

原创:平衡的三叉树
去年3月份,写了一个平衡的三叉树算法包,还写了一个基于逆向最大匹配算法的中文分词算法包。现在,将平衡的三叉树算法包上传。首先看一下包结构:
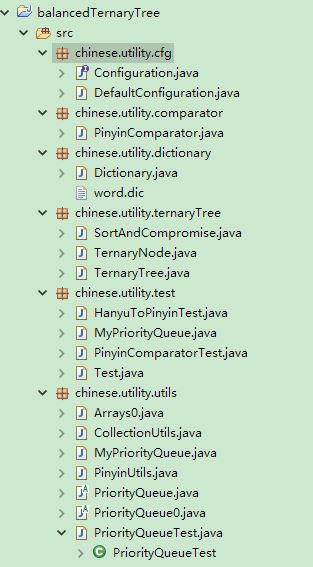
1.chinese.utility.cfg代码:
package chinese.utility.cfg;
/**
* 获得主词典、量词词典以及扩展词典和扩展停词词典的路径
* @author TongXueQiang
* @date 2015/11/25
* @since 1.8
*/
public interface Configuration {
public abstract String getMainDictionary();//主词典路径
}
package chinese.utility.cfg;
public class DefaultConfiguration implements Configuration {
@Override
public String getMainDictionary() {
return "chinese/utility/dictionary/word.dic";
}
}
2.chinese.utility.comparator代码:
package chinese.utility.comparator;
import java.util.Comparator;
import net.sourceforge.pinyin4j.PinyinHelper;
/**
* 严格拼音比较器
* @author TongXueQiang
* @date 2016/03/05
* @since JDK 1.8
*/
public class PinyinComparator implements Comparator<String> {
@Override
public int compare(String o1, String o2) {
for (int i = 0; i < o1.length() && i < o2.length(); i++) {
int codePoint1 = o1.charAt(i);
int codePoint2 = o2.charAt(i);
if (Character.isSupplementaryCodePoint(codePoint1)
|| Character.isSupplementaryCodePoint(codePoint2)) {
i++;
}
if (codePoint1 != codePoint2) {
if (Character.isSupplementaryCodePoint(codePoint1)
|| Character.isSupplementaryCodePoint(codePoint2)) {
return codePoint1 - codePoint2;
}
String pinyin1 = pinyin((char) codePoint1);
String pinyin2 = pinyin((char) codePoint2);
if (pinyin1 != null && pinyin2 != null) { // 两个字符都是汉字
if (!pinyin1.equals(pinyin2)) {
return pinyin1.compareTo(pinyin2);
}
} else {
return codePoint1 - codePoint2;
}
}
}
return o1.length() - o2.length();
}
/**
* 字符的拼音,多音字就得到第一个拼音。不是汉字,就return null。
*/
public String pinyin(char c) {
String[] pinyins = PinyinHelper.toHanyuPinyinStringArray(c);
if (pinyins == null) {
return null;
}
return pinyins[0];
}
}
3.chinese.utility.dictionary代码:
package chinese.utility.dictionary;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
import java.util.List;
import chinese.utility.cfg.Configuration;
import chinese.utility.cfg.DefaultConfiguration;
import chinese.utility.ternaryTree.SortAndCompromise;
import chinese.utility.ternaryTree.TernaryNode;
import chinese.utility.ternaryTree.TernaryTree;
/**
* 字典
* @author TongXueQiang
* @date 2016/03/06
* @since JDK 1.8
*/
public class Dictionary {
//主字典
private static volatile Dictionary main_dict;
//三叉树
private TernaryTree tree;
private Configuration configuration;
private Dictionary () throws Exception{
configuration = new DefaultConfiguration();
}
public static Dictionary getInstance() throws Exception{
if (main_dict == null) {
synchronized(Dictionary.class){
if (main_dict == null) {
main_dict = new Dictionary();
return main_dict;
}
}
}
return main_dict;
}
/**
* 从字典中读取汉字
*
* @param originalWords
* @return
*/
public List<String> addToListFromDict(List<String> originalWords) throws Exception {
//InputStream is = new FileInputStream("C:\\Users\\Administrator.2013-20150325HY\\Desktop\\word.dic");
InputStream is = super.getClass().getClassLoader().getResourceAsStream(configuration.getMainDictionary());
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"), 512);
String word = null;
try {
do {
word = br.readLine();
if (word == null) {
break;
}
if (word != null && !"".equals(word.trim())) {
originalWords.add(word);
}
} while (word != null);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (is != null) {
is.close();
is = null;
}
} catch (Exception e) {
e.printStackTrace();
}
}
return originalWords;
}
/**
* 加载主字典
* @throws Exception
*/
public void loadDict() throws Exception {
//把原来的字典替换为经过排序和折中处理的字典
replaceDictionaryBySortAndCompromise();
tree = new TernaryTree();
InputStream is = super.getClass().getClassLoader().getResourceAsStream("chinese/utility/dictionary/word.dic");
