
原创:语义相似度(理论篇)
如果本文观点有不对的地方,欢迎指正! author:佟学强
开场白:对于事物的理解,一般分3个层次:①看山是山,看水是水②看山不是山,看水不是水③看山是山,看水是水。对AI和nlp的理解,同样会有这三个层次。比如,刚毕业的硕士或者毕业1~2年的,会热衷于研究GAN,seq2seq,甚至包括nlp刚起步的一些公司。这类群体对nlp的理解处于第一层次,后面还有很多雷区要踩,要付出一定的试错代价,成长的代价。等到有一定的积累了,对nlp的理解有一定的理解功底了,会逐渐修正研究路线和方向,这个时候比第一阶段有更多的疑惑,因为随着研究的深入,发现nlp和图像机制存在很大的不同,不能照搬,认知智能好像不是那么容易,由感知智能到认知智能的跨越,是这一阶段的一大进步,这是第二个层次,各个派别有争论,看山不是山,看水不是水。最高境界,返璞归真,拥有行业20年及以上的研究人员,对nlp看的比较透,目前的Ai基本上陷入了统计建模,概率的漩涡之中,还不是真正的智能。仅仅从数据中挖掘线性关系还远远不够,应该让机器具有认知能力,挖掘因果关系。致力于推进nlp认知智能的进步,加大力度研究知识图谱,包括知识图谱的向量化,与深度学习的融合,让神经网络学习规则等等。可以这样说,目前从感知智能到认知智能的跨越,才刚刚开始,知识工程的复苏势不可挡。本人接触过许多刚入门的人,基本上对seq2seq和GAN比较狂热,对nlp缺乏完整系统的认知。对于GAN在nlp中不work以及为何不适用于nlp,可能没有深入的思考,甚至图像处理机制和nlp文字理解的神经元机制,到底存在哪些不同,目前需要深入探讨。比如动物神经元对图像的识别,第一层神经元是保角映射,那么nlp中是否需要这种机制?把CNN照搬到nlp中,为何会出现语义丢失问题?word2vector对于训练语料中未出现的词,如何更好地表达语义?它与TF_IDF存在着怎样的联系?LSTM同样存在语义丢失问题,如何解决?知识图谱的异构性和不均衡性给其向量化带来了挑战,在什么样的场景下需要向量化?把CRF神经网络化的必要性和场景又是什么?挖掘因果关系,比如:李娜为什么是最好的网球运动员?这种简单的因果关系推理,知识图谱是如何发挥作用的?再比如,一个人从非洲回来了,发高烧了。这件事情背后,非洲,发高烧和疟疾存在线性关系,那么因果关系是什么?所以总结起来,nlp同时需要联结主义和符号主义,对于研究人员来说,个人认为目前nlp的研究总体上应该朝着以下方向进行:①联结主义在nlp中的主要作用是语义表示,语义丢失问题必须要解决②由感知到认知的跨越:知识图谱,然后结合联结主义,其中一个方向是transD向量化,然后融入到深度学习模型中。写这篇文章不是为了发论文,也不是探讨基础的公式推导,主要目的是扩大传播面,点到为止,让一些刚入门的研究人员多一些思考,扩大知识面,甚至帮助其矫正研究方向。前面本人提到的问题,后面会部分有解答,但是大多数还需要坐冷板凳深入研究。多与业内大咖探讨,共同推进nlp的进步。下面进入正文。
