
使用Python调用百度千帆免费大模型接口
百度的千帆大模型免费了。

一、开通免费模型接口
在 在线服务中,找到模型列表,在右侧有 免费开通 按钮,点击开通后 如图所示。
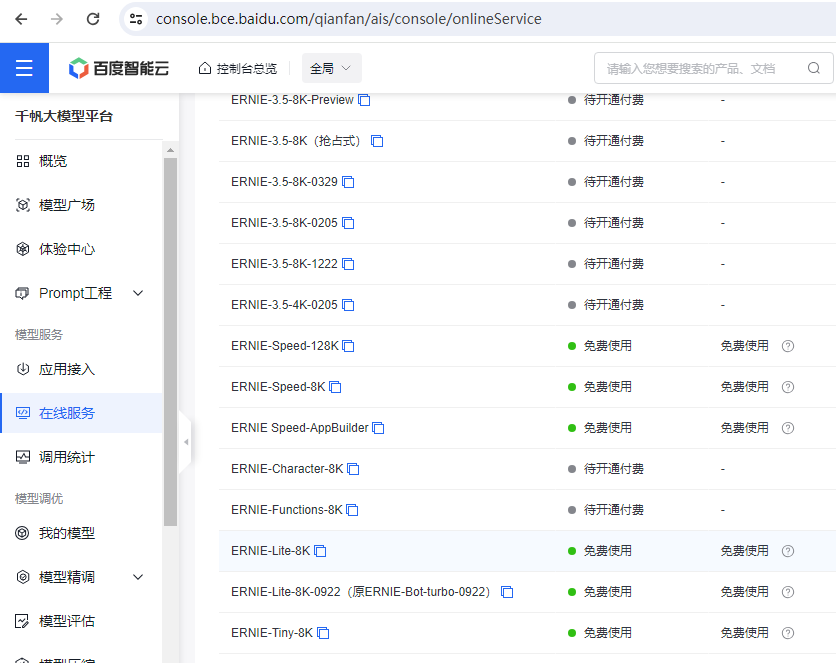
二、获取API Key和Secret Key
进入百度智能云 千帆大模型平台, https://console.bce.baidu.com/qianfan/overview
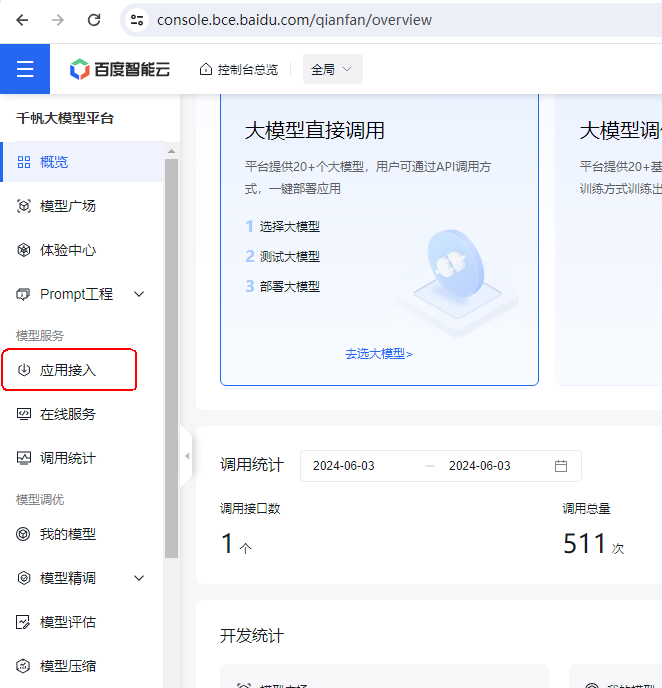
点击应用接入,进入应用列表
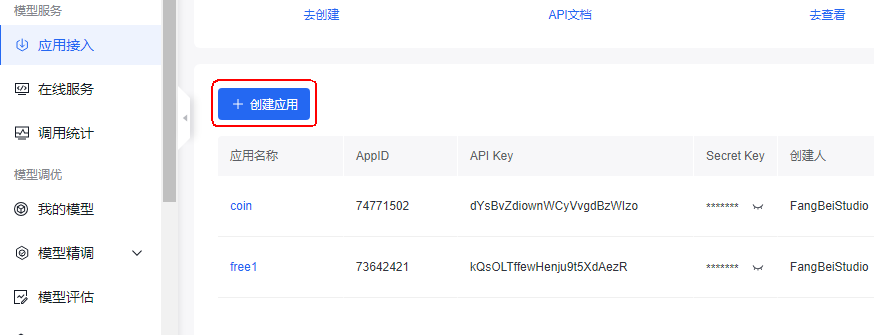
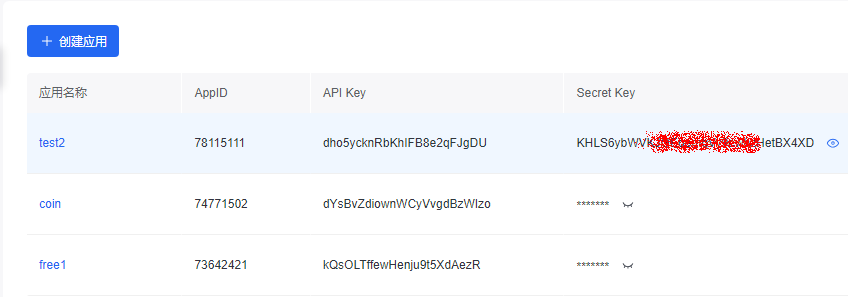
点击创建应用,
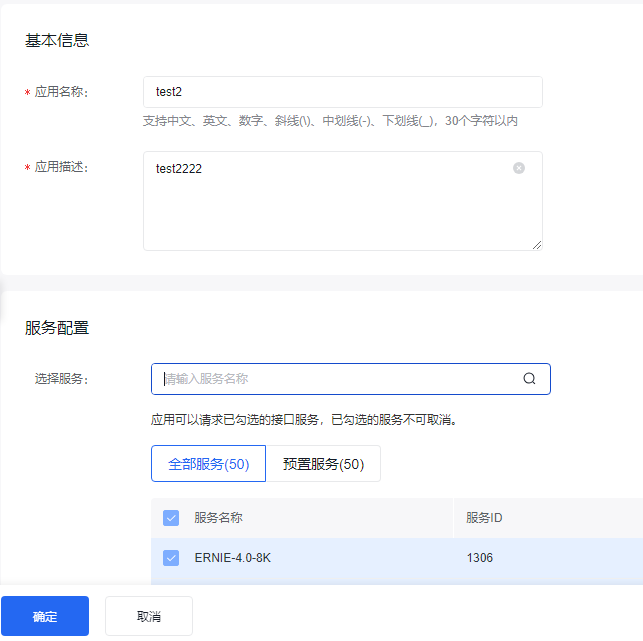
这样就有了
三、开发
开发文档 地址:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/klqx7b1xf
基本信息
请求地址: https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie_speed
请求方式: POST
Header参数
根据不同鉴权方式,查看对应Header参数。
- 访问凭证access_token鉴权
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| Content-Type | string | 是 | 固定值application/json |
- 基于安全认证AK/SK进行签名计算鉴权
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| Content-Type | string | 是 | 固定值application/json |
| x-bce-date | string | 否 | 当前时间,遵循ISO8601规范,格式如2016-04-06T08:23:49Z |
| Authorization | string | 是 | 用于验证请求合法性的认证信息,更多内容请参考鉴权认证机制,签名工具可参考IAM签名工具 |
Query参数
只有访问凭证access_token鉴权方式,需使用Query参数。
- 访问凭证access_token鉴权
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| access_token | string | 是 | 通过API Key和Secret Key获取的access_token,参考Access Token获取 |
Body参数
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| messages | List(message) | 是 | 聊天上下文信息。说明: (1)messages成员不能为空,1个成员表示单轮对话,多个成员表示多轮对话 (2)最后一个message为当前请求的信息,前面的message为历史对话信息 (3)必须为奇数个成员,成员中message的role必须依次为user、assistant (4)message中的content总长度和system字段总内容不能超过24000个字符,且不能超过6144 tokens |