if (is == null) {
throw new RuntimeException("Main Dictionary not found!!!");
}
try {
BufferedReader br = new BufferedReader(new InputStreamReader(is,"UTF-8"),512);
String newWord = null;
do {
newWord = br.readLine();
if (newWord != null && !"".equals(newWord.trim())) {
tree.insert(newWord);
}
}while(newWord != null);
}catch(Exception e){
e.printStackTrace();
}
finally{
try {
if (is != null) {
is.close();
is = null;
}
} catch(Exception e){
e.printStackTrace();
}
}
}
/**
* 更新字典,对字典进行排序,然后折中处理
* @throws Exception
*/
private void replaceDictionaryBySortAndCompromise() throws Exception {
SortAndCompromise sac = new SortAndCompromise();
List<String> originalWords = new ArrayList<String>();
OutputStream os = new FileOutputStream("E:/Eclipse_WorkSpace/balancedTernaryTree/src/chinese/utility/dictionary/word.dic");
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(os,"UTF-8"),512);
//对原始字典进行排序,然后折中处理,输出到新的字典当中
sac.sortAndCompromise(originalWords, writer);
}
/**
* 查找前缀匹配词语
* @param prefix
* @return
*/
public List<TernaryNode> prefixCompletion(String prefix){
return tree.prefixCompletion(prefix);
}
}
word.dic为词典,保存格式为UTF-8无BOM编码格式。
4.chinese.utility.ternaryTree包代码:
package chinese.utility.ternaryTree;
/**
* 三叉树节点
* @author TongXueQiang
* @date 2016/03/12
* @since JDK 1.8
*/
public class TernaryNode {
public char storedChar; //节点存储的单个字符
public String token;//最后一个节点存储的term(成词)
public TernaryNode leftNode,centerNode,rightNode;//子节点
public TernaryNode (char storedChar) {
this.storedChar = storedChar;
}
}
package chinese.utility.ternaryTree;
import java.util.ArrayList;
import java.util.List;
import java.util.Stack;
/**
* 自定义三叉树
* @author TongXueQiang
* @date 2016/03/12
* @since JDK 1.8
*/
public class TernaryTree {
// 根节点,不存储字符
private static TernaryNode root = new TernaryNode('\0');
/**
* 向树中插入字符
*
* @param TernaryNode
* @param word
* @return
*/
public void insert(String word) {
root = insert(root, word, 0);
}
public TernaryNode insert(TernaryNode currentTernaryNode, String word, int index) {
if (word == null || word.length() < index) {
return currentTernaryNode;
}
char[] charArray = word.toCharArray();
if (currentTernaryNode == null) {
currentTernaryNode = new TernaryNode(charArray[index]);
}
if (currentTernaryNode.storedChar > charArray[index]) {
currentTernaryNode.leftNode = insert(currentTernaryNode.leftNode, word, index);
} else if (currentTernaryNode.storedChar < charArray[index]) {
currentTernaryNode.rightNode = insert(currentTernaryNode.rightNode, word, index);
} else {
if (index != word.length() - 1) {
currentTernaryNode.centerNode = insert(currentTernaryNode.centerNode, word, index + 1);
} else {
currentTernaryNode.token = word;
}
}
return currentTernaryNode;
}
/**
* 查找以指定前缀开头的所有字符串
*
* @param prefix
* @return
*/
public List<TernaryNode> prefixCompletion(String prefix) {
// 首先查找前缀的最后一个节点
TernaryNode TernaryNode = findNode(prefix);
return prefixCompletion(TernaryNode);
}
public List<TernaryNode> prefixCompletion(TernaryNode p) {
List<TernaryNode> suggest = new ArrayList<TernaryNode>();
if (p == null) return suggest;
if ((p.centerNode == null) && (p.token == null)) return suggest;
if ((p.centerNode == null) && (p.token != null)) {
suggest.add(p);
return suggest;
}
if (p.token != null) {
suggest.add(p);
}
p = p.centerNode;
Stack<TernaryNode> s = new Stack<TernaryNode>();
s.push(p);
while (!s.isEmpty()) {
TernaryNode top = s.pop();
if (top.token != null) {
suggest.add(top);
}
if (top.centerNode != null) {
s.push(top.centerNode);
}
if (top.leftNode != null) {
s.push(top.leftNode);
}
if (top.rightNode != null) {
s.push(top.rightNode);
}
}
return suggest;
}
/**