nlp中语义理解一直是业内的难题。汉语不同于英语,同样一个意思,可以有很多种说法,比如你是谁的问题,就可以有如下几种:①你是谁?②你叫什么名字?③您贵姓?④介绍一下你自己 等等。这些句子在语义上是十分接近的,如果做一个智能音响,对音响说出上述任何一句,其结果不应该因为句子形式的不同而不同,也就是说训练出的模型不能对同义语句太敏感。在神经概率语言模型,也就是深度学习引入到nlp中之后,word2vector,lstm,cnn开始逐步占据主导。在最开始的由word2vector表达词向量,扩展到目前的用LSTM表达句子的向量,还有RCNN应用于NLP可以抽取出一个句子的高阶特征,这几年热度一直居高不下。
然而联结主义只是解决了人的感知能力,还不具备逻辑推理。众所周知,人类有两种智能,一个是归纳总结,另一个是逻辑推理,前者属于感知层面,后者属于认知层面。从感知到认知的跨越,知识图谱是必不可少的!深度学习目前在语义表示上最大的问题是太机械化了,自适应能力太差,相比之下的统计概率语言模型可以平滑,灵活度高一些。比如用w2v训练出的词语义表示就很机械化,对于汉语中的一词多义现象,他无法做到上下文重叠。lstm用最后的压缩向量来表示一个句子的语义也很机械化,不能照顾到上下文的语境问题,同一句话在不同的语境或者上下文中其语义或者语义贡献度是不同的,所以语义表示也应该不同。甚至同一句话用不同的语气说,语义也是不同的,机器如何感知?如何让现有的模型训练出的语义更加灵活是一个重要的研究课题。
word2vector的语言模型有CBOW和Skip_gram,核心思想是:相同语境出现的词语义相近。这个思想在nlp语义上占据重要位置。用word2vector训练出的词表达具备语义关联,同时兼顾了上下文。w2v可以解决词级别的语义相似度问题。本人以word2vector为核心进行了延伸,如下:
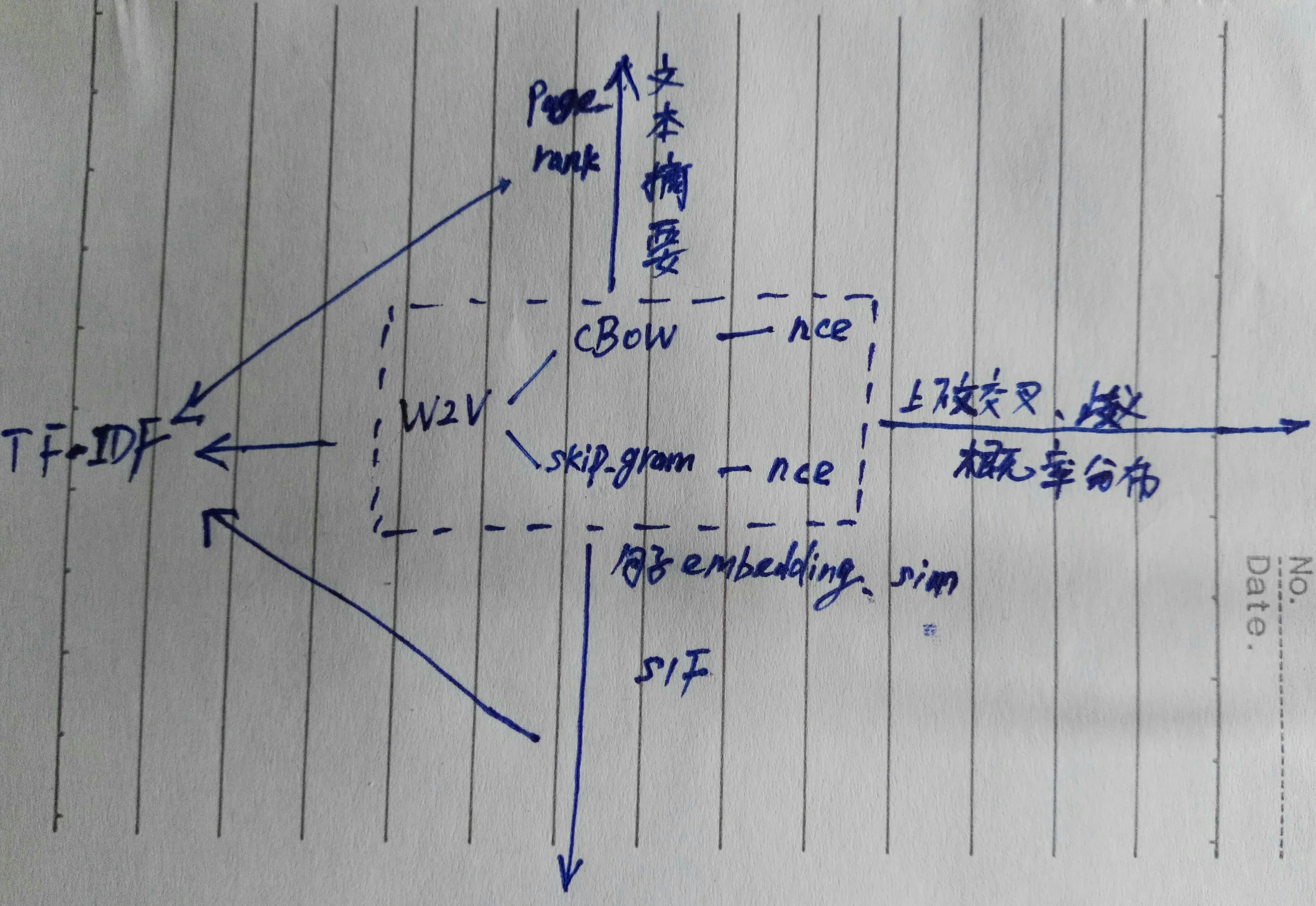
本人所画的图,对w2v进行了深入的分析以及拓展,其中上下文交叉,词语歧义还属于空白。w2v的底层原理不必多说,但是有很多的文章关于他的公式推导是不正确的,包括skip_gram的优化。tensorflow的nce(negative constantive estimate)源代码一定要完整地阅读一遍。关于w2v存在的问题,之前博客里有部分论述,这里不讨论他的缺陷了。词向量属于序列化问题,知识图谱的向量化是图结构的,把他碾平了可以看成是序列化的,其语言模型核心思想与w2v如出一辙。