
Java并发包同步组件StampedLock
引言
在上一章我们了解了ReentrantReadWriteLock读写锁,它实现了多个读操作之间不再被相互等待阻塞,但是读操作和写操作之间,写操作和写操作之间依然还是会被相互阻塞。另外,ReentrantReadWriteLock读写锁有个很致命的缺陷,那就是当读多写少的时候将可能会存在写线程饥饿问题导致写线程一直不能获取到写锁,数据更新被无期限的推迟,这里我们开始学习另一种同步锁StampedLock,它是JDK8才新增的一种同步锁,它被认为是ReentrantReadWriteLock读写锁的改进版本,它能够进一步实现读不阻塞写,但是写还是会阻塞任何其他写和读。StampedLock的这种不再阻塞写的读就叫做“乐观读”,从而解决了读写锁的写饥饿问题。
StampedLock基本原理
通过Java Doc我们可以很直接的了解到StampedLock提供了三种模式的读写锁,所谓的三种模式其实就是当我们调用不同方式的获取读/写锁的方法成功后,StampedLock锁处于的不同状态。不同于ReentrantReadWriteLock读写锁在调用获取锁的方法lock()时返回值为void,在调用tryLock()方法时返回boolean型仅表示成功失败,StampedLock在调用获取锁的方法时,返回的是一个long型的用于表示和控制StampedLock锁状态的变量stamp(邮戳),并且在释放锁的时候也需要以此变量stamp作为参数,另外StampedLock锁的状态是由一个版本号和当前的读写模式组成。StampedLock提供的三种读写模式如下:
(1)读模式: 当执行readLock/readLockInterruptibly/tryReadLock方法成功时,就是读模式,为了区别另一种“乐观读模式”,这种读也被称为“悲观读”或“普通读”,它和ReentrantReadWriteLock提供的读锁一样也是一种共享锁,会阻塞其他写入操作,但不会阻塞其他读操作。只要当前锁不是被写入持有,普通读锁就能成功获取。适用于“读少写多”。
(2)乐观读:当执行tryOptimisticRead方法时,就是乐观读模式,乐观读可以说就是StampedLock的精髓,也是解决普通读写锁带来的写饥饿问题的根本。只要当前锁不是被写入持有,乐观读锁就能成功获取。乐观读锁在获取的过程中,并没有进行CAS操作设置锁的状态,只是判断当前没有线程持有写锁,就简单的返回一个非0的stamp版本信息,然后再将需要操作的字段拷贝到本地方法栈,再对这些需要操作的字段真正进行操作之前,还需要执行validate()方法来确认是否在乐观读锁被获取之后至今,是否有其他线程持有了写锁,如果有则需要获取悲观读锁然后进行重读,否则就可以使用该stamp版本的锁对数据进行操作。由此可见乐观读确实不会阻塞写操作获取写锁,并且乐观读适用于读多写少的场景。由于乐观读随时都可能被一个写入者打断(尤其是在完成了对一个对象或者一个数组的引用的读取之后,在接下来每一次访问它的成员/方法或元素的时候,我们都需要执行validate()来确保是否能够继续往下进行),所以乐观读模式可以被看做是一种弱版本的读锁,也正因为如此,乐观读模式只有在用于耗时极短的读取操作时经常能够降低竞争和提高吞吐量。另外,乐观读这种重读机制,并不能完全保证数据的一致性,所以它只能用于当你非常熟悉如何检测数据一致性或者通过重复执行validate()来进行一致性检测的场景。
(3)写模式: 当执行writeLock/writeLockInterruptibly/tryWriteLock方法成功时,就是写模式,它和ReentrantReadWriteLock提供的写锁一样也是一种独占锁,当锁被写模式所占有,任何读/写或者乐观读操作都不能够成功。已经成功的乐观读锁执行validate()也将会返回失败。并且只有当目前没有线程持有读锁或者写锁的时候才可以获取到该锁,综合起来就是读锁,乐观读锁,写锁都会阻塞写锁,写锁也会阻塞读,乐观读和其他写。
ReentrantReadWriteLock不支持锁升级,StampedLock不但提供了锁升级的功能,还提供了在以上三种模式之间进行有条件的转换:tryConvertToWriteLock、tryConvertToReadLock、tryConvertToOptimisticRead。这些方法的设计也是为了降低代码膨胀。
StampedLock是不可重入的。所以这也导致了使用StampedLock依赖于对数据、对象和方法的内部属性有一定的了解,不用担心在第一次成功获取锁之后,在未释放锁之前,执行了一些未知的可能存在执行重入的操作的方法,如果那样的话,可能将导致死锁。一个stamp如果在很长时间都没有使用或验证,在很长一段时间之后可能就会验证失败。StampedLocks是可序列化的,但是反序列化后变为初始的非锁定状态,所以在远程锁定中是不安全的。
StampedLock的调度策略没有为读或写操作提供优先机制,所有以try开头的非阻塞式获取锁的方法都是尽最大努力获取锁,并不一定遵循任何调度或公平策略。从"try"方法获取或转换锁失败返回0时,不会携带任何锁的状态信息。
由于StampedLock支持跨多个锁模式的协调使用,Lock和ReadWriteLock接口并不能满足它的实现需要,所以StampedLock并没有直接实现这两个接口。但是,如果应用程序确实需要Lock/ReadWriteLock的相关功能,还是可以通过asReadLock()、asWriteLock()和asReadWriteLock()方法来返回一个Lock或者ReadWriteLock的视图,从而完成相应的功能。
JDK示例
接下来,我们通过JDK自身提供的一个对二维空间的点的示例来展示对StampedLock的使用。
1 class Point { 2 private double x, y; //成员变量,一个点的x,y坐标 3 private final StampedLock sl = new StampedLock(); //锁实例 4 5 void move(double deltaX, double deltaY) { 6 long stamp = sl.writeLock();//获取一个独占锁,写锁 7 try { 8 x += deltaX; 9 y += deltaY; 10 } finally { 11 sl.unlockWrite(stamp);//释放排它锁 12 } 13 } 14 15 double distanceFromOrigin() { //计算到原点的距离 16 long stamp = sl.tryOptimisticRead(); //尝试获取乐观读锁(1) 17 double currentX = x, currentY = y; //将需要操作的变量拷贝到本地方法栈(2) 18 if (!sl.validate(stamp)) { //检查在(1)获取到乐观读锁至今,有没有其他线程获取了独占写锁 19 stamp = sl.readLock(); //如果发现有写锁被获取,那么我们就悲观的认为数据已经被修改了,需要重读 20 //这里使用了必须等待写执行完的阻塞式悲观读锁readLock, 21 //其实也可以在循环中不断进行获取乐观读锁以及validate的机制来实现重读 22 try { 23 //重新将最新的值读取过来 24 currentX = x; 25 currentY = y; 26 } finally { 27 sl.unlockRead(stamp);//释放悲观读锁 28 } 29 } 30 //返回计算结果 31 return Math.sqrt(currentX * currentX + currentY * currentY); 32 } 33 34 void moveIfAtOrigin(double newX, double newY) { //如果在原地就移动到新的位置 35 //这里使用了悲观读,其实也可以使用乐观读+validate的机制代替 36 long stamp = sl.readLock(); 37 try { 38 while (x == 0.0 && y == 0.0) {//如果在原点就移动 39 //尝试在现有的读锁基础上直接升级为写锁 40 //0,升级写锁失败;非0,升级写锁成功 41 long ws = sl.tryConvertToWriteLock(stamp); 42 if (ws != 0L) {//成功升级到写锁, 43 stamp = ws; //更新票据 44 x = newX; //设置坐标值 45 y = newY; 46 break; //退出循环 47 }else { 48 //读锁升级写锁失败则:释放读锁,显式地获取独占写锁,然后循环重试 49 sl.unlockRead(stamp); 50 stamp = sl.writeLock(); 51 } 52 } 53 } finally { 54 sl.unlock(stamp); //释放锁 55 } 56 } 57 }
如上述代码,官方的例子还是很全面的,把普通读,乐观读,写锁,以及锁转化都囊括了进去。使用起来还是很简单的。由上面的示例也可以看出对乐观读锁的使用规则必须保证是这样的:
1 long stamp = lock.tryOptimisticRead(); //非阻塞获取乐观读锁 2 copyVaraibale2ThreadMemory();//拷贝变量到线程本地堆栈 3 if(!lock.validate(stamp)){ // 校验 4 long stamp = lock.readLock();//校验失败,申请获取阻塞式读锁 5 try { 6 copyVaraibale2ThreadMemory();//重新拷贝变量到线程本地堆栈 7 } finally { 8 lock.unlock(stamp);//释放悲观读锁 9 } 10 11 } 12 useThreadMemoryVarables();//使用线程本地堆栈里面的数据进行操作
源码分析
先从StampedLock类的一些常量和内部类开始吧,因为在后文将会大量的使用到这些常量或者属性:
1 public class StampedLock implements java.io.Serializable { 2 /** 处理器的个数,用于控制自旋的次数 */ 3 private static final int NCPU = Runtime.getRuntime().availableProcessors(); 4 5 /**线程在获取锁失败之后,进入等待队列之前自旋的最大次数 */ 6 private static final int SPINS = (NCPU > 1) ? 1 << 6 : 0; //64 7 8 /**头节点在获取锁的最大自旋次数 */ 9 private static final int HEAD_SPINS = (NCPU > 1) ? 1 << 10 : 0; //1024 10 11 /**头节点再次阻塞前的最大自旋次数 */ 12 private static final int MAX_HEAD_SPINS = (NCPU > 1) ? 1 << 16 : 0; //65536 13 /**等待自旋锁溢出的周期数 */ 14 private static final int OVERFLOW_YIELD_RATE = 7; // must be power 2 - 1 15 16 /**在溢出之前读线程计数器用到的bit位数 */ 17 private static final int LG_READERS = 7; 18 19 // 下面这些是用于操作锁状态或者stamp变量的一些常量 20 private static final long RUNIT = 1L; //读锁计数器单位 21 private static final long WBIT = 1L << LG_READERS; //写锁被占用的标识:1000 0000,128 22 private static final long RBITS = WBIT - 1L; //读锁状态标志位:0111 1111, 127 23 private static final long RFULL = RBITS - 1L;//读锁最大资源数:0111 1110, 126 24 private static final long ABITS = RBITS | WBIT;//用于获取锁状态的变量:1111 1111, 255 25 private static final long SBITS = ~RBITS; // ....1111 1000 0000,SBITS就是除了低7位为0,其余高位全部为1 26 27 // 锁状态初始值,第9位位1: 10000 0000 ,256 28 private static final long ORIGIN = WBIT << 1; 29 30 // 中断标识,用于抛出中断异常 31 private static final long INTERRUPTED = 1L; 32 33 // 节点状态:等待/取消 34 private static final int WAITING = -1; 35 private static final int CANCELLED = 1; 36 37 // 节点的读写模式,使用int类型而不是boolean是为了能够算术运算 38 private static final int RMODE = 0; 39 private static final int WMODE = 1; 40 41 /** 等待队列节点类 */ 42 static final class WNode { 43 volatile WNode prev; 44 volatile WNode next; 45 volatile WNode cowait; // 专门用于链接等待读的线程队列 46 volatile Thread thread; // 当前线程 47 volatile int status; // 节点的状态:0代表初始值将被重置为-1即WAITING, 1代表CANCELLED 48 final int mode; // 等待读还是等待写,RMODE or WMODE 49 //节点构造器,两个参数:读写模式和前驱节点 50 //注意在构造节点的时候,并没有立即设置thead属性为当前线程,而是在park之前才设置 51 //在构造节点的时候,也没有立即设置节点的状态,所以新节点的状态为0 52 WNode(int m, WNode p) { mode = m; prev = p; } 53 } 54 55 /** 等待队列的头节点 */ 56 private transient volatile WNode whead; 57 /** 等待队列的尾节点 */ 58 private transient volatile WNode wtail; 59 60 // 获取Lock/ReadWriteLock类型的锁时的视图 61 transient ReadLockView readLockView; 62 transient WriteLockView writeLockView; 63 transient ReadWriteLockView readWriteLockView; 64 65 /** 当前锁的状态 */ 66 private transient volatile long state; 67 /** 当读锁计数器溢出RFULL=126之后,额外用于存放读锁计数器的变量 */ 68 private transient int readerOverflow; 69 70 //StampedLock构造方法,初始化结果只有第9位为1,其他都是0,表示无锁状态 71 public StampedLock() { 72 state = ORIGIN; //10000 0000,256 73 } 74 .......此处省略 75 }