* 查找前缀的下一个centerTernaryNode,作为searchPrefix的开始节点
*
* @param prefix
* @return
*/
public TernaryNode findNode(String prefix) {
return findNode(root, prefix, 0);
}
private TernaryNode findNode(TernaryNode TernaryNode, String prefix, int index) {
if (prefix == null || prefix.equals("")) {
return null;
}
if (TernaryNode == null) {
return null;
}
char[] charArray = prefix.toCharArray();
// 如果当前字符小于当前节点存储的字符,查找左节点
if (charArray[index] < TernaryNode.storedChar) {
return findNode(TernaryNode.leftNode, prefix, index);
}
// 如果当前字符大于当前节点存储的字符,查找右节点
else if (charArray[index] > TernaryNode.storedChar) {
return findNode(TernaryNode.rightNode, prefix, index);
} else {// 相等
// 递归终止条件
if (index !=charArray.length - 1) {
return findNode(TernaryNode.centerNode, prefix, ++index);
}
}
return TernaryNode;
}
}
package chinese.utility.ternaryTree;
import java.io.BufferedWriter;
import java.io.IOException;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import chinese.utility.comparator.PinyinComparator;
import chinese.utility.dictionary.Dictionary;
public class SortAndCompromise {
/**
* 用二分法对经过排序的字典折中处理,输出到新的文件中
*
* @param word
* @param left
* @param right
* @param newWord
* @throws IOException
*/
public void outputBalanced(BufferedWriter fp, List<String> k, int offset, int n) throws IOException {
int m;
if (n < 1) {
return;
}
m = n >> 1; // m=n/2
String item = k.get(m + offset);
fp.write(item);
fp.newLine();
fp.flush();
outputBalanced(fp, k, offset, m); // 输出左半部分
outputBalanced(fp, k, offset + m + 1, n - m - 1); // 输出右半部分
}
/**
* 排序和折中处理,以便外部调用
*
* @param originalWord
* @param word
* @return
* @throws Exception
*/
public void sortAndCompromise(List<String> originalWords, BufferedWriter writer) throws Exception {
// 从字典中读取汉字,加载到list中
Dictionary dict = Dictionary.getInstance();
originalWords = dict.addToListFromDict(originalWords);
// 对list中的汉字排序
Comparator<String> comparator = new PinyinComparator();
Collections.sort(originalWords, comparator);
System.out.println("排序后的:" + originalWords);
// 折中处理,输出到新的文件当中
outputBalanced(writer, originalWords, 0, originalWords.size());
}
}
5.chinese.utility.test代码:
package chinese.utility.test;
import java.io.IOException;
import java.util.List;
import org.junit.Test;
import chinese.utility.comparator.PinyinComparator;
import chinese.utility.ternaryTree.TernaryNode;
import chinese.utility.ternaryTree.TernaryTree;
public class HanyuToPinyinTest {
PinyinComparator comparator = new PinyinComparator();
@Test
public void test() throws IOException {
// System.out.println(PinyinUtils.converterToSpell("重复").toLowerCase());
// System.out.println(PinyinUtils.converterToSpell("康师傅").toLowerCase());
// String []strs = PinyinUtils.pinyin('重');
// Arrays.sort(strs,comparator);
// for (String s : strs) {
// System.out.println(s);
// }
TernaryTree tree = new TernaryTree();
tree.insert("cq");
tree.insert("重庆");
List<TernaryNode> result = tree.prefixCompletion("cq");
for (TernaryNode node : result) {
System.out.println(node.token);
}
}
}
package chinese.utility.test;
import java.util.Comparator;
import org.junit.Assert;
import org.junit.Test;
import chinese.utility.comparator.PinyinComparator;
public class PinyinComparatorTest {
private Comparator<String> comparator = new PinyinComparator();
/**
* 常用字
*/
@Test
public void testCommon() {
Assert.assertTrue(comparator.compare("孟", "宋") < 0);
}
/**
* 不同长度
*/
@Test
public void testDifferentLength() {
Assert.assertTrue(comparator.compare("他奶奶的", "他奶奶的熊") < 0);
}
/**
* 和非汉字比较
*/
@Test
public void testNoneChinese() {
Assert.assertTrue(comparator.compare("a", "阿") < 0);
Assert.assertTrue(comparator.compare("1", "阿") < 0);
Assert.assertTrue(comparator.compare("b","阿") < 0);
}
/**