| stream | bool | 否 | 是否以流式接口的形式返回数据,默认false |
| temperature | float | 否 | 说明: (1)较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定 (2)默认0.95,范围 (0, 1.0],不能为0 |
| top_p | float | 否 | 说明: (1)影响输出文本的多样性,取值越大,生成文本的多样性越强 (2)默认0.7,取值范围 [0, 1.0] |
| penalty_score | float | 否 | 通过对已生成的token增加惩罚,减少重复生成的现象。说明: (1)值越大表示惩罚越大 (2)默认1.0,取值范围:[1.0, 2.0] |
| system | string | 否 | 模型人设,主要用于人设设定,例如:你是xxx公司制作的AI助手,说明:长度限制,message中的content总长度和system字段总内容不能超过24000个字符,且不能超过6144 tokens |
| stop | List(string) | 否 | 生成停止标识,当模型生成结果以stop中某个元素结尾时,停止文本生成。说明: (1)每个元素长度不超过20字符 (2)最多4个元素 |
| max_output_tokens | int | 否 | 指定模型最大输出token数,说明: (1)如果设置此参数,范围[2, 2048] (2)如果不设置此参数,最大输出token数为1024 |
| frequency_penalty | float | 否 | 正值根据迄今为止文本中的现有频率对新token进行惩罚,从而降低模型逐字重复同一行的可能性;说明:默认0.1,取值范围[-2.0, 2.0] |
| presence_penalty | float | 否 | 正值根据token记目前是否出现在文本中来对其进行惩罚,从而增加模型谈论新主题的可能性;说明:默认0.0,取值范围[-2.0, 2.0] |
| user_id | string | 否 | 表示最终用户的唯一标识符 |
message说明
| 名称 | 类型 | 描述 |
|---|---|---|
| role | string | 当前支持以下: user: 表示用户 assistant: 表示对话助手 |
| content | string | 对话内容,不能为空 |
响应说明
响应头Header参数
部分参数如下。
| 名称 | 描述 |
|---|---|
| X-Ratelimit-Limit-Requests | 一分钟内允许的最大请求次数 |
| X-Ratelimit-Limit-Tokens | 一分钟内允许的最大tokens消耗,包含输入tokens和输出tokens |
| X-Ratelimit-Remaining-Requests | 达到RPM速率限制前,剩余可发送的请求数配额,如果配额用完,将会在0-60s后刷新 |
| X-Ratelimit-Remaining-Tokens | 达到TPM速率限制前,剩余可消耗的tokens数配额,如果配额用完,将会在0-60s后刷新 |
响应体参数
| 名称 | 类型 | 描述 |
|---|---|---|