通过上面StampedLock类的一些基本信息,可以看到,StampedLock并没有直接实现Lock/ReadWriteLock接口,其实它甚至也没有使用AbstractQueuedSynchronizer来实现,但是它还是基于了AQS的思想:它里面也使用WNode将等待线程封装成了等待队列中的节点来进行线程调度,同样使用了Unsafe的park以及unpark来进行挂起和唤醒线程操作。
对于维护锁状态的变量state,StampedLock使用了一个64位的long型结构存储,初始状态为从右往左的第9位为1,低位的8位全部为0表示无任何读写锁状态,当处于写锁状态时,第8位为1,当普通读时,只用低7位来表示(1~126)悲观读数量,当超出了这7位表示的数量126,再用另一个int类型的readerOverflow来表示悲观读的数量。其实对于写锁的每一次释放,对于state变量来说都不会被还原到最初的值了,而是每次释放都会通过增加128来向高位进位,以达到避免ABA的问题,这个在稍后的乐观读锁的获取时会进行详细分析。
一、悲观读readLock
1 public long readLock() { 2 long s = state, next; 3 //队列为空,并且(s & ABITS) < RFULL时即无写锁,并且当前读锁数量没有溢出126才直接尝试获取读锁 4 // 1 XXXX XXXX & 0 1111 1111 < 126,要使这个成立,只有 state < 126时才成立 5 // 条件成立时,尝试将读锁计数器加1,所以第126个成功获取读锁的线程,其实也是由state保存的。 6 // 第127个尝试获取读锁的计数器就需要由溢出计数器存储。 7 return ((whead == wtail && (s & ABITS) < RFULL && 8 U.compareAndSwapLong(this, STATE, s, next = s + RUNIT)) ? 9 next : acquireRead(false, 0L)); 10 }
readLock是阻塞式获取悲观读锁的入口方法,很简单只有在队列为空,并且不存在写锁,当前读锁个数小于126时才会立即尝试获取悲观读锁,否则执行入队操作acquireRead。
1 private long acquireRead(boolean interruptible, long deadline) { 2 WNode node = null, p; 3 for (int spins = -1;;) {//第一个自旋操作 4 WNode h; 5 if ((h = whead) == (p = wtail)) { //队列为空 6 for (long m, s, ns;;) { //自旋内循环 7 //赋值运算符优先级最低,m = s & ABITS,其实就是取state的低8位 8 //首先如果既无写锁被占用,而且读锁数量没有超过126就直接尝试获取读锁(1) 9 //否则,m < WBIT时(表示没有写锁被占用),执行tryIncReaderOverflow尝试将读锁数量溢出部分记录到溢出字段上去(2) 10 if ((m = (s = state) & ABITS) < RFULL ? 11 U.compareAndSwapLong(this, STATE, s, ns = s + RUNIT) : 12 (m < WBIT && (ns = tryIncReaderOverflow(s)) != 0L)) 13 return ns;//(1)或(2)成功之后,返回 14 else if (m >= WBIT) {//写锁被占用 15 if (spins > 0) { 16 if (LockSupport.nextSecondarySeed() >= 0) 17 --spins;//随机递减自旋数 18 }else { 19 if (spins == 0) { 20 //如果一直尝试获取失败,或者有其他线程进入队列,退出内循环,准备加入等待队列 21 WNode nh = whead, np = wtail; 22 if ((nh == h && np == p) || (h = nh) != (p = np)) 23 break; 24 } 25 spins = SPINS;//初始化自旋周期,64 26 } 27 } 28 } 29 } 30 if (p == null) { 31 // 队列为空时,初始化队列,专门额外创建了一个写模式的节点作为头节点同时也是尾节点 32 WNode hd = new WNode(WMODE, null); 33 if (U.compareAndSwapObject(this, WHEAD, null, hd)) 34 wtail = hd; 35 } 36 else if (node == null) 37 //为本次获取锁的线程创建节点,前驱为队列的尾节点 38 node = new WNode(RMODE, p); 39 else if (h == p || p.mode != RMODE) { 40 //如果队列为空,或者现在的尾节点不是读线程,就把当前读线程节点加入队尾 41 if (node.prev != p) 42 node.prev = p; 43 else if (U.compareAndSwapObject(this, WTAIL, p, node)) { 44 p.next = node; 45 break; //成功加入到队尾,退出第一个自旋 46 } 47 }//队列不为空,并且其尾节点是一个读线程的节点,就把当前节点挂载到它的cowait链上去 48 else if (!U.compareAndSwapObject(p, WCOWAIT,node.cowait = p.cowait, node)) 49 node.cowait = null; 50 else { //执行到这,说明成功将当前节点挂载到读模式的尾节点的cowait链上,node成为cowait中的顶元素,cowait构成了一个LIFO队列。 51 for (;;) { //又一个自旋内循环 52 WNode pp, c; Thread w; 53 if ((h = whead) != null && (c = h.cowait) != null && 54 U.compareAndSwapObject(h, WCOWAIT, c, c.cowait) && 55 (w = c.thread) != null) //辅助唤醒现任头节点cowait链上的读线程,若有的话 56 U.unpark(w); 57 if (h == (pp = p.prev) || h == p || pp == null) { 58 //当前节点的前驱已经是最有效的头节点或者队列空了甚至自己已经是头节点了,总之就是自己差不多已经有资格获取锁了 59 long m, s, ns; 60 do { //若写锁没被占用,就尝试获取读锁, 61 //同时若读锁数量溢出126了,就将读锁数量溢出部分记录到溢出字段上去 62 if ((m = (s = state) & ABITS) < RFULL ? 