有一个重要的需要讨论的问题是它与TF_IDF的关系,在SIF这篇论文里会有一些论述,把两者结合起来是有必要的,但是要看场景!!w2v从语义层面,TF_IDF从字面层面,两者结合可以更加灵活,可以解决w2v训练过程中的部分高频词的语义倾斜,尤其是在out of context的场景下,这点从skip_gram的NEG底层公式推导中可以得出结论。更深一步地讲,w2v获取的词向量与频率有着密不可分的关联。可以把每个句子看作是一篇没有重复词的DOC,那么训练语料中词的频率可以看作是TF_IDF中的IDF。在众多相同或者相近的上下文中,每个词出现的频率不同,直接导致每个词与其上下文的语义关联程度不同,最后造成的结果是高频词的语义向量相对于低频词更加稠密,与上下文关联更加紧密。从频率角度来看,高频词确实应该向量更加稠密一些,但是也会有部分高频词的语义倾斜是无意义的(在特定的场景下),比如and ,or等词语,而这些词在情感分析中却又是必要的。而针对out of context的场景,也就是这个词的上下文在训练语料中并没有出现过,进行语义平滑是最恰当不过的了。图中出现了句子embedding表示,基于非监督学习的思想,每句话会有一个隐含的embedding表示,而句子中的每个词会有训练好的embedding(w2v),由句子embedding进行发射,映射到每个词的embedding,会有发射权重,加权求和后得到句子向量。这个向量与隐含的embedding的距离应该最小。这是SIF的思想精髓。而国外一些文献中,会有研究未登录词的embedding,运用词形态学把词拆分,类似于character_cnn,但是很遗憾不适用于汉语。深入研究w2v有助于利用非监督学习方法做语义层面的运算,包括词语,句子,文章摘要,甚至未来的歧义词。研究简单实用的方案,永远是工业界的使命。w2v的应用场景:①给机器一个简短语句,机器生成相似度比较高的句子,方案具体细节可以询问张俊林博士②运用SIF解决句子相似度问题(非监督学习)③结合pagerank做文章摘要④最普遍的,作为RNN的输入。最后强调一句,一定要对TF_IDF以及w2v深入研究,发现两者的优缺点,学会在适当的场景下结合两者,但是不是绝对的,再强调一遍,学习Ai不要停留在套模型的原始思维阶段。比如IDF的演化推导,可以从信息论的角度来理解。
另外w2v训练过程的优化,如果优化效果不错的话,会提升LSTM,CNN等模型的效果。w2v需要改进,CNN同样也需要改进,尤其是max pooling,在nlp中不能照搬图像处理的机制,否则会丢失语义信息。关于丢失语义信息问题,是深度学习在nlp中必须要解决的问题。解决途径:①self_attention②k_max pooling或者动态池化层。本人比较青睐于self-attention,它主要与BiLSTM结合,更加符合nlp规律。还有,LSTM和CNN获取的语义表示,其实属于语言模型层面的,这一点可以自己体会。
