
复盘报告:心跳数据丢失,从发现到解决历经一年多的bug
时间线
- 大约在2020年10月,内网测试服服务端更新,发现进程A重启后,与其他进程之间的心跳协议不通,不能正常的提供服务。重启后,就正常了。
- 这个情况持续了很长时间。只在重启时才会出现,且发生概率很低,一个月一次的概率。所以这个问题就被搁置了。
- 现网部署后,发现更新时,也出现了这个情况,但是由于重启就可以解决,这个问题被归属为:重要但不紧急的范畴。
- 大约2021年5月,花了一些时间尝试解决这个问题。由于没有找到重现的步骤,所以等待出现问题时观察现场。后面有一次出现了,进行排查:
看日志,没有异常。重点看网络。
netstat发现进程A与进程B的tcp是连接的。
tcpdump发现进程A发出的心跳数据,进程B的tcp层接收数据了,但是进程B的业务层没有收到数据。由于A与B之间的心跳数据没有闭环,所以进程B认为进程A不存在,故进程A虽然启动成功了,但是没能正常对外提供服务。
由于内网不能一直保存现场,需要对外提供服务,重启了进程A,问题的原因还是没有找到。
- 2021年12月,做了一个一键编译发布的工具,便于服务端更新,提高工作效率。发现使用一键发布后,这个问题又出现了。经过多次重试,发现使用一键发布,这个问题必现。经过排查,排除了工具本身的问题。
进程B是listen端,进程A是connect端,A主动连B。底层通信组件是ZMQ。按照ZMQ设计,底层是会自动重连的。
初步怀疑是ZMQ的bug,于是把ZMQ升级到最新版本,发现问题仍然存在,确定是业务代码有问题。
通过tcpdump,netstat等工具,发现现象和之前是一样的:进程A发出的心跳数据,进程B的tcp层接收数据了,但是进程B的业务层没有收到数据。
- 这个问题确定是必现问题,就好解决了,继续推进。通过多次重试,发现了一个规律:
进程B是listen端,进程A是connect端,A主动连B。只要进程B重启后,进程A在大约3秒内去连B,就会出现这个问题。如果是3秒后,A再连B,就不会出现这个问题。