63 U.compareAndSwapLong(this, STATE, s, ns = s + RUNIT) : 64 (m < WBIT && (ns = tryIncReaderOverflow(s)) != 0L)) 65 return ns; //成功返回 66 } while (m < WBIT); 67 } 68 if (whead == h && p.prev == pp) {//到这里说明暂时还没有希望能够获取锁, 69 long time; 70 if (pp == null || h == p || p.status > 0) { 71 node = null; // 若队列有变化或有节点取消了,退出内循环重新开始 72 break; 73 } 74 //开始执行阻塞当前线程,等待唤醒了 75 if (deadline == 0L) //deadline为0,无限等待 76 time = 0L; 77 else if ((time = deadline - System.nanoTime()) <= 0L) 78 return cancelWaiter(node, p, false); //若超时了,取消等待 79 Thread wt = Thread.currentThread(); 80 U.putObject(wt, PARKBLOCKER, this); //设置当前线程被当前对象阻塞的标识 81 node.thread = wt; 82 if ((h != pp || (state & ABITS) == WBIT) && 83 whead == h && p.prev == pp) //条件一大堆,总之就是队列和写锁没有任何变化,自己必须进入阻塞 84 U.park(false, time); //阻塞呗 85 node.thread = null; 86 U.putObject(wt, PARKBLOCKER, null); //被唤醒之后,清除掉节点对应的线程和阻塞标识 87 if (interruptible && Thread.interrupted()) //若被中断并且需要响应中断,就取消等待 88 return cancelWaiter(node, p, true); 89 } 90 } 91 } 92 } 93 //从第一个自旋跳出,说明当前节点被加入到了正常队列的尾部 94 for (int spins = -1;;) {//第二个自旋 95 WNode h, np, pp; int ps; 96 if ((h = whead) == p) {//若当前线程的节点的前驱为头节点,表明可能下一个马上就会轮到了 97 if (spins < 0) 98 spins = HEAD_SPINS;//设置自旋次数,1024 99 else if (spins < MAX_HEAD_SPINS)//新一轮自旋还没有超出最大自旋次数65536 100 spins <<= 1;//自旋次数每一次增加2倍,spins = spins * 2 101 for (int k = spins;;) { // 在头节点处自旋 102 long m, s, ns; 103 if ((m = (s = state) & ABITS) < RFULL ? 104 U.compareAndSwapLong(this, STATE, s, ns = s + RUNIT) : 105 (m < WBIT && (ns = tryIncReaderOverflow(s)) != 0L)) { 106 //若写锁没被占用,以CAS获取到锁或将溢出记录到溢出字段上的方式获取到读锁 107 WNode c; Thread w; 108 whead = node; 109 node.prev = null; 110 while ((c = node.cowait) != null) { //将等待在当前节点cowait链上的等待读线程全部唤醒 111 if (U.compareAndSwapObject(node, WCOWAIT,c, c.cowait) && 112 (w = c.thread) != null) 113 U.unpark(w); 114 } 115 return ns; //成功返回 116 } //若前驱是一个写线程,那么就随机递减自旋 117 else if (m >= WBIT && LockSupport.nextSecondarySeed() >= 0 && --k <= 0) 118 break; 119 } 120 }//当前节点的前驱非头节点,依次唤醒头节点的cowait队列中那些读线程,若有的话 121 else if (h != null) { 122 WNode c; Thread w; 123 while ((c = h.cowait) != null) { 124 if (U.compareAndSwapObject(h, WCOWAIT, c, c.cowait) && 125 (w = c.thread) != null) 126 U.unpark(w); 127 } 128 } 129 if (whead == h) {//若还是没能获取到读锁,并且头节点没变化 130 if ((np = node.prev) != p) {//检查前驱是否被改变 131 if (np != null)//若前驱发生变化,重新设置新的前驱的next指向自己 132 (p = np).next = node; //也会使p变量指向新的前驱 133 } 134 else if ((ps = p.status) == 0)//若前驱节点状态为0(新节点),将其设置成WAITING(-1)状态 135 U.compareAndSwapInt(p, WSTATUS, 0, WAITING); 136 else if (ps == CANCELLED) {//若前驱节点取消了等待,重新调整当前节点的前驱 137 if ((pp = p.prev) != null) { 138 node.prev = pp; 139 pp.next = node; 140 } 141 } 142 else {//找好了正常的前驱节点,开始考虑阻塞当前线程等待唤醒 143 long time; 144 if (deadline == 0L) 145 time = 0L; 146 else if ((time = deadline - System.nanoTime()) <= 0L) 147 return cancelWaiter(node, node, false); 148 Thread wt = Thread.currentThread(); 149 U.putObject(wt, PARKBLOCKER, this); 150 node.thread = wt; 151 if (p.status < 0 && 152 (p != h || (state & ABITS) == WBIT) && 153 whead == h && node.prev == p) 154 