在word2vector产生后,情感分析便由word2vector和svm主导,先获取到用户评价句子的每个词的表示,对每个词打分,然后加权求和得出一句话的得分,来判断这句话是好评,中评还是差评。很显然,这种方法只是从词这个局部单元考虑出发,并没有考虑到整句话所表达的意思,很容易陷入局部最优解。lstm产生后,便摒弃了这个方案,先由lstm训练出这句话的向量,然后进入到回归层进行打分。这样就能从整句话出发来判断用户的评价了。
尽管如此,研究人员并没有停止语义分析研究的步伐。如何做句子级别的语义相似度?在nlp中,文章摘要或者信息抽取一直是没有突破的课题,深度学习引入之后,便有了一些改进。文章摘要,不管采用什么样的手段,都离不开三个核心问题:①句子相似度的计算②文摘句抽取③文摘句排序。运用siamese lstm,训练的时候,输出为两个句子向量的一阶范数的指数函数,代表两个句子的差异程度,让这个值与真实的打分值的损失函数最小。这样训练得出的两个句子的向量与普通的标准的LSTM训练出来的向量是有区别的。标准的lstm单独训练出来的每个句子向量只能代表一个句子,句子之间是独立的。这个方案可以解决句子的语义相似度。
如何获取整篇文章的语义表示?可以把每个句子的向量累加成文章向量,然后用元智或者元积衡量每个句子和文章向量的差异,选出k个相似度最高的句子作为文章摘要句。关于如何获取整篇文章的语意表达,这里有一个比较low的方案,呵呵:
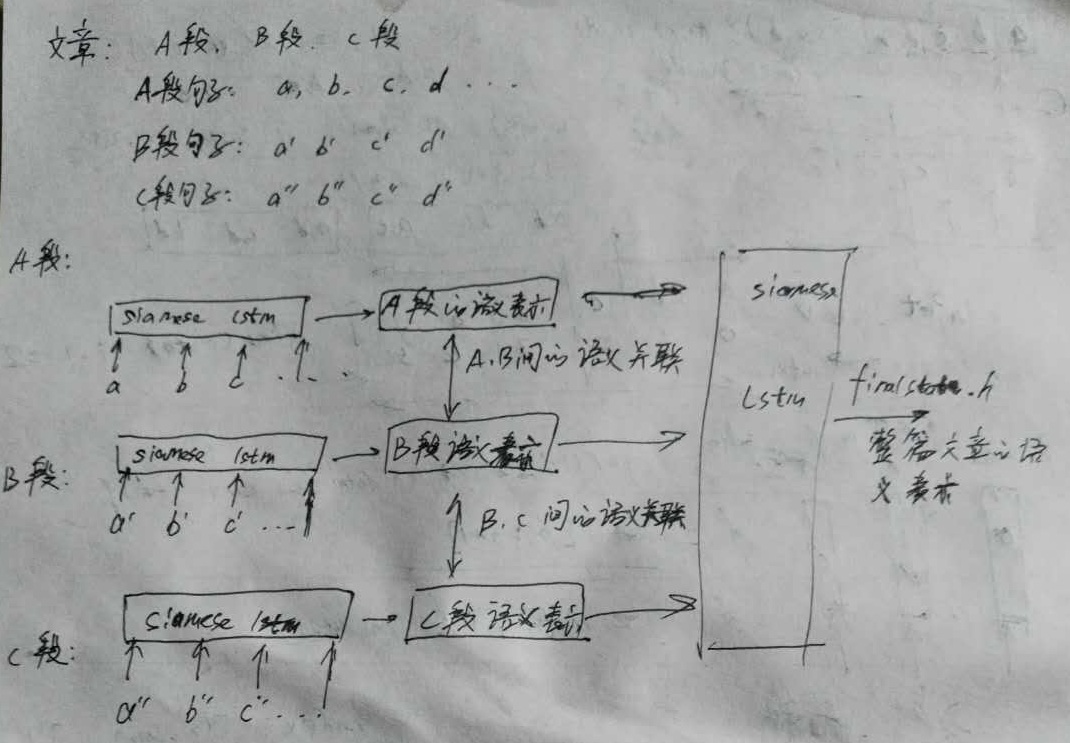
feature1:一篇文章包括A,B,C三段,每段有a,b,c……句子,先用siamese lstm获取到每个句子的语义表示,然后把每个句子作为基本输入单元,输入到siamese lstm中,再把每段作为基本单输入到siamese lstm。这里的每个siamese lstm是不一样的,需要单独训练好,比如第二个可以衡量段落之间的语义相似性。
这个方案很明显是不切实际的,只是粗糙地累加而且训练时间复杂度太高,运行效率明显存在问题,训练的模型太多。有没有更好的方案呢?本人认为,一个比较好的方案是可以抽取出文章的中心句作为整篇文章的语义表示。而这个中心句的语义表示很显然与他的上下文存在着密切的语义关联,训练过程中必须照顾到这一点。我们可以先谈一下人脑对于一篇文章的语义理解。给你一篇文章,从第一句话顺序阅读,直到文章结束,我们会抽取出其中的中心句或者总结出中心思想来代表这个文章。从第一句话开始,我们的大脑就开始猜测他是不是中心句,然后看下面的内容是否围绕着它来展开论述的,如果不是,继续猜测后面的句子,执行相同的逻辑推理,主要看上下文与这个句子的语义关联程度。而在阅读的过程中,大脑的高级中枢会指挥注意力分配机制,具体来说,上下文的每句话中的每个词对中心句的语义贡献度是不同的,这些词随着时间的推移,有些给我们留下了深刻的印象,有些则遗忘了。这种注意力分配会导致新的句子的形成,而到达下一个句子时,前面新形成的句子同样存在着这样的现象。
