迭代等。在 RAG 阶段,我们收集私域数据进行 RAG 服务的建立;在模型精调阶段,主要采取 prompt 调试和模型 SFT 的方式进行模型对齐;在模型部署和迭代阶段,采用 vllm 的部署框架进行上线服务,获取真实的用户反馈,最后形成数据飞轮,完成模型迭代;
应用层:在应用层,我们的智能化 CR 服务的产品形态包括:源代码管理平台 Web (腾讯工蜂代码仓库)界面提供的 CR 界面和 IDE 中腾讯云 AI 代码助手插件侧屏的 chat 对话模式。目前上线服务包括:面向 diff 片段的 diff 行间评论生成、面相代码修复/优化的代码变更推荐、面向分支合并的 MR 描述生成、面向多角色融合的 CR agent 等。
核心功能使用指引
智能评审(AICR,AI Code Review)是腾讯云 AI 代码助手的一项功能,腾讯在 AICR 分 IDE 和代码仓库两种终端落地场景,其中在仓库端以腾讯源代码管理平台为例。
基于 IDE 指令/CR 场景评审
AI 辅助自评审
AICR 的 AI 辅助自评审功能分为片段评审、文件评审 和 批量评审,开发人员可以通过简单的指令 /cr# 触发不同的评审模式, 并进行代码审查
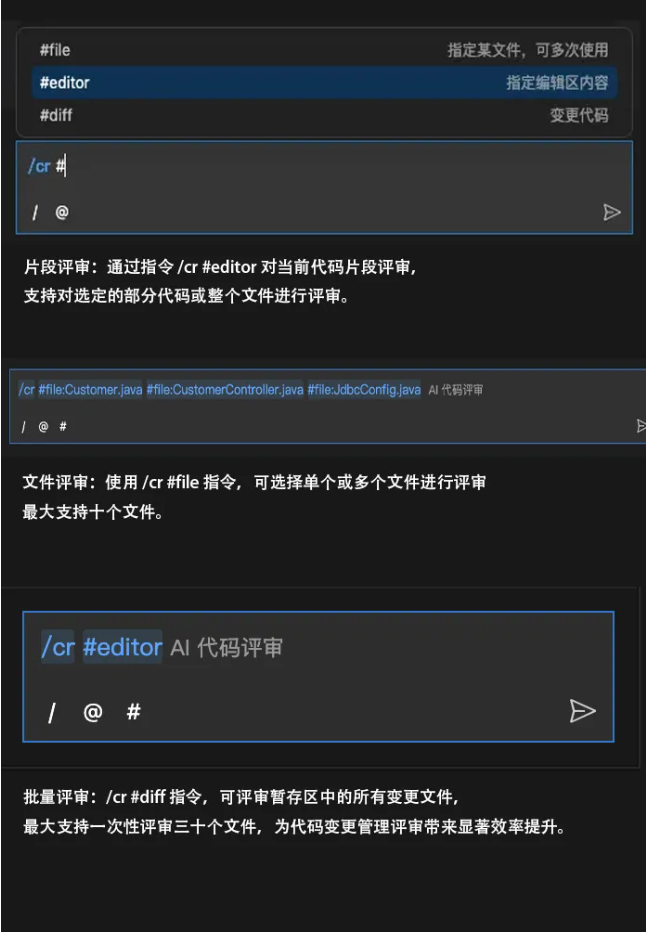
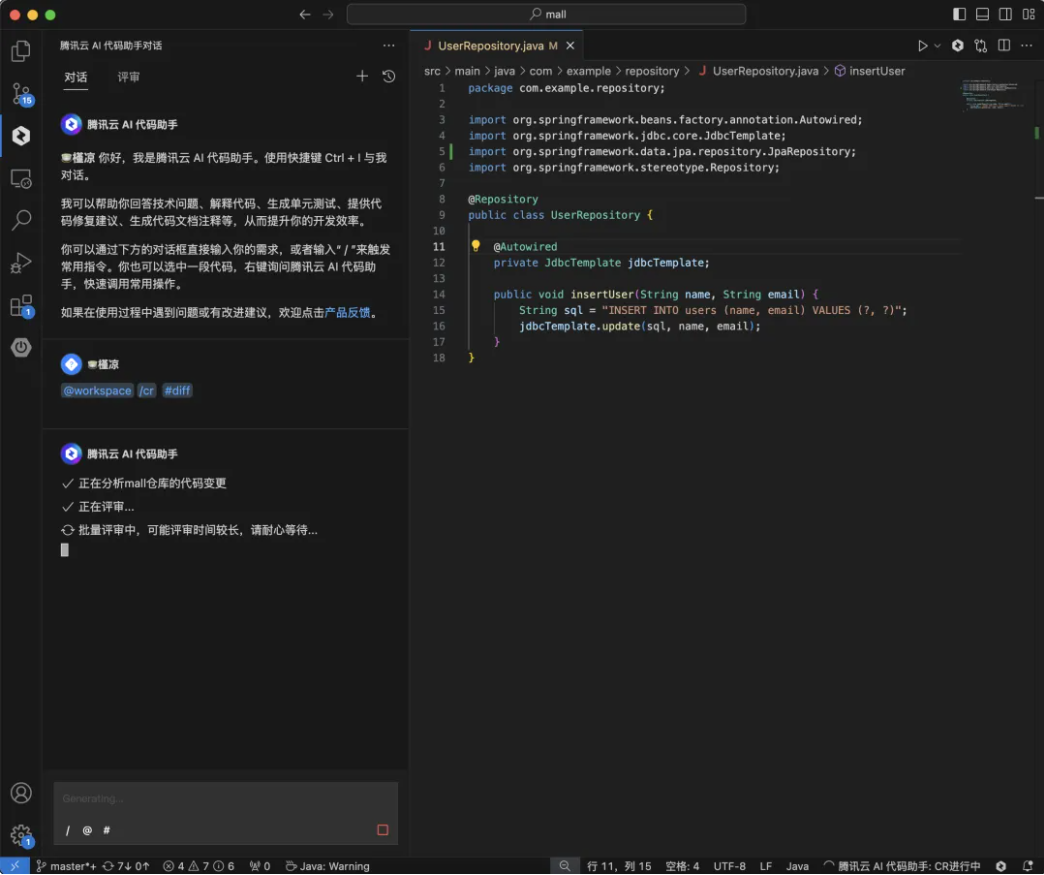