U.park(false, time);//阻塞吧 155 node.thread = null; 156 U.putObject(wt, PARKBLOCKER, null); 157 if (interruptible && Thread.interrupted())//如果被中断并且需要响应中断,就取消等待 158 return cancelWaiter(node, node, true); 159 } 160 } 161 } 162 } 163 private long tryIncReaderOverflow(long s) { 164 //没有写锁被占用,读锁数量达到了低7位所限制的最大数126 165 if ((s & ABITS) == RFULL) { 166 // s | RBITS => 0111 1110 |0111 1111 => 0111 1110=126 167 //将state超过 RFULL=126的值放到readerOverflow字段中,state保持不变 168 if (U.compareAndSwapLong(this, STATE, s, s | RBITS)) { 169 ++readerOverflow; 170 state = s; 171 return s; //成功将溢出部分读锁计数器放到readerOverflow之后,返回非0的值 172 } 173 } //否则锁状态发生了变化,例如写锁被占用或读锁被释放等,就随机出让CPU 174 else if ((LockSupport.nextSecondarySeed() & OVERFLOW_YIELD_RATE) == 0) 175 Thread.yield(); 176 return 0L;//失败 返回0 177 }
- 首先,在队列为空,无写锁占用,并且读锁数量没溢出126时直接尝试获取读锁,成功返回最新的stamp变量(第9位为1,第8位为0,后7位记录读锁数量:1 0XXX XXXX),失败进入第一个自旋;
- 在第一个自旋中,若队列为空,就在随机递减的自旋中不断尝试获取读锁,若读锁数量溢出,会将溢出部分记录到溢出字段,成功返回最新的stamp变量(若溢出返回值恒为126);
- 在第一个自旋中,若操作(2)的自旋没有成功获取读锁或队列有变化,就需要做入队操作了:若当时队列尾节点是一个读模式的,就把当前节点加入到它的cowait链中,否则将当前节点直接设置成队列新的尾节点并退出第一个自旋;
- 在第一个自旋中,若操作(3)将当前节点加入的是cowait链,那么就在此处进行阻塞/唤醒机制的尝试获取读锁,只要队列空了或当前节点或其前驱成为了新的头节点,就会尝试获取读锁。
- 在第一个自旋中,若操作(3)将当前节点加入的是等待队列的尾节点,那么进入第二个自旋;
- 在第二个自旋中,当前节点会阻塞直到其前驱成为了新的头节点,然后在头节点处进行随机递减自旋中不断尝试获取读锁,成功的话会唤醒其cowait链中的读线程,失败继续阻塞。
1 //三个参数,node表示需要被清理的当前节点,interrupted为true表示发生需要处理的中断,为false表示超时 2 //group表示需要被清理的当前节点或者它所在的一组cowait的组节点 3 private long cancelWaiter(WNode node, WNode group, boolean interrupted) { 4 if (node != null && group != null) { 5 Thread w; 6 node.status = CANCELLED;//修改节点状态为“取消” 7 //依次移除掉组节点cowait链中已经“取消”的节点 8 for (WNode p = group, q; (q = p.cowait) != null;) { 9 if (q.status == CANCELLED) { 10 U.compareAndSwapObject(p, WCOWAIT, q, q.cowait); 11 p = group; // restart 12 } 13 else 14 p = q; 15 } 16 if (group == node) { 17 //group == node说明取消的是等待队列中的节点(写模式),也是cowait组节点的根节点(读模式) 18 //如果是读模式,依次唤醒cowait链中所以节点(肯定是非取消状态,因为取消状态的节点已经被清理了) 19 for (WNode r = group.cowait; r != null; r = r.cowait) { 20 if ((w = r.thread) != null) 21 U.unpark(w); 22 } 23 for (WNode pred = node.prev; pred != null; ) { //节点前继不为空 24 WNode succ, pp; 25 //后继为空时会直接将当前队列的尾节点置为其前驱,就是把自己给清理掉了 26 //后继已经取消时,重新设置有效的后继,会清理掉当前节点至最近的有效后继之间的无效节点 27 while ((succ = node.next) == null || succ.status == CANCELLED) { 28 WNode q = null; 29 //从对尾往前找到离自己最近的一个有效节点 30 for (WNode t = wtail; t != null && t != node; t = t.prev) 31 if (t.status != CANCELLED) q = t; 32 //若有效后继有变化就重新设置新的有效后继节点 33 if (succ == q || U.compareAndSwapObject(node, WNEXT, succ, succ = q)) { 34 if (succ == null && node == wtail) //若当前节点已经是尾节点了,就设置其前驱为新的尾节点 35 U.compareAndSwapObject(this, WTAIL, node, pred); 36 break;//后继无变化或后继重新设置成功退出while循环 37 } 38 } 39 if (pred.next == node) 40 //说明已经设置好了新的后继节点,直接再将新的有效后继置为其前驱的后继,其实就是把自己也清理掉了 41 U.compareAndSwapObject(pred, WNEXT, node, succ); 42 if (succ != null && (w = succ.thread) != null) { 43 succ.thread = null; 44 U.unpark(w); //唤醒后继节点代表的线程 45 } 46 if (pred.status != CANCELLED || (pp = pred.prev) == null) 47 break; //如前驱节点正常有效退出循环 48 //运行到这里说明前驱是一个不为空的已经取消的节点,所以也要继续对其进行清理 49 node.prev = pp; //这里是为了下一次for寻找中的while循环找后继做准备 50 //将当前节点的无效前驱也清理掉,直接设置为当前节点的有效后继节点 51 U.compareAndSwapObject(pp, WNEXT, pred, succ); 52 pred = pp;//为下一次for循环做准备 53 } 54 } 55 } 56 //运行到这里,说明整个等待队列该清理的节点被清理干净 57 WNode h; 58 while ((h = whead) != null) { //头节点不为空 59 long s; WNode q; 60 //头节点的后继节点为空或已经取消,寻找离它最近的有效后继节点 61 if ((q = h.next) == null || q.status == CANCELLED) { 62 for (WNode t = wtail; t != null && t != h; t = t.prev) 63 if (t.status <= 0) 64 q = t; 65 } 66 if (h == whead) { //队列稳定无变化 67 if (q != null && h.status == 0 && //新后继有效 68 ((s = state) & ABITS) != WBIT && // 1 XXXX XXXX & 0 1111 1111 != 0 1000 0000 ==> 写锁没被占用 69 (s == 0L || q.mode == RMODE)) //锁状态为0?