其实上面描述的过程明显涉及到了hierarchical attention,而且是两个级别的attention:词级别的和句子级别的。词级别的attention负责把上下文中的每个句子的词重新组合成一个新的句子,句子级别的attention在此基础上把这些新形成的句子再次重新组合成一个新的句子,这就是最终的上下文。如果这个最终的上下文语义表示和我们猜测的中心句语义相似度很高,那么他就是中心句,如果不是,前向搜索继续执行这个逻辑。这个方案是本人首次提出的siamese lstm + hierarchical attention组合而成的,用以模拟人脑在抽取文章中心句的过程。具体训练的语料格式可以如下:【文章,中心句,1.0】后面是相似度得分,用目前计算语义相似度最好的模型siamese lstm。(2017年有学者提出了非监督学习的SIF,但是本人认为应用场景很受限,仅供借鉴)上下文的每个句子的词序列输入到siamese lstm中的第一个lstm中,中心句输入到另一个lstm中,然后用中心句的语义表示对齐第一lstm中的每个词语义表示,累加成新的句子语义存储起来,而后做句子级别的attention对齐,使用中心句的语义表示对存储的所有上下文新句子的语义表示进行对齐操作,然后求加权平均值得到最后的上下文语义表示,最后输出打分值:exp(-||x1 - x2||1),然后用MSE作为损失函数开始训练。
预测的时候,模拟人脑抽取中心句的过程,从第一句开始,时间序列t0,后面的语句全是下文,用训练好的模型得到最终的语义,然后运行exp(-||x1 - x2||)节点,然后把第一句的编号和相似度得分封装成一个对象,存储在一个数组里面,增加时间序列到t1,计算他的上下文语义,把第二句话编号和相似度得分存储在数组里,以此类推。最后用本人设计的优先级队列(优于jdk底层的优先级队列,要求兼顾时间空间最优)推荐出top K,K一般非常小,比如2,3。
计算句子语义相似度在nlp中不仅限于文章摘要。他可以增强nlp的语义理解能力,在机器翻译中也有重要的应用甚至在nlp的挑战性的场景,比如给你一段话,要求不改变文章思想的情况下把这段话拆分成两段,也就是文章断句分段。这个问题的解决方案可能复杂一些,siamese lstm只是一个基础性的支撑。解决语义问题,首先要解决的是获取语义的表示,通常情况下用dense向量来表达。但是标准的lstm最大的意义是提供了基础学术研究,因为他获取到的语义表达是独立的,不具备语义关联,重要的事情重复三遍,不具备语义关联,不具备语义关联,不具备语义关联!!考察语义相似度,要考虑单个句子或者整篇文档的上下文。