期间也怀疑代码多线程的问题,通过测试也排除了。
-
有了这个3秒的规律,于是看代码,看哪些地方会和这个3有关系。果然代码有一处跟这个相关:
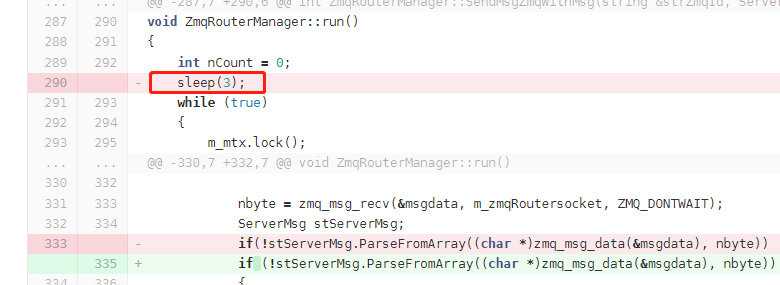
把3改为5、10来测试,发现问题和这个数字强相关。
于是把这行代码删除。 -
修改代码后,重新发布,多次测试后,结论:问题解决。原因是什么呢?后面讲。
问题如何发现的
因为有可视化监控。如果没有可视化监控,这个问题是很难发现的。
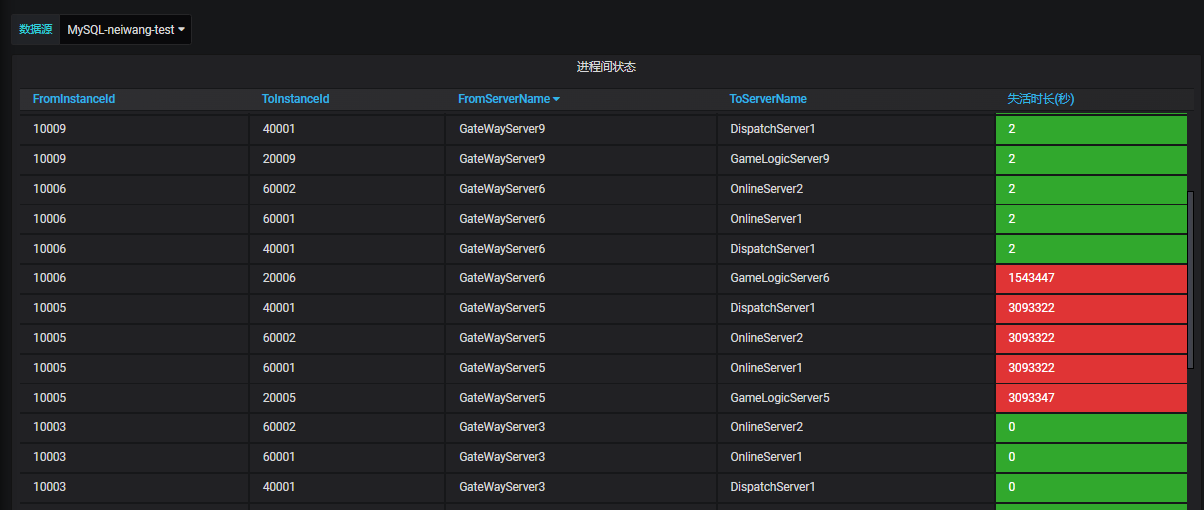
这个图体现的是进程之间的心跳信息。
绿色:正常
红色:失活,失活了多长时间,可以倒推出最后一次心跳正常的时间。
问题产生原因
- 最开始之所以偶现,是因为更新时,手速有快慢,快的时候就撞到了这个问题。
- 开发了一键发布工具,重启进程就很快,故而偶现问题就找到了必现方法。
- 代码上的bug:执行zmq_bind() 后,套接字进入静音状态,在router模式下是丢弃数据的。需要bind后,立即调用recv,跳过静音阶段。删除代码中的sleep,问题即解决。

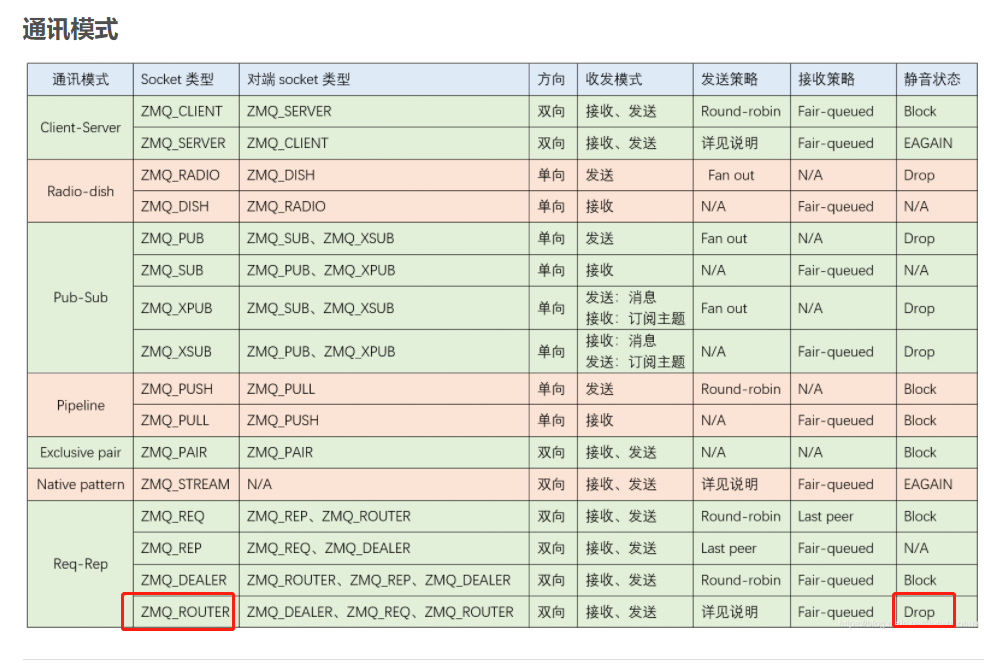
- 继续分析。执行zmq_bind() 后,套接字进入静音状态,sleep结束后调用recv,结束了静音状态,后续应该可以正常接收消息的,但是并没有。
在连接建立的过程中,当TCP三次握手后,StreamEngine会再一次和另一端握手,这是ZMQ应用层自己的握手协议,握手成功后,就进行msg的传递了。
原因是:静音状态下,router丢弃了dealer的握手协议。后面的数据也就不接收了。
正常的流程:tcp三次握手成功--zmq层握手成功--业务层心跳激活--业务层数据传递。
复盘沉淀
- 得益于可视化,对发现问题提供了很大的帮助。
- 找bug类似于找规律,多试试有好处。
- 在线文档持续跟踪,即使时间跨度很长,也能接续起来。
- 遇到问题时,第一时间去查看官方文档。