或 后继节点为读线程 70 release(h); //唤醒头节点的后继节点 71 break; 72 } 73 } 74 //最后根据中断情况返回中断标记给上层用于处理中断 75 return (interrupted || Thread.interrupted()) ? INTERRUPTED : 0L; 76 } 77 78 private void release(WNode h) { 79 if (h != null) { 80 WNode q; Thread w; 81 U.compareAndSwapInt(h, WSTATUS, WAITING, 0);//更改节点状态为0,允许失败 82 //查找离节点最近的有效后继节点 83 if ((q = h.next) == null || q.status == CANCELLED) { 84 for (WNode t = wtail; t != null && t != h; t = t.prev) 85 if (t.status <= 0) 86 q = t; 87 } 88 //唤醒有效后继节点代表的线程 89 if (q != null && (w = q.thread) != null) 90 U.unpark(w); 91 } 92 }
二、写锁writeLock
1 public long writeLock() { 2 long s, next; 3 // state & ABITS =>> 1 XXXX XXXX & 0 1111 1111,只有在state为1 0000 0000即无任何锁的时候才为0 4 //即无任何锁时才尝试获取写锁,获取成功,state + WBIT, 其实就是在初始化256的基础上将第8位也置为1. 5 return ((((s = state) & ABITS) == 0L && 6 U.compareAndSwapLong(this, STATE, s, next = s + WBIT)) ? 7 next : acquireWrite(false, 0L)); 8 }
writeLock是StampedLock获取写锁的入口方法,很简单只有当不存在任何读写锁时,才通过CAS尝试获取写锁,获取成功设置state为1 1000 0000,即384并返回,否则都执行acquireWrite方法,进行入队操作。
1 private long acquireWrite(boolean interruptible, long deadline) { 2 WNode node = null, p; 3 for (int spins = -1;;) { // 入队前的自旋行为 4 long m, s, ns; 5 if ((m = (s = state) & ABITS) == 0L) { //如果不存在任何读写锁,再次尝试获取写锁 6 if (U.compareAndSwapLong(this, STATE, s, ns = s + WBIT)) 7 return ns; //成功返回 8 }else if (spins < 0) //首次自旋,如果写锁已经被其他线程占用且队列为空,就根据CPU核心数设置自旋次数 9 spins = (m == WBIT && wtail == whead) ? SPINS : 0; 10 else if (spins > 0) {//自旋进行中,获取一个随机数之后,递减自旋次数。 11 if (LockSupport.nextSecondarySeed() >= 0)//这里恒成立 12 --spins; 13 }else if ((p = wtail) == null) { // 自旋次数为0,并且队列为空时,初始化队列 14 WNode hd = new WNode(WMODE, null); 15 //专门额外创建了一个写模式的节点作为头节点同时也是尾节点 16 if (U.compareAndSwapObject(this, WHEAD, null, hd)) 17 wtail = hd; 18 }else if (node == null) //为本次获取锁的线程创建节点,前驱为队列的尾节点 19 node = new WNode(WMODE, p); 20 else if (node.prev != p)//操作过程中,如果队列发生了变化,重新设置前驱为新的尾节点 21 node.prev = p; 22 else if (U.compareAndSwapObject(this, WTAIL, p, node)) {//尝试加入对尾 23 p.next = node; 24 break; // 入队成功,跳出自旋 25 } 26 } 27 //执行第二个自旋的时候,node表示当前线程的节点,p节点表示当前节点的前驱 28 for (int spins = -1;;) {//入队后的自旋行为 29 WNode h, np, pp; int ps; 30 if ((h = whead) == p) {//如果当前线程的节点的前驱为头节点,表明可能下一个马上就会轮到了 31 if (spins < 0) 32 spins = HEAD_SPINS; //设置自旋次数,1024 33 else if (spins < MAX_HEAD_SPINS) //新一轮自旋还没有超出最大自旋次数65536 34 spins <<= 1; //自旋次数每一次增加2倍,spins = spins * 2 35 for (int k = spins;;) { // 在头节点处自旋 36 long s, ns; 37 if (((s = state) & ABITS) == 0L) { //如果不存在任何读写锁,再次尝试获取写锁 38 if (U.compareAndSwapLong(this, STATE, s, ns = s + WBIT)) { 39 whead = node; //成功,更新头节点为当前节点 40 node.prev = null; 41 return ns; //返回 42 } 43 }else if (LockSupport.nextSecondarySeed() >= 0 && //这个随机数永远都大于0 44 --k <= 0) //随机递减 45 break; 46 } 47 }else if (h != null) { //若当前节点的前驱非头节点,依次唤醒头节点的cowait队列中那些读线程 48 WNode c; Thread w; 49 while ((c = h.cowait) != null) { 