Java同步数据结构之Map概述及ConcurrentSkipListMap原理
引言
前面介绍了CopyOnWriteArraySet,本来接着是打算介绍ConcurrentSkipListSet,无耐ConcurrentSkipListSet的内部实现其实是依赖一个ConcurrentSkipListMap实例实现的,所以必须先理解ConcurrentSkipListMap,因此我们不得不进入到Map家族。
Map概述
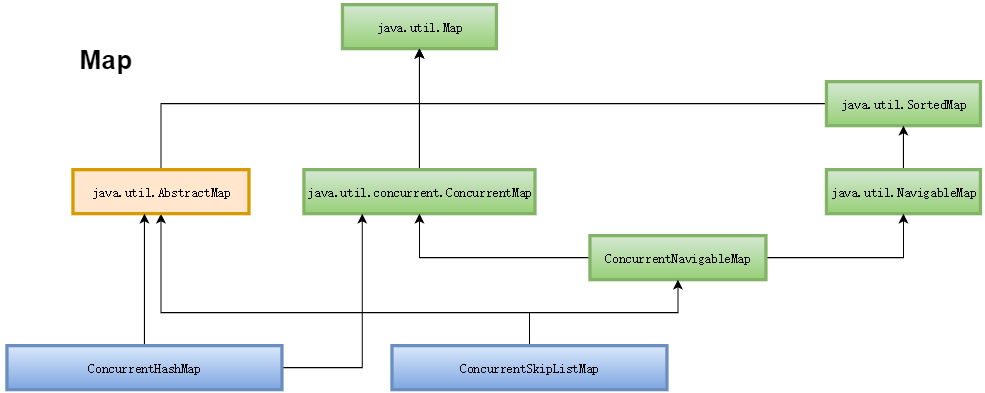
上图画出了Java并发包中关于Map的类结构图(Note: 绿色表示接口,蓝色表示实例类,黄色表示抽象类),并发包中只有4个与Map相关的类,其中两个接口:ConcurrentMap、ConcurrentNavigableMap,两个实例类:ConcurrentSkipListMap、ConcurrentHashMap。
java.util.SortedMap
SortedMap是一种可以根据键排序的Map,这种排序可以是自然排序,也可以按照指定的比较器排序,而这种顺序将反映在遍历迭代集合视图(由entrySet、keySet和values方法返回)时。插入SortedMap的键都必须是可比较的,并且所维护的顺序(无论是否显式提供比较器)必须与equals方法的结果一致。通常SortedMap的实现类都应该提供以下四个标准的构造方法:
①无参构造方法:创建一个按键的自然顺序排序的空SortedMap。②一个参数为Comparator类型的有参构造方法:创建一个根据指定的比较器排序的空SortedMap。
③一个参数为Map类型的有参构造方法:创建一个新的根据指定Map的键值初始化的自然排序的SortedMap。④一个参数为SortedMap类型的有参构造方法:创建一个新的根据指定SortedMap的键值和相同的排序规则初始化的SortedMap。
SortedMap还额外提供了一些返回具有受限键范围的子map视图方法,更改这些方法返回的子SortedMap将反映到原SortedMap,反之亦然。在返回的视图中插入超出其范围的键时将抛出IllegalArgumentException。SortedMap一些特殊的接口方法如下:


1 //返回用于该SortedMap中键排序的比较器,若是自然排序则返回null。 2 Comparator<? super K> comparator(); 3 4 //返回键在[fromKey, toKey)范围内的子视图,fromKey与toKey相等则返回空map。并且更改该子视图将反映到原map,反之亦然。在返回的视图中插入超出其范围的键时将抛出IllegalArgumentException。 5 SortedMap<K,V> subMap(K fromKey, K toKey); 6 7 //返回键小于toKey的子视图,其特性与subMap一致。 8 SortedMap<K,V> headMap(K toKey); 9 10 //返回键大于等于fromKey的子视图,其特性与subMap一致。 11 SortedMap<K,V> tailMap(K fromKey); 12 13 K firstKey();//返回当前map中的第一个(最小)键。 14 K lastKey();//返回当前map中的第后一个(最大)键。
java.util.NavigableMap