目前,计算语义关联,或者计算语义相似度,有众多学者探索了以下方案:①convnet,cnn引入到nlp中②skip_thought,改进型的w2v③tree_lstm。基于ma结构的siamese lstm已经超越了当下的state of the art,效果已经击败了上述三个方案。他的最大亮点是exp(-||x1 - x2||1),为什么不用L2范数衡量获取到的句子向量的差异,一方面用w2v训练出的词,存在大量的欧氏距离相同的情况,如果用L2范数衡量,效果很不稳定,存在语义丢失现象,而cos相似度适用于向量维度特别大的场景。用ma距离来衡量是最恰当的。另一方面,BPTT说起,用L2范数会存在梯度消失的问题。因为最终获取的向量实际上是两个句子向量的差值,可以看成是一个向量,上述的函数可以看作是激活函数,进行梯度训练时,由于L2函数的特性,只能衡量较短句子的差异,也就是说,当句子很长时,本来语义相似度很低,他却衡量不出来,认为是相似度很高。这一点也体现了标准的LSTM的能力是有限的,超过30步数记忆能力直线下降,一个长句子通过模型训练得到的final_state.h,占据比重最大的是后面的词语,前面的基本消失,因此需要attention model。
再强调一下,衡量特征向量差异的指标通常有欧式距离,曼哈顿距离和余弦相似度。如果一对儿向量在空间的绝对距离相等的情况下用欧式距离衡量效果是很差的,这个时候有曼哈顿距离效果会很好,曼哈顿距离会比欧氏距离稳定。用W2V训练出的词embedding在VSM中的欧式距离相等或者相近的情况是很常见的,所以用曼哈顿距离会稳定一些。余弦相似度适用于特征向量维度有很多的情况。
Simase LSTM指的是具有simase结构的LSTM网络,由两个平行双向LSTM构成,结构参考下面两张图:
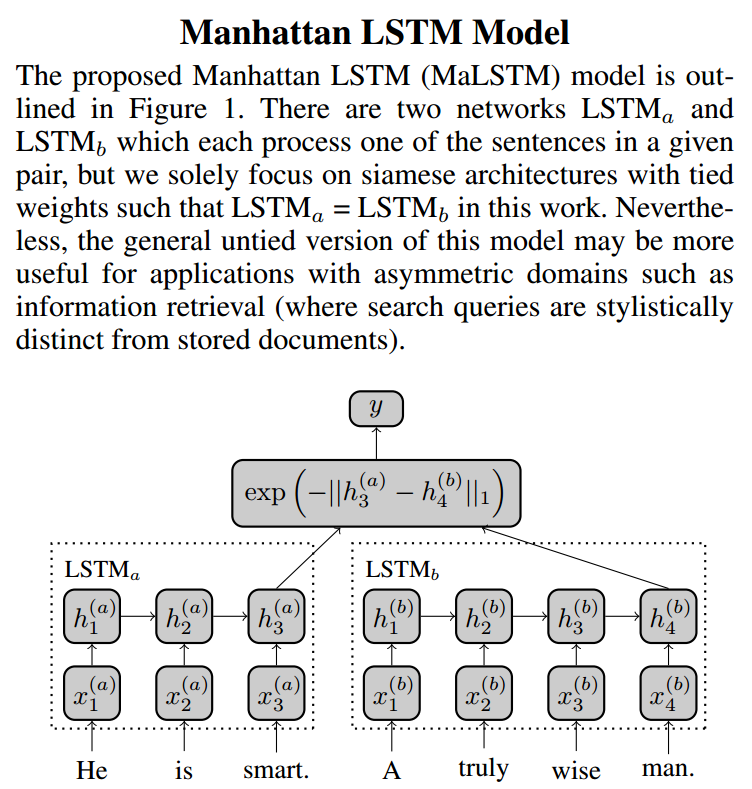

连体(双胞胎)LSTM输入为句子对儿,分别是上图中的左边和右边的。通过final state获取两个句子的向量,然后通过指数函数衡量差异,由于指数函数的指数为一阶范数的负数,所以取值范围为(0,1]。在构建样本的时候,一般情况给句子对儿打分都是1~5分,所以再通过一个非参数化的回归层映射到这个区间,用MSE作为损失函数,梯度优化方法为AdaDelta。一个典型的样本输入:[“I like playing basketball.”,”My favourite sports is basketball.”, 3.4]。按照作者在论文中提出的,连体的LSTM权重参数不应该一样,因为句子对儿长度是有差异的。另外作者在论文中提出了训练细节问题,经过试验验证,这个模型的准确度对参数初始化非常敏感。作者建议,权重参数初始化为随机的高斯分布参数,然后cell中忘记门的偏置值初始化为2.5,是为了训练更长的记忆能力。