50 if (U.compareAndSwapObject(h, WCOWAIT, c, c.cowait) && 51 (w = c.thread) != null) 52 U.unpark(w); 53 } 54 } 55 //走到这里说明,当前节点的前驱不是头节点或者超过了自旋最大次数都没能成功获取写锁,并且头节点还没被改变 56 if (whead == h) { 57 if ((np = node.prev) != p) { //检查前驱是否被改变 58 if (np != null) //若前驱发生变化,重新设置新的前驱的next指向自己 59 (p = np).next = node; //也会使p变量指向新的前驱 60 } 61 else if ((ps = p.status) == 0) //若前驱节点状态为0(新节点),将其设置成WAITING(-1)状态 62 U.compareAndSwapInt(p, WSTATUS, 0, WAITING); 63 else if (ps == CANCELLED) { //若前驱节点取消了等待,重新调整当前节点的前驱 64 if ((pp = p.prev) != null) { 65 node.prev = pp; 66 pp.next = node; 67 } 68 }else { 69 //找好了正常的前驱节点,开始考虑阻塞当前线程等待唤醒 70 long time; 71 if (deadline == 0L) // deadline为0无限等待 72 time = 0L; 73 else if ((time = deadline - System.nanoTime()) <= 0L) //超时了,取消等待 74 return cancelWaiter(node, node, false); 75 Thread wt = Thread.currentThread(); 76 U.putObject(wt, PARKBLOCKER, this); //设置当前线程被当前对象阻塞的标识 77 node.thread = wt; //设置当前节点对应的线程 78 if (p.status < 0 && (p != h || (state & ABITS) != 0L) && 79 whead == h && node.prev == p) //条件一大堆,总之就是队列和写锁没有任何变化,自己必须进入阻塞 80 U.park(false, time); //阻塞吧 81 node.thread = null; //被唤醒之后,清除掉节点对应的线程和阻塞标识 82 U.putObject(wt, PARKBLOCKER, null); 83 if (interruptible && Thread.interrupted()) //如果被中断并且需要响应中断,就取消等待 84 return cancelWaiter(node, node, true); 85 } 86 } 87 } 88 }
有了对悲观读锁的分析,对写锁的理解就很简单了,它的逻辑和悲观读锁的获取过程非常相似,而且还更简单,也由两个主要的自旋操作构成,其整个过程大致是这样的:
- 首先,在不存在任何悲观读锁和写锁时才会通过CAS直接尝试获取写锁,成功返回写锁标识的stamp变量(第9位,第8位都为1,其他低7位都为0,即十进制384),失败进入第一个自旋;
- 在第一个自旋中,首先再次在不存在任何读写锁的情况尝试获取写锁,否则在写锁被占用队列为空的情况下,进行随机递减的自旋操作;
- 在第一个自旋中,若步骤(2)未能成功获取写锁时,就将其作为新的尾节点直接入队。之后进入第二个自旋;
- 在第二个自旋中,若当前节点的前驱为头节点,就会在随机递减的自旋中不断尝试获取写锁,失败或者前驱不是头节点那么就进行阻塞等待被唤醒。
- 在第二个自旋中,若超时或发生了需要被响应的中断,依然使用cancelWaiter方法进行清理及善后工作。
而且有意思的是在获取悲观读和写锁的过程中,都会有意识的辅助头节点唤醒它的cowait链中的读线程。阻塞式的读写锁获取方法在成功获取相关的锁之后都会返回一个反应锁信息的long型stamp变量,这个返回值对于上层调用者来说基本上是没有什么作用的,主要是为了用于作为释放锁的参数,通过对读写锁的分析,我们大致也可以得出它对整个等待队列的维护结构如下:
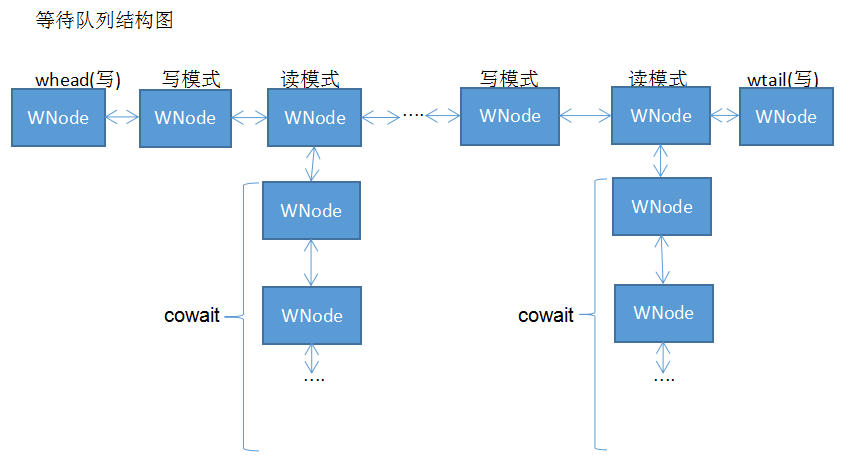
三、乐观读tryOptimisticRead
1 public long tryOptimisticRead() { 2 //WBIT为写锁标识:1000 0000,所以state 按位与 WBIT 只有当表示写锁被占用的第8位是1的时候,才不等于0 3 //所以当写锁被占用时,返回0,否则第8位为0,第9位不变,其余位表示读锁数量 4 //state & SBITS =》 1 0XXX XXXX & ...1111 1000 0000,所以结果一定是10000 0000,即初始值256 5 long s; 6 return (((s = state) & WBIT) == 0L) ? (s & SBITS) : 0L; 7 } 8 //乐观读stamp验证 9 public boolean validate(long stamp) { 10 U.loadFence();//使用LoadLoad屏障,禁止将之前的读取成员属性的操作重排序到后面的验证逻辑之后 11 //根据上面,stamp要么为0(写锁被占用),要么为256;为0时,stamp & SBITS还是0;为256时,stamp & SBITS还是256, 12 //现在state被写锁占用时,state & SBITS=》...0001 1000 0000 & ...1111 1000 0000=256+128 =384 13 //现在state没被写锁占用时,state & SBITS=》 1 0XXX XXXX & ...1111 1000 0000 = 256 14 return (stamp & SBITS) == (state & SBITS); 15 }
写锁的释放
1 public void unlockWrite(long stamp) { 2 WNode h; 3 if (state != stamp || (stamp & WBIT) == 0L) //状态是否是期望的状态 4 throw new IllegalMonitorStateException(); 5 //将写标记位清零,如果state发生溢出,则退回到初始值。 6 state = (stamp += WBIT) == 0L ? ORIGIN : stamp; //对state进行了更新 7 if ((h = whead) != null && h.status != 0) 8 release(h); 9 }
四、锁转换
前面说过, StampedLock支持三种方式的锁转换:tryConvertToWriteLock、tryConvertToReadLock、tryConvertToOptimisticRead。这里以tryConvertToWriteLock为例:
1 public long tryConvertToWriteLock(long stamp) { 2 long a = stamp & ABITS, m, s, next; 3 while (((s = state) & SBITS) == (stamp & SBITS)) {//锁状态无变化 4 if ((m = s & ABITS) == 0L) { //无任何读写锁 5 if (a != 0L) //发现存在读或者写锁,升级失败退出 6 break; 7 if (U.compareAndSwapLong(this, STATE, s, next = s + WBIT)) //尝试获取写锁 8 return next; 9 } 10 else if (m == WBIT) {//已经是写锁 11 if (a != m) //写锁发生变化,升级失败退出 12 break; 13 return stamp;//写锁无变化,成功 14 } 15 else if (m == RUNIT && a != 0L) {//只存在一个读线程 16 if (U.compareAndSwapLong(this, STATE, s, next = s - RUNIT + WBIT))//直接释放读并该成写锁 17 return next; 18 } 19 else 20 break; 21 } 22 return 0L; 23 }
五、其他方法
至于StampedLock其他的一些方法,例如支持中断/超时机制,非阻塞式的获取悲观读写锁的方法,获取Lock或者ReadWriteLock视图方法,对悲观读写锁的释放方法,检测锁状态的等等方法,就不再一一分析,通过以上基本的源码分析我们已经能够对StampedLock的原理有大致的了解了。
需要注意的是,那些以“try”开头的支持中断/超时机制的非阻塞式获取悲观读/写锁的方法,他们的返回值虽然也是一个long型的stamp变量,这个变量却不像阻塞式获取锁的方法返回的stamp那样只是用于锁释放的参数。而是多了另一层能够给予上层调用者验证是否获取锁成功的含义,那就是当返回值为0时表示获取锁失败。
释放锁的方法中还有两个特别的方法tryUnlockRead/tryUnlockWrite,它们不需要接受stamp参数来进行锁释放,而是固定的释放一个读/写锁,此方法可能对出现异常/错误后的恢复很有用,而且它们的返回值也是一个直接表示成功与否的boolean型变量。
存在的问题
问题1,在不支持中断及超时的悲观读写锁获取过程中readLock/writeLock,若写锁被占用期间,读锁在进入阻塞之前或之后被中断(反过来,如读锁被占用期间,中断了写锁也一样会出现该问题),导致在执行park的时候立即返回然后导致自旋操作不断被重复执行,CPU占用率疯狂上升,直到占用的写锁(反过来,就是读锁)被释放为止,示例代码如下:
1 public class TestStampedLock { 2 public static void main(String[] args) throws InterruptedException { 3 final StampedLock lock = new StampedLock(); 4 new Thread() { 5 public void run() { 6 long readLong = lock.writeLock();//写锁先被占用, 7 LockSupport.parkNanos(6000000000L);//写锁被持有6秒 8 lock.unlockWrite(readLong); 9 } 10 }.start(); 11 Thread.sleep(100); 12 for (int i = 0; i < 3; ++i) 13 new Thread(new OccupiedCPUReadThread(lock)).start(); 14 } 15 16 private static class OccupiedCPUReadThread implements Runnable { 17 private StampedLock lock; 18 19 public OccupiedCPUReadThread(StampedLock lock) { 20 this.lock = lock; 21 } 22 23 public void run() { 24 //这里的中断也可以放到执行readLock之后,当然必须是另一个线程 25 Thread.currentThread().interrupt(); 26 long lockr = lock.readLock();// 27 System.out.println(Thread.currentThread().getName() + " get read lock"); 28 lock.unlockRead(lockr); 29 } 30 } 31 }
以上示例,在写锁被持有的6秒过程总,获取读锁的线程由于被中断所以在StampedLock的acquireRead里面的自旋中的park操作将立即返回,然后在for循环中获取读锁失败之后再次执行park,但是由于中断状态依然存在,所以park方法再次立即返回,进行不间断的自旋中,这三个线程在写锁没释放之前会不停的进入自旋操作,使CPU的占用率飙升。造成这个问题的罪魁祸首就是在acquireRead/acquireWrite方法中的类似这段代码:
1 if (interruptible && Thread.interrupted()) 2 return cancelWaiter(node, node, true);
Thread.interrupted()虽然可以清除中断状态,但是必须在interruptible为true(也就是支持中断的锁获取方法)时才会执行,在不支持中断的readLock/writeLock锁获取过程中,永远得不到执行,中断状态也就不能复位,park方法每一次都会立即返回,Java并发包的作者Doug Lea已经给出了修复:https://github.com/zuai/Hui/blob/master/StampedLock.java。其实就是将发生的中断状态保存并复位即可,修复的代码就是将这段罪魁祸首的代码替换成了下面这段代码:
1 boolean interrupted = false; 2 ..... 3 if(Thread.interrupted()){ //无论是否支持中断,这里都将得到执行,将中断复位 4 if(interruptible) 5 return cancelWaiter(node, p, true); 6 else 7 interrupted = true; //如果不支持中断就把中断标记保存下来,将来返回的时候将中断补上 8 }
最后的总结
StampedLock虽然是对可重入读写锁 ReadWriteLock的改进版本,但同时它也有不足ReadWriteLock的地方,所以并不能完全说我们可以在任何时候都能使用StampedLock替代ReadWriteLock:
- 不支持ReadWriteLock读写锁具备的可重入性,使用不当可能造成死锁;
- 在读少写多这种不适用乐观读的场景下,据说使用StampedLock的悲观读写锁反而没有直接使用ReadWriteLock的效率高;当然在这种情况下使用ReadWriteLock估计也没有直接使用synchronize关键字效率高;
- StampedLock提供的乐观读只用于耗时极短的读操作,并且写操作较少的场景时才能够降低竞争和提高吞吐量。
- 使用StampedLock的乐观读的时候还需要你对进行操作的数据有熟悉的认识,确保能够在数据发生变化时,能够通过重复执行validate()来进行数据一致性问题的发现与更正。
- StampedLock还存在一些隐藏的bug,使用不当会造成CPU超负荷运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号