NavigableMap是一种扩展支持“导航”的SortedMap,所谓的导航“Navigable”,其实就是可以根据指定的键返回大于或小于该键的键值对子视图集合。由于它是SortedMap的子接口,所以这种所谓的“导航”功能就建立在可以对键进行排序的基础上。它的方法 lowerEntry、floorEntry、ceilingEntry 和 higherEntry 分别返回小于、小于等于、大于等于、大于给定键的键值对的 Map.Entry 对象,如果没有这样的键,则返回null。类似地,方法 lowerKey、floorKey、ceilingKey 和 higherKey 只返回相应的键。所有这些方法是为查找定位而不是遍历而设计的。
NavigableMap还提供了可以返回逆序视图的方法,例如descendingMap 返回此map中所包含键值对的逆序视图。所有对该逆序视图Map的修改都将反映到原Map上,反之亦然。根据Java Doc,当对原Map的修改发生在遍历该逆序视图集合期间的话(除开通过迭代器自身的remove方法),遍历的结果将是未定义的,这里的未定义指什么?估计就是不正确吧。类似的,descendingKeySet只返回逆序的相应的键。而navigableKeySet则是返回默认的升序的键。通常升序操作比逆序性能更好。
此外,此接口还定义了 firstEntry、pollFirstEntry、lastEntry 和 pollLastEntry 方法,它们返回并且可以同时移除最小和最大的键值对,如果存在的话,否则返回 null。这些*Entry方法返回的键值对只是原Map中相应键值对的快照,因此通常不支持Entry.setValue 方法去改变原Map中对应的键值对本身。
NavigableMap还扩展了SortedMap中返回具有受限键范围的子map视图的方法,即可以接受用于描述是否包括(或不包括)下边界和上边界的附加参数。
ConcurrentMap
ConcurrentMap就是并发包提供的接口了,它是一种提供线程安全和原子性保证的Map。并且具有内存一致性:将对象放入 ConcurrentMap 之前的线程中的操作 happen-before 随后通过另一线程从 ConcurrentMap 中访问或移除该元素的操作。
它额外的提供一些其它方法,这些方面中由JDK8提供的相关lumdba方法说实话有点晦涩拗口啊。
1 //返回指定键映射到的值,如果此映射不包含键的映射,则返回defaultValue。 2 getOrDefault(key, defaultValue) 3 4 //如果当前Map不存在指定的键,就将该键值对加入Map,并返回原来的值,否则直接返回存在的键值。 5 V putIfAbsent(K key, V value); 6 7 //仅当当前Map存在给定的键和值,才删除该键值对,并返回true,否则返回false。 8 boolean remove(Object key, Object value); 9 10 //仅当当前Map存在给定的键和值,才替换键的值,并返回true,否则返回false。 11 boolean replace(K key, V oldValue, V newValue); 12 13 //仅当当前Map存在给定的键时,才替换键的值,并返回原来的值,否则返回null 14 V replace(K key, V value); 15 16 //如果指定的键尚未与值关联(或映射为null),则尝试使用给定的映射函数计算其值,并将其加入Map,除非为null。 