kafka及hdfs常用命令
1.kafka常用命令:
首先获取集群节点kafka相关位置,我用了比较原始的搜索办法:
find . -name 'kafka*' >kafka_path
找到并进入kafka根目录相关目录后执行kafka命令:
查看topic数:
bin/kafka-topics.sh --zookeeper hadoop3 --list #查看该节点下所有topic
建topic,分区,副本数:
bin/kafka-topics.sh --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181 --create --topic tablename --partitions 6 --replication-factor 2
分别为第1,2,3hadoop节点上创建topic tablename和6个分区和2个副本
查看topic描述信息:
bin/kafka-topics.sh --zookeeper hadoop1:2181/kafka --describe --topic tablename
查看topic的偏移量:
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list hadoop1:9090 --topic tablename
删除topic:
bin/kafka-topics.sh --delete --zookeeper hadoop1:2181/kafka --topic tablename
查看topic的partition的副本分布,可以在zookeeper中查看:
get /kafka/brokers/topics/my-replicated-topic
2. hdfs常用命令:
hdfs以文件形式存储数据,可通过hdfs命令查看相关文件信息,如:
hdfs dfs -fs hdfs://cluster2-hadoop01-tst-daas-deepexi:8020 -ls / 查看cluster2-tst-daas-deepexi:8020集群下hdfs文件信息
hdfs查看文件内容,如(-cat):
hdfs dfs -fs hdfs://cluster1-hadoop01-tst-daas-deepexi:8020 -cat /1.3.4/dolphinscheduler/hdfs/resources/1382580496453640273.json
查看hdfs服务器上某目录下文件夹个数,如:
hdfs dfs -fs hdfs://cluster1-hadoop01-tst-daas-deepexi:8020 -ls / |grep "^d"|wc -l

统计hdfs服务器上某目录下文件个数,如:
hdfs dfs -fs hdfs://cluster1-hadoop01-tst-daas-deepexi:8020 -count /