| id | string | 本轮对话的id |
| object | string | 回包类型 chat.completion:多轮对话返回 |
| created | int | 时间戳 |
| sentence_id | int | 表示当前子句的序号。只有在流式接口模式下会返回该字段 |
| is_end | bool | 表示当前子句是否是最后一句。只有在流式接口模式下会返回该字段 |
| is_truncated | bool | 当前生成的结果是否被截断 |
| result | string | 对话返回结果 |
| need_clear_history | bool | 表示用户输入是否存在安全风险,是否关闭当前会话,清理历史会话信息。 true:是,表示用户输入存在安全风险,建议关闭当前会话,清理历史会话信息。 false:否,表示用户输入无安全风险 |
| ban_round | int | 当need_clear_history为true时,此字段会告知第几轮对话有敏感信息,如果是当前问题,ban_round=-1 |
| usage | usage | token统计信息 |
usage说明
| 名称 | 类型 | 描述 |
|---|---|---|
| prompt_tokens | int | 问题tokens数 |
| completion_tokens | int | 回答tokens数 |
| total_tokens | int | tokens总数 |
注意 :同步模式和流式模式,响应参数返回不同,详细内容参考示例描述。
- 同步模式下,响应参数为以上字段的完整json包。
- 流式模式下,各字段的响应参数为 data: {响应参数}。
代码如下:
1 import requests 2 import json 3 import datetime 4 5 class QIANFAN: 6 7 _api_url = "https://aip.baidubce.com" 8 9 def __init__(self, api_key, secret_key): 10 self.API_KEY = api_key 11 self.SECRET_KEY = secret_key 12 13 url = self._api_url + "/oauth/2.0/token" 14 params = {"grant_type": "client_credentials", "client_id": self.API_KEY, "client_secret": self.SECRET_KEY} 15 result = self.http_request_v2(url, method="POST", params=params) 16 if 'access_token' in result: 17 self.access_token = result["access_token"] 18 else: 19 print(result) 20 exit() 21 22 23 def chat(self, model="ernie-lite-8k", message=None, **kwargs): 24 url = f"{self._api_url}/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/{model}?access_token={self.access_token}" 25 26 payload = json.dumps({ 27 "messages": [{"role": "user", "content": message}], 28 "temperature": 0.95, 29 "penalty_score": 1 30 }) 31 32 for key, value in kwargs.items(): 33 payload[key] = value 34 35 print(payload) 36 response = self.http_request_v2(url, method="POST", params=payload) 37 return response 38 39 # 生成headers头 40 def headers(self, params=None): 41 headers = {} 42 headers['Content-Type'] = 'application/json' 43 return headers 44 45 def http_request_v2(self, url, method="GET", headers={}, params=None): 46 headers['User-Agent'] = 'Mozilla/5.0 \(Windows NT 6.1; WOW64\) AppleWebKit/537.36 \(KHTML, like Gecko\) Chrome/39.0.2171.71 Safari/537.36' 47 if method == "GET": 48 response = requests.get(url) 49 elif method == "POST": 50 # data = bytes(json.dumps(params), 'utf-8') 51 response = requests.post(url, data= params) 52 elif method == "DELETE": 53 response = requests.delete(url, data= data) 54 55 result = response.json() 56 return result
调用方法如下:
# 示例用法 API_KEY = "dYsBvZdiownWCyVvgdBzWIzo" SECRET_KEY = "************************************" chat_client = QIANFAN(API_KEY, SECRET_KEY) print(vars(chat_client)) result = chat_client.chat(model='ernie_speed', message="1加1为什么等于2?") print(result["result"])
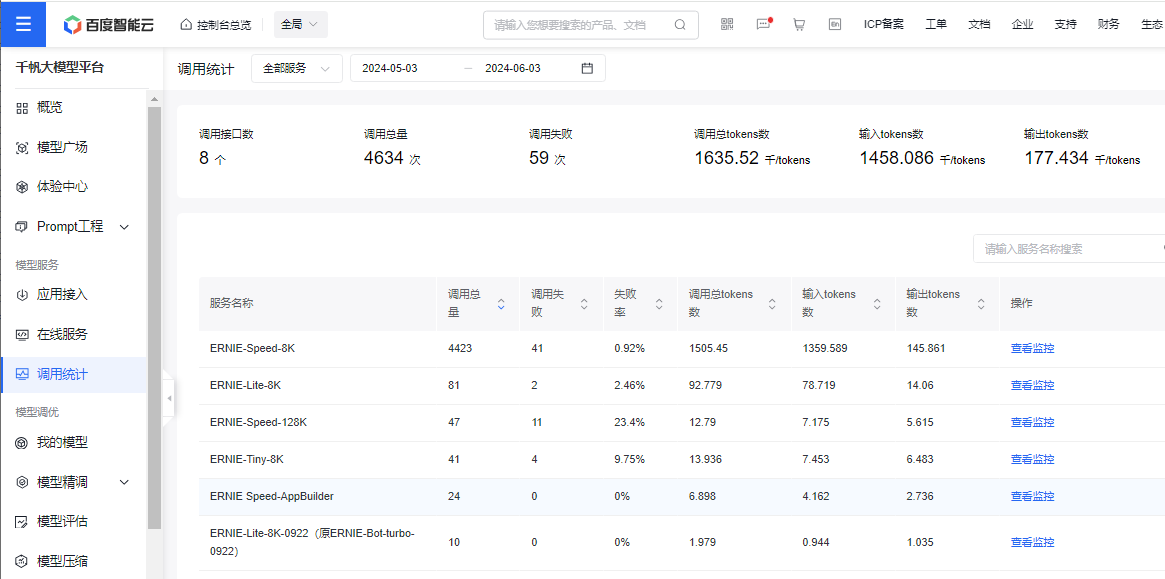
四、查看统计
在调用统计中可以看到统计信息
本文来自博客园,作者:方倍工作室,转载请注明原文链接:https://www.cnblogs.com/txw1958/p/18229642/baidu-qianfan

 浙公网安备 33010602011771号
浙公网安备 33010602011771号