注意:评审执行中,会根据 # 选择的范围大小,会在对话框中有不同的评审过程的交互。在底部条有一个进行状态,当 #diff 的数量较多的时候,可能会有等待时间。你也可以继续当前工作,直到评审出结果后返回到 AI 代码助手对话中查看结果。
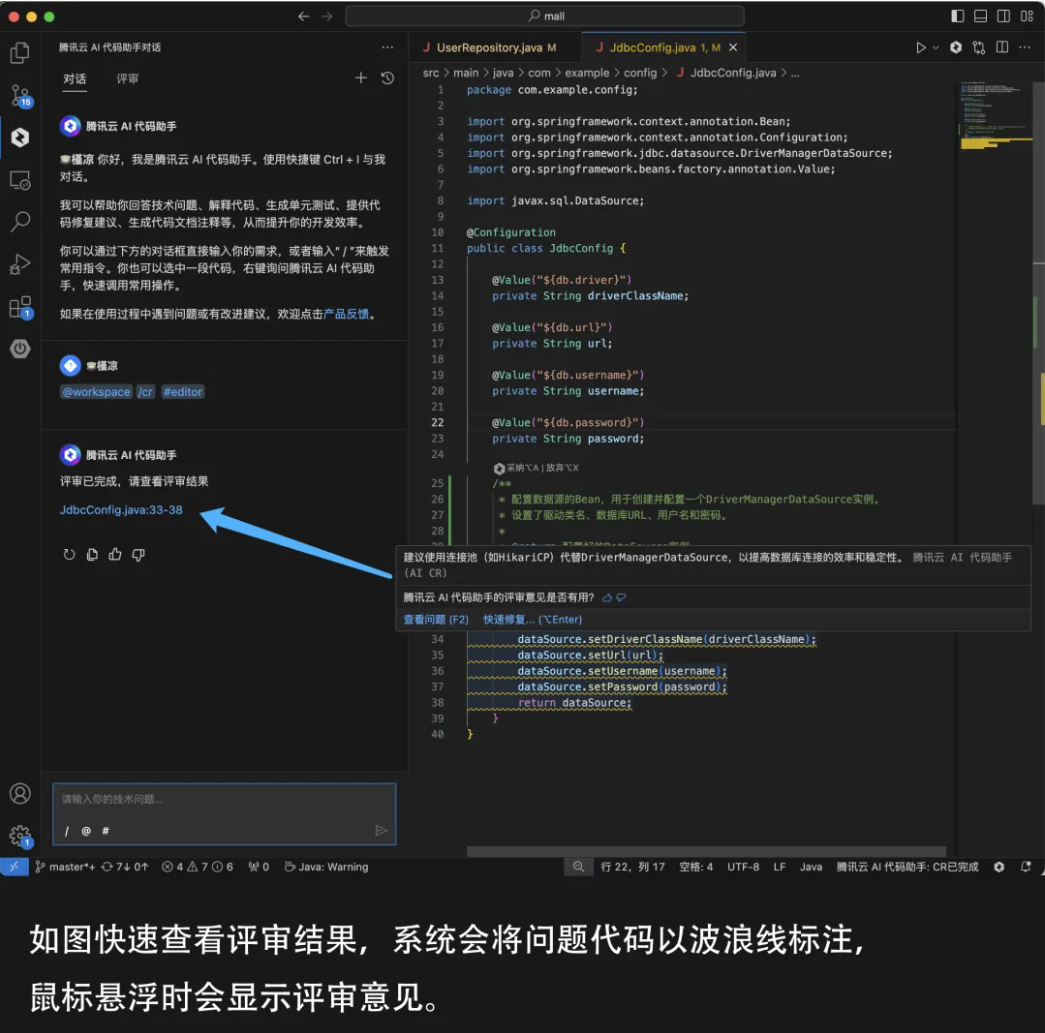
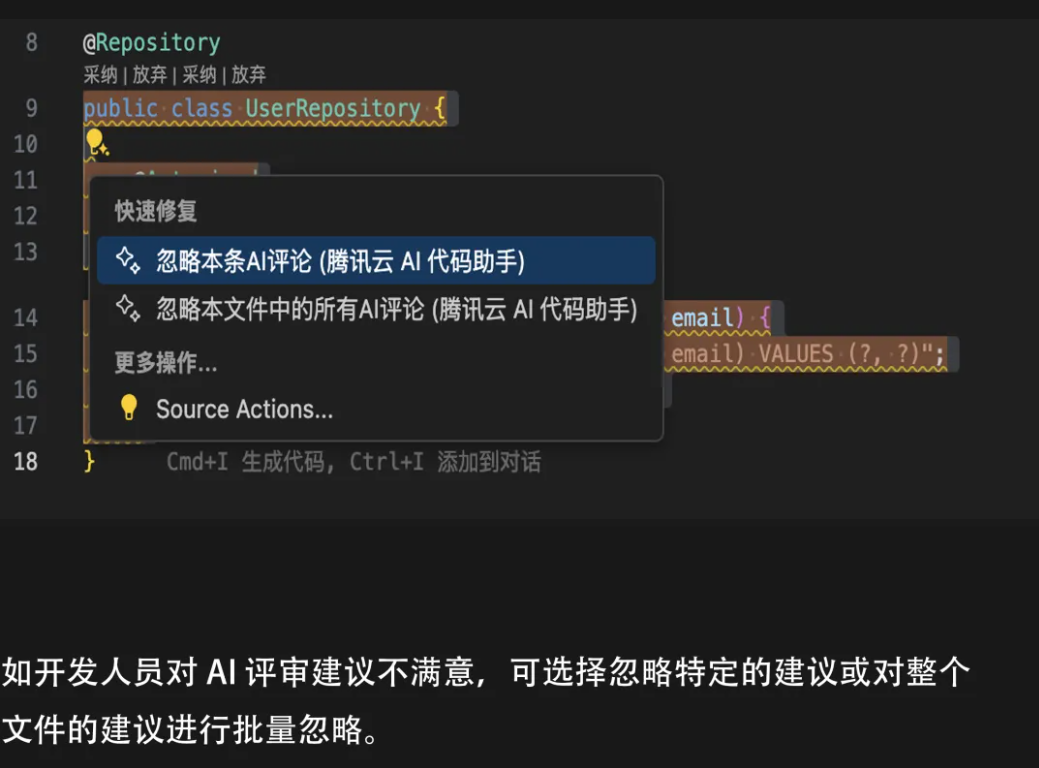
评审结果查看与管理

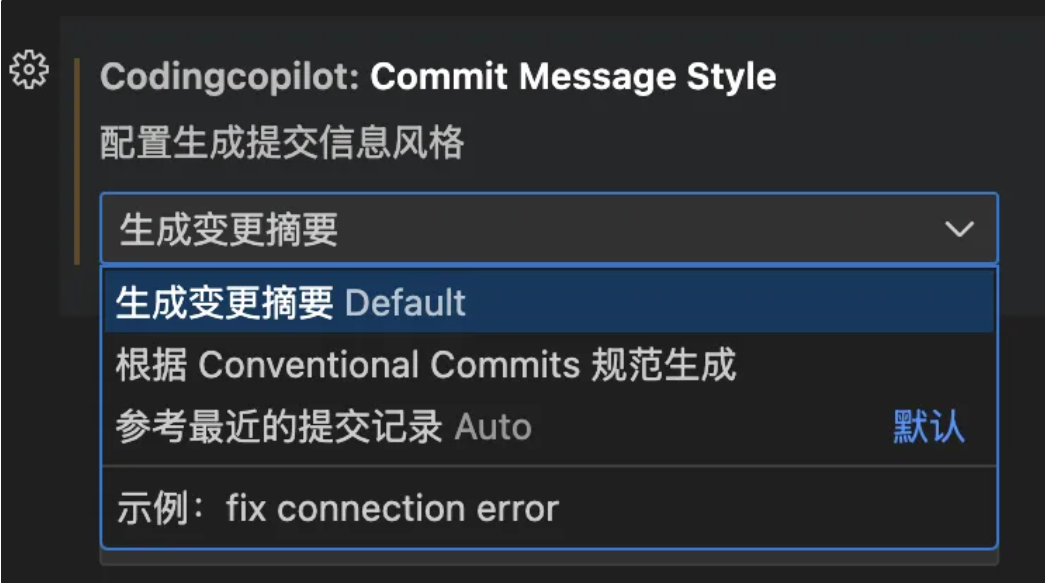
AI 提交信息生成