siamese lstm方案的缺陷,有两个:①衡量长句子的语义相似度时候,效果比较差②没有融入外部知识。对于第一个缺陷,论文作者并没有进行深入的研究,本人经过摸索认为,不仅是长句子,即使对于短句子,如果里面涉及到了大量entity和relation的话,效果也并不是最优的。对于联结主义在语义理解上的贡献,本人认为第一个要突破的就是如何获取语义表示的多维度,而目前都是用LSTM的最后一个时间序列的out来压缩成一个向量来表示,这种表示不能捕捉多维度的语义。所以我们需要用一个矩阵权重参数来表示句子的语义权重,这个矩阵的每一行,应该都是一个概率和为1的概率分布,然后每一个概率分布应该捕捉语义的不同维度,最后concate来表示这个句子的语义。因此,在此基础上融合self_attention(2017年句子语义表示的baseline),尤其在情感分析中,效果非常好。
对于融合知识图谱和深度学习比如CNN做语义相似度,一个非常重要的场景就是新闻标题的推荐。新闻标题里往往包含大量的entity,识别出来后可以查询知识图谱得到one hot的entity,在其他标题中出现这些entity的新闻,用户往往也是感兴趣的,但不是绝对的。沿着知识图谱的路径,用户的兴趣会进行传播,这样的传播会有权重,这就是著名的用户兴趣传播,会形成一定的涟漪效应。把知识图谱的entity进行向量化,然后扩展标题中的词嵌入,在原来的词embedding基础上concate entity的embedding,然后用CNN捕捉标题的语义表示,与候选新闻做语义相似度运算。之前的博客提到过,个性化推荐的本质是语义理解中的语义相似度问题,这个定位非常重要,结合知识图谱,场景切入更自然,更加接近真实的效果,而且可以处理小数据。相比于传统的基于用户浏览数据的行为挖掘,更加符合实际,更加深入。
语义相似度是nlp中的一个难题,如果突破了,会有一些改变,比如目前的问答,进展很是缓慢,为了节约成本或者前期缺少大数据,在垂直领域,很多公司用基于规则来做,召回率太低。问答,最初的时候,比如畅捷通的会计家园,使用的是基于语义相似度的方案,效果还可以。case by case。当用户经常提出一些比较长的问题,又不是BFQ的情况,比如,用户提问,我想知道注册会计师证考下来后,对就业到底有没有实质性的帮助,薪资能提升多少,好考吗?对于这类问题,用模板匹配显然是不合适的,向量建模更不合适。所以说,知识图谱的问答不是万能的。但是如果业内在语义相似度上突破了的话,那么这种方案,在垂直领域的问答,无疑是很好的。只要语料充足,遇到用户提出的问题,我们先进行语义相似度的计算,选出得分最高的问答的答案,直接呈现出来,如果相似度得分低于人工设定的阈值,进入seq2seq模块儿。这个方案,应该比目前的基于模板匹配要好一些。但是对于复杂的推理问题,比如梁启超的儿子的情人是谁这类问题,仍然需要语义解析,而且这样的场景,并没有多少实际意义。
更深入地讲,如果之前接触过垂直搜索lucene的话,我们会发现,问答和搜索的本质是一致的,都是减少用户需求不确定的过程。这样的过程,是靠系统的语义解析来完成的,比如lucene,用户输入"苹果",系统根本不知道用户的需求,需要额外添加约束,比如商品分类:电脑,这样经过lucene的词法处理(比如分词),句法分析(比如形成一颗查询语法树,典型的Boolean query)后,搜索引擎能够理解这样的查询语言,最后呈现出结果来。而问答呢,两个问题:①question的语义表示②把语义表示映射成知识图谱可以理解的查询语言。典型的core inferential chain,就是把这个过程一步一步分解,在查询的过程中不断施加约束,最后得出答案。目前的问答,大概有如下方案:①检索+seq2seq,适用于比例不高的自由聊天,而且seq2seq的场景比例很小②基于模板匹配:本质上是获取问题的模板表示后,训练模板与知识图谱predicate的映射概率,属于统计建模范畴,而且限制较多,不能处理multi hot推理③基于语义解析的方案④基于向量建模的方案⑤信息抽取的方案。信息检索里面,比较重要的一个场景是排序,比如著名的BM25排序,是用朴素贝叶斯推导出来后简化的。基于检索+seq2seq的自由聊天,排序用的就是BM25,question和answer的语义相似度得分用的是seq2seq框架,然后计算匹配度。对于multi hot的问答,个人认为,应该借鉴检索的核心思想,把知识图谱的搜索过程分解,逐步施加约束,融合语义解析,向量建模,基于规则等多种手段。基于规则在问答当中的作用往往是对检索施加约束,是辅助手段,而核心往往是语义相似度计算,question的语义表示。
所以,问答,一定要case by case 。对于BFQ的问答,模板无疑是比较好的,向量建模也可以。记住,场景是AI第一要素,切不可一味奉行拿来主义,先把自己的需求和场景研究明白了,才是关键。深度学习的研究方向,一定先把人类自身对于特定场景的逻辑搞明白了,才能少走弯路。
下一篇博客,继续介绍语义相似度:http://www.cnblogs.com/txq157/p/8656856.html
关于self_attention在语义表示中的作用:http://www.cnblogs.com/txq157/p/8445513.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号