17 //返回已经存在的相应键值或计算得出的键值,如果计算得出的键值为null则返回null。 18 V computeIfAbsent(key, Function) 19 20 //如果指定键的值存在且非null,则尝试根据给定键及其当前原键值计算出新键值。若新值不为null则替换相应的键值,并返回新值;否则移除原键值对,返回null 21 V computeIfPresent(key, BiFunction) 22 23 //尝试根据指定的键及其值计算出新的键值,新值不为null则替换原值,返回与指定键关联的新值,否则返回null 24 V compute(key, BiFunction) 25 26 //尝试如果指定的键尚未与值关联或与null关联,则将其与给定的非null值value关联,并返回非null的value。 27 //否则,将关联值替换为根据原值和给定value通过给定函数计算的结果,并返回该新值,如果结果为空,则删除关联值返回null。 28 //此方法可用于组合键的多个映射值。 29 V merge(key, value,BiFunction)
ConcurrentNavigableMap
顾名思义,就是结合了ConcurrentMap和NavigableMap的一种线程安全的支持NavigableMap的Map。并且其返回的子视图也是ConcurrentNavigableMap类型。该接口没有定义新的接口方法,仅仅是重新将相关方法的返回值声明成了ConcurrentNavigableMap类型。
ConcurrentSkipListMap原理
ConcurrentSkipListMap是并发包提供的ConcurrentNavigableMap接口的实现类。ConcurrentSkipListMap是一个可伸缩的并发ConcurrentNavigableMap实现,该Map可以根据键的自然顺序进行排序,也可以根据创建Map时所提供的 Comparator 进行排序,具体取决于使用的构造方法。多个线程可以安全地并发执行插入、移除、更新和访问操作。
迭代器和可拆分迭代器是弱一致的,返回的元素将反映迭代器创建时或创建后某一时刻的映射状态。它们不抛出 ConcurrentModificationException,可以并发处理其他操作。升序操作的迭代器效率比逆序的迭代器更高。
此类那些返回Map.Entry 的方法,仅表示他们返回时的映射关系快照,不支持通过Entry.setValue更新原键值对。由于并发的原因,size大小将只是一个瞬间快照,此外批量操作 putAll、equals 和 clear 并不保证能以原子方式执行。与 putAll 操作一起并发操作的迭代器可能只能查看到部分新元素。
ConcurrentSkipListMap不允许使用null作为键或值,因为无法可靠地区分null返回值与不存在的元素值。
SkipList - 跳表原理
要理解ConcurrentSkipListMap不得不了解一下SkipList,从ConcurrentSkipListMap的类名就可以看出它和SkipList(俗称“跳表”)有关,没错它是实现了线程安全的SkipList变种,关于SkipList在网上的介绍比较多,它是一种随机化的数据结构,其数据元素按照key(键)排序,所以跳表是有序的集合,跳表为了提高查找、插入和删除操作的性能,在原有的有序链表之上随机的让一部分数据元素分布到更多层链表中,从而在查找、插入和删除操作时可以跳过一些不可能涉及的数据元素节点,从而提高效率。假设有如下一个有序链接(每个节点只有一个数据值和指向下一个节点的next指针):