除 AICR ,代码助手还能够支持自动生成符合 Conventional 规范的 MR 提交信息。如图通过一键唤起 AI,AICR 可根据代码变更自动生成提交信息,确保 MR 提交信息的规范性和一致性,也节省大量时间。

集成源代码托管平台实现评审
此评审场景在源代码托管平台 Web 终端实现(以腾讯工蜂为例),以下是在腾讯集团实践和私有化交付场景集成解决方案,具体实现依赖客户源代码托管平台
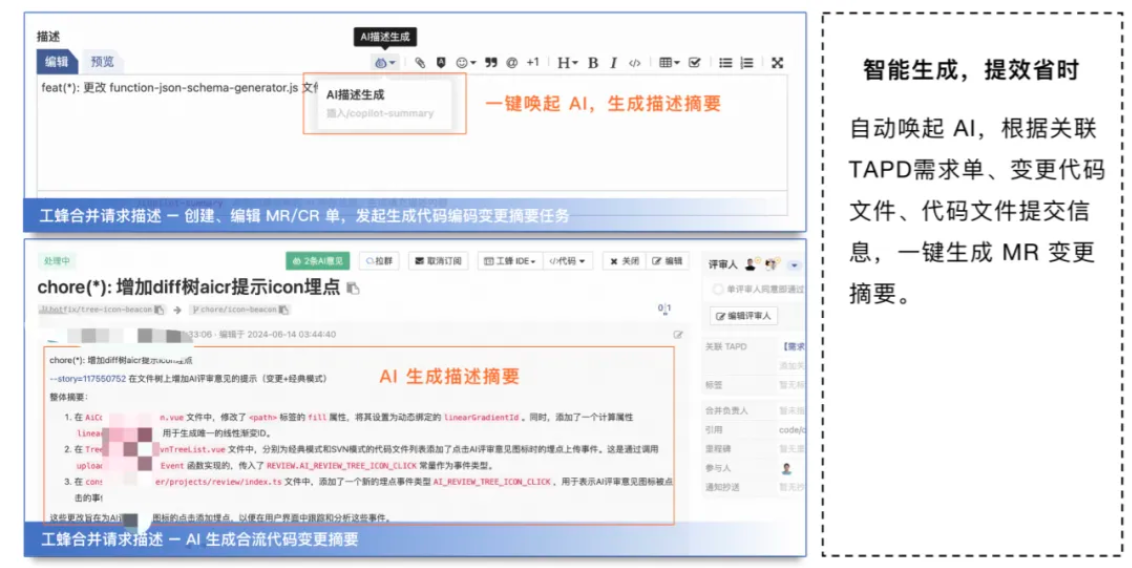
AI 一键生成合流 MR 生成摘要
将源代码托管平台 Web 与腾讯 TAPD 需求单/问题单、变更文件、提交信息关联,一键生成 MR 合流代码变更摘要,让评审者快速理解变更内容。
