
(转载)partition:执行在雾设备上的CNN模型划分_librahfacebook的博客-CSDN博客_cnn partition
partition:执行在雾设备上的CNN模型划分_librahfacebook的博客-CSDN博客_cnn partition 原文链接:https://blog.csdn.net/librahfacebook/article/details/96431901
partition:执行在雾设备上的CNN模型划分
本文出自论文 Partitioning of CNN Models for Execution on Fog Devices ,提出了一种新的针对CNN模型的深度输入划分方案,并通过实验来证明其良好性能。
深度神经网络的改进意味着广泛使用这种模型来分析和推理大量数据,包括传感器观察,图像和语音。对于这种在靠近数据源的设备上运行的推理任务的需求正在增长。这样的设备被放置在网络边缘,被称作雾设备,目的是为了减少上行网络流量。然而,现实中由于受到计算约束,在这样的设备上执行复杂的深度推理模型被证实很困难。因此引入了几个新的方法来划分或分配计算or数据到多个雾设备上。本文中,我们提出来一个新的针对CNN模型的深度输入划分方案,并通过实验证明到它能够获得较好的性能。
文章目录
- 一、简介
- 二、相关工作
- 三、模型划分
- 四、结论
一、简介
- 生成推理是处理体系结构的主要候选应用程序,因为处理更靠近源的数据可以保证较少的上行数据流量。在常用的边缘或雾设备中运行诸如Inception、Resnet、VGG等深度模型的主要挑战之一是每个模型的计算和内存需求。
- 在这项工作中,我们提出了一种方式来运行在一系列雾设备上卷积神经网络的深度推理操作,从而来实现高度推理。本文的主要共享点为:(1)一种新的深度输入划分方法,消除了与早期行列和网络划分方法相关的开销;(2)突出当前卷积层的输入和输出深度在分布式执行加速过程中的作用;(3)通过大量具有实际工作负载的模拟,来证明它在分布式执行中的作用。
二、相关工作
- 边缘计算(当前状态):低延迟(通过物理上的接近)、数据减少、可扩展性、隐私性和安全性正在推动着边缘计算的出现。雾和边缘计算的最初挑战主要是服务标准化、第三方供应商的集成、机密数据(信任和隐私)的处理以及货币化。
- DCNN加速和分布式执行:工作负载的划分是一种应用广泛的技术,我们的工作重点是寻找一种有效的机制,以无损的方式对CNNs的卷积层输入数据进行划分,从而增强上述技术。我们已经确定了两个较早的工作,综合处理卷积的分布式执行和CNN卷积层。其中,空间卷积是通过在一组并行计算机之间对图像进行分割来实现的。采用一种新的启发式分区策略对图像进行划分,该策略优于基于行/列的分区,且比基于网格的分区功能更强。一个详细的性能建模用来推动加速过程,并通过实验验证该模型。
- CNN通过图像分割和模型压缩来分布到真实的手机中。一个自适应分区策略被设计出来,使划分沿着较短的边缘,导致较少的开销像素被交换。这个主要贡献是识别出移动设备在不需要时关闭其收发器,因此这里有必要在分析分发加速时包括这一点。
- 先前的工作都没有分析处理大量输入和输出通道的效果,这正是当前最新CNNs的实际标准。基于以上分析,我们提出来一个无损深度图像分割方案,这个方案会导致更多的加速,并使CNNs更适合在雾或边缘的网格中运行。
三、模型划分
- 一种自适应分区方法,将基于容量的负载分配给工作节点,其中分区将沿着相对较大的维度进行。在最先进的CNNs中,深度尺寸对于实现高精度变得非常重要。先前研究图像操作的分布式执行工作,像在网络服务器和移动网格上的卷积操作,并没有分析处理大量输入和输出通道的效果。
- 在我们的工作中,我们分割了一个图像和一个过滤器沿着深度维度分布在雾资源。此外,我们还将所有过滤器分配到资源中,这种结果是一个无损失的分区。
- 性能建模(分布式卷积层):为了对卷积层分布式执行的性能建模,我们定义一个计算步骤:
OFMInt1[oh,ow,oc]=∑fh=1K∑fw=1FwF[fh,fw,ic,oc]I[oh+fh−1,ow+fw−1,ic]OFM_{Int1}[o_h,o_w,o_c]=\sum_{f_h=1}^{K}\sum_{f_w=1}^{F_w}F[f_h,f_w,i_c,o_c]I[o_h+f_h-1,o_w+f_w-1,i_c]OFMInt1[oh,ow,oc]=∑fh=1K∑fw=1FwF[fh,fw,ic,oc]I[oh+fh−1,ow+fw−1,ic],其中一个2D空间卷积以一种特别的输入和输出通道来执行。当我们在输入和输出通道水平级别处理输入IFM分区时,我们需要定义另一个基础的计算步骤,其中从上述公式产生的二维空间卷积沿着深度维度中进行求和运算。这样的步骤用如下公式进行定义:
OFMInt1[oh,ow,oc]=∑fh=1K∑fw=1FwF[fh,fw,ic,oc]I[oh+fh−1,ow+fw−1,ic]OFM_{Int1}[o_h,o_w,o_c]=\sum_{f_h=1}^{K}\sum_{f_w=1}^{F_w}F[f_h,f_w,i_c,o_c]I[o_h+f_h-1,o_w+f_w-1,i_c]OFMInt1[oh,ow,oc]=∑fh=1K∑fw=1FwF[fh,fw,ic,oc]I[oh+fh−1,ow+fw−1,ic]。 - 分布式设置包括一个主边缘设备,用于分区和分发数据(IFMs和过滤器),并最终合并来自边缘workers的部分解决方案。我们基于输入和输出通道将输入数据划分成n个边缘workers。我们假定资源是均匀分布的,并且IFMs也是均匀分布的,这是一个可行的假设,因为轻量级虚拟机(如容器、dockers)都可用于边缘平台,并可以扩展到基于容量的分区。

- 分布式执行要求多个时间:(1)TpartT_{part}Tpart:沿着主分支边缘上的通道创建IFMs分区的时间;(2)TtxT_{tx}Ttx:发送划分好的IFMs到边缘workers的时间;(3)TedgeT_{edge}Tedge:计算在所有边缘workers上的中间OFMs时间;(4)TrxT_{rx}Trx:将中间OFMs发送回主边缘的时间;(5)TjoinT_{join}Tjoin:合并中间OFMs输入通道并连接OFMs输出通道的时间。通过分布式方式执行卷积层操作所需要的时间为:Tcld=Tpart+n⋅(Ttx+Trx)+Tedge+TjoinT_{cld}=T_{part}+ n \cdot (T_{tx}+T_{rx})+T_{edge}+T_{join}Tcld=Tpart+n⋅(Ttx+Trx)+Tedge+Tjoin。
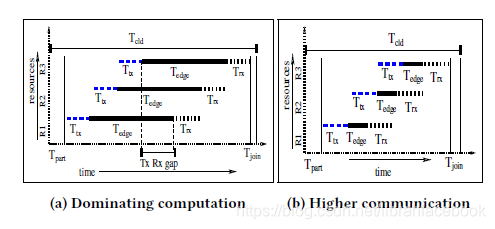
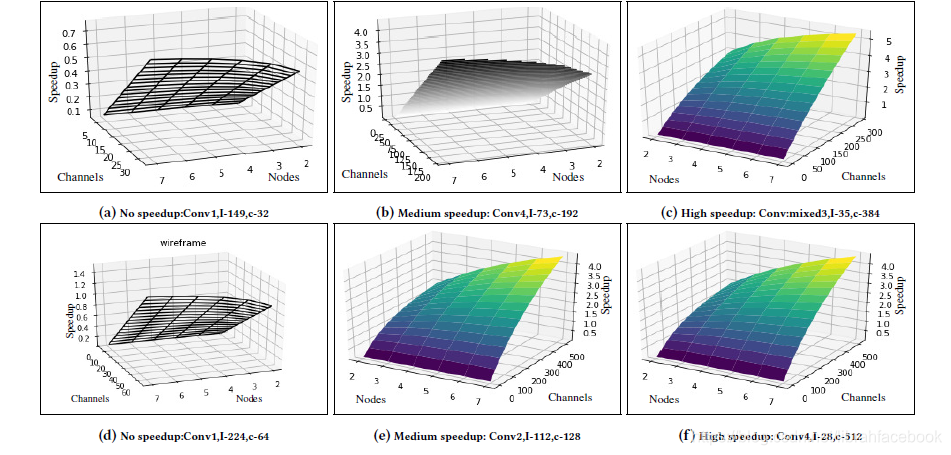
- 在分布式卷积层执行中,通过添加越来越多的边缘workers可以达到的最大加速范围被以下公式约束为:S=K2⋅c⋅f⋅γ(c+f)⋅(αM+β)S=\frac{K^2 \cdot c \cdot f \cdot \gamma }{(c+f) \cdot (\frac{\alpha}{M}+ \beta )}S=(c+f)⋅(Mα+β)K2⋅c⋅f⋅γ。可以推断出,加速极限不仅取决于计算时间和通信时间的比值,还取决于输入和输出深度。当输入和输出深度相当时,对S的影响最大。
- 我们通过测量全卷积层操作来计算这个计算步骤,然后通过该操作(input∗kernel∗in channelsinput*kernel*in channelsinput∗kernel∗in channels)来除。基于以上发现,我们开发了一种算法来计算预估的加速,该算法基于从边缘设备的计算能力,可用网络带宽和正在执行的卷积层的输入和输出深度。只有当估计的加速超过设定的阈值时,才会触发卷积层的分区执行过程。在我们的实验设置中,只有当通道数量超过60时我们才进行分区过程。
四、结论
使用位于网络边缘的受限fog/edge设备已经成为了现实,它可以执行离源更近的不同形式的数据,从而在与物联网和智能城市的多个方面相关的分析中实现智能推理。我们在本文中提出了一种新颖的基于深度的CNN模型输入分区方案,克服了当前行/列和网格分区方案的困难之处。另外,我们强调了当前卷积层的输入和输出深度在分布式执行实现过程的加速作用,并通过最先进的CNN模型中实际工作负载的大量模型验证中证实我们的方法。我们期待这里所提出的数据路径优化方案对于一个分布式计算层次结构,将同样适用于在FPGAs并行实现的DCNN和其他加速器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号