如果我们需要查找12,22,36这三个元素我们每次只能从头开始遍历链表,直到查找到元素为止。明明是一个有序的链表我们却每次都只能一个一个的比较直到目标节点,调表的出现就解决了这种低效的查找方式。
跳表的查找
跳表会(随机)把一些节点提取出来,做成索引节点,下面就是一个拥有一级索引(索引节点拥有原基层节点的数据,指向右边索引节点的right指针,指向指向下层节点的down指针)的结构:

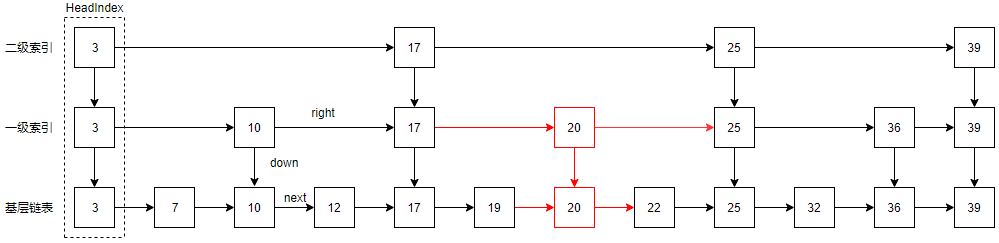
例如,现在我们再查找12这个元素,我们只需要从一级索引开始往后遍历,即经过3,10,发现后面的17比12大,则一级索引在10处往下走,再从下面的10往右走,就找到12了,是不是比以效率更高,因为跳过了一些不会涉及的节点。同样的,一级索引还可以继续往上提取一批节点组成二级索引:

例如,这时候我们要查找32这个元素,只需从二级索引开始往后遍历,经过3,17,25,发现后面的39大于32,则二级索引25往下走,发现其右边的一级索引36依然大于32,继续往下走,到达基层链表,25的右边刚好就是32了。总之跳表的查找的时候从底层索引的开始往后遍历,一旦发现下一个节点比目标节点大就降到下一层索引,移除类推,直到找到。
跳表的索引链表中的节点称之为“索引节点”,基层链表中的节点是“基准节点”,每一层的第一个节点称之为headIndex,即索引头节点,例如上图的节点3。上面讲述了跳表的基本结构了查找,下面看看插入节点的过程。
跳表的插入
假设我们现在要插入一个元素20,按照跳表的机制,它会先随机的确定该元素要占据的层数,假设level = 2,然后查找2在最下面2层(包含基层)的前置节点,就是刚好比它小一点的的节点,然后将其插入到它们的后面,最后就成这样了:
若level 大于当前链表的层,则需要添加新的层,例如level > 3, 则就成这样了:
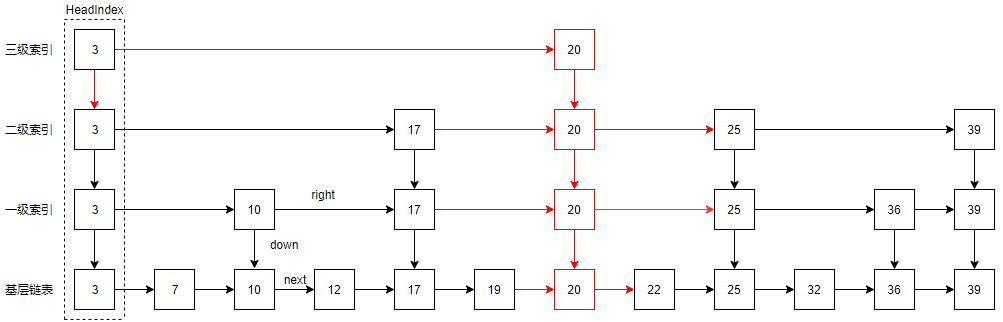
多出来的一层索引,只有headIndex和新插入的20.
跳表的删除节点
首先找到所有层中包含元素x的节点,然后使用标准的链表删除元素的方法删除即可。例如我们要删除元素25,则我们要删除三层中对应节点:
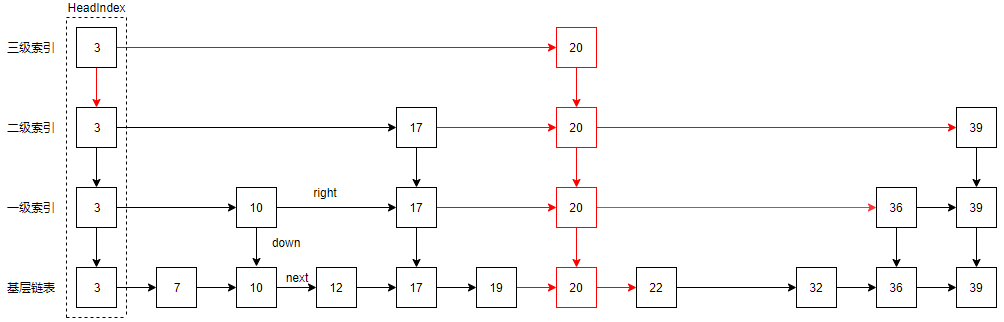
对比上面的图就可以发现,节点25被移除了。这里,若是我们要删除节点20,那么将会导致整个三级索引层都被移除,这种收缩性可以减少内存消耗。
通过上面对SkipList跳表的数据结构分析,我们可以看出它是一种以空间换时间的算法,它的效率和红黑树以及 AVL 树不相上下,但跳表的原理相当简单,只要你能熟练操作链表,就能轻松实现一个 SkipList,目前开源软件 Redis 和 LevelDB 都有用到它。
由上面对跳表的分析,可以得出其相关的如下特性:
跳表由许多层构成,并且每一层都是一个有序链表,但只有最底层(基层)包含所有元素。如果一个元素出现在level(x)层,那么它肯定出现在x以下的所有层中;每个元素插入时随机生成它将处于的level层;每个索引节点包含两个指针,一个向下,一个向右;而每个基层节点则只包含一个next指针;跳表是可以实现二分查找的有序链表;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号