智能评审,提前识别错误
通过源代码托管平台 Web 端代码自动评审,识别问题,生成意见,可进行管理配置,与源代码托管平台形成无缝体验。

一键生成 AI 代码修复意见
在源代码托管平台 Web 端,CR 模型基于人工评论、代码上下文、一键生成 AI 代码修复建议。

AICR 优秀评审案例
代码缺陷:越界处理、内存泄漏


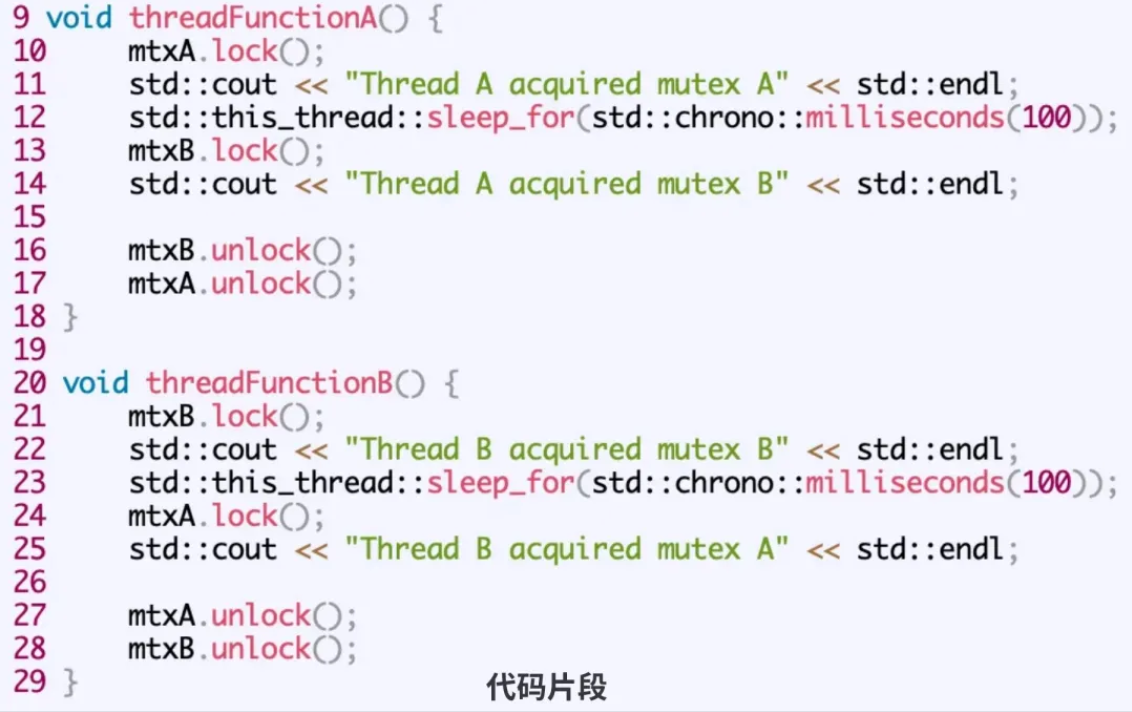
代码缺陷:并发安全

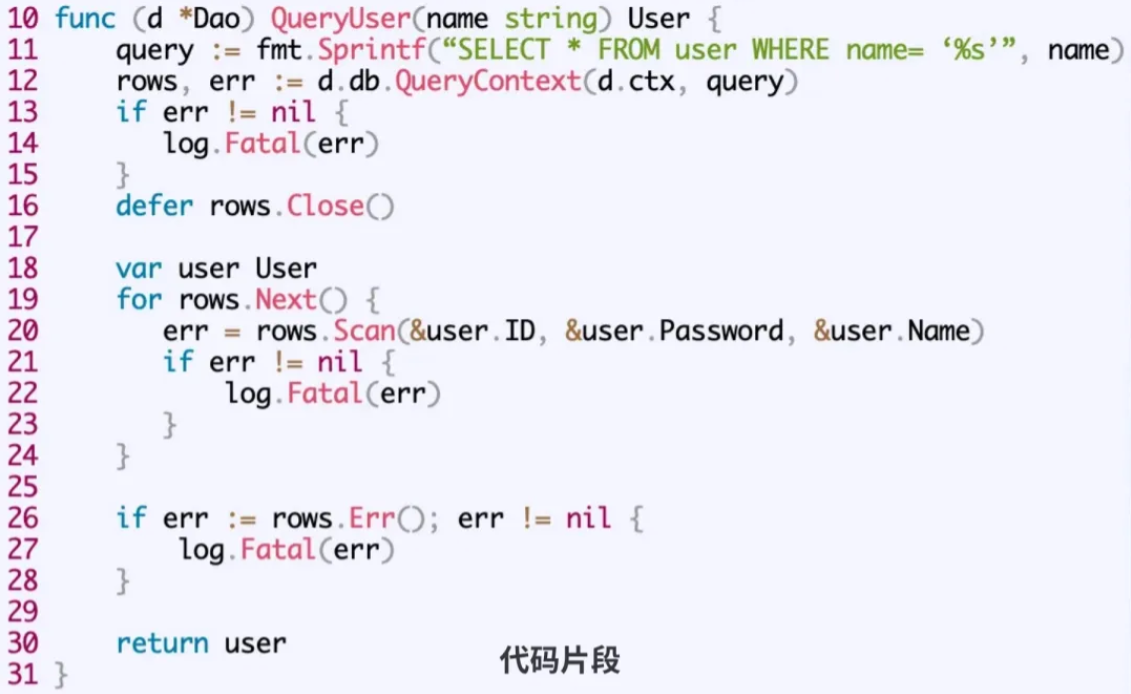
安全漏洞(SOL注入)


编程规范(硬编码)

腾讯 AICR 落地效果
截止目前,腾讯集团超 60% 的代码评审用户,日常使用 AI 辅助 CR 过程,同时也采集大量 bad case,截至目前,取得以下效果:
AI 评审发现问题数 8w/月,已与人工发现问题数达相同量级(人工 8w/月),用户对 AI 意见的好评率 60%;代码修复 AI 直接修复问题代码 2.0+ w次/月,采纳率超 25%
此外,腾讯 65% 的评审单据,由 AI 提炼概括变更内容,便于评审者理解。生成内容好评率超 90%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号