* 非常用字(怡)
*/
@Test
public void testNoneCommon() {
Assert.assertTrue(comparator.compare("怡", "张") < 0);
}
/**
* 同音字
*/
@Test
public void testSameSound() {
Assert.assertTrue(comparator.compare("怕", "帕") == 0);
}
/**
* 多音字(曾)
*/
@Test
public void testMultiSound() {
Assert.assertTrue(comparator.compare("曾经", "曾迪") > 0);
}
}
package chinese.utility.test;
import java.util.List;
import chinese.utility.dictionary.Dictionary;
import chinese.utility.ternaryTree.TernaryNode;
public class Test {
public static void main(String[] args) throws Exception {
Dictionary dictionary = Dictionary.getInstance();
//加载主字典
dictionary.loadDict();
//查找前缀匹配的词语
List<TernaryNode> result = dictionary.prefixCompletion("中");
for (TernaryNode node : result) {
System.out.print(node.token+" ");
}
}
}
6.chinese.utility.utils代码:
package chinese.utility.utils;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import net.sourceforge.pinyin4j.PinyinHelper;
import net.sourceforge.pinyin4j.format.HanyuPinyinCaseType;
import net.sourceforge.pinyin4j.format.HanyuPinyinOutputFormat;
import net.sourceforge.pinyin4j.format.HanyuPinyinToneType;
import net.sourceforge.pinyin4j.format.exception.BadHanyuPinyinOutputFormatCombination;
/**
* 汉语转拼音
* @author TongXueQiang
* @date 2016/03/07
* @since JDK 1.8
*/
public class PinyinUtils {
/**
* 汉字转换为汉语拼音首字母,英文字符不变
* @param chines 汉字
* @return 拼音
*/
public static String converterToFirstSpell(String chines){
String pinyinName = "";
//转化为字符
char[] nameChar = chines.toCharArray();
//汉语拼音格式输出类
HanyuPinyinOutputFormat defaultFormat = new HanyuPinyinOutputFormat();
//输出设置,大小写,音标方式等
defaultFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE);
defaultFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
for (int i = 0; i < nameChar.length; i++) {
//如果是中文
if (nameChar[i] > 128) {
try {
pinyinName +=
PinyinHelper.toHanyuPinyinStringArray(nameChar[i], defaultFormat)[0].charAt(0);
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
}else{//为英文字符
pinyinName += nameChar[i];
}
}
return pinyinName;
}
/**
* 汉字转换位汉语拼音,英文字符不变
* @param chines 汉字
* @return 拼音
*/
public static String converterToSpell(String chines){
String pinyinName = "";
char[] nameChar = chines.toCharArray();
//输出设置,大小写,音标方式等
HanyuPinyinOutputFormat defaultFormat = new HanyuPinyinOutputFormat();
defaultFormat.setCaseType(HanyuPinyinCaseType.UPPERCASE);
defaultFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
for (int i = 0; i < nameChar.length; i++) {
if (nameChar[i] > 128) {
try {
pinyinName += PinyinHelper.toHanyuPinyinStringArray(nameChar[i], defaultFormat)[0];
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
}else{
pinyinName += nameChar[i];
}
}
return pinyinName;
}
/**
* 得到一个字符的多音
* @param c
* @return
*/
public static String [] pinyin(char c){
return PinyinHelper.toHanyuPinyinStringArray(c) == null ? null : PinyinHelper.toHanyuPinyinStringArray(c);
}
public static List<String> getPermutationSentence(List<List<String>> termArrays,int start) {
if (CollectionUtils.isEmpty(termArrays))
return Collections.emptyList();
int size = termArrays.size();
if (start < 0 || start >= size) {
return Collections.emptyList();
}
if (start == size-1) {
return termArrays.get(start);
}
List<String> strings = termArrays.get(start);
List<String> permutationSentences = getPermutationSentence(termArrays, start + 1);
if (CollectionUtils.isEmpty(strings)) {
return permutationSentences;
}
if (CollectionUtils.isEmpty(permutationSentences)) {
return strings;
}
List<String> result = new ArrayList<String>();
for (String pre : strings) {
for (String suffix : permutationSentences) {
result.add(pre+suffix);
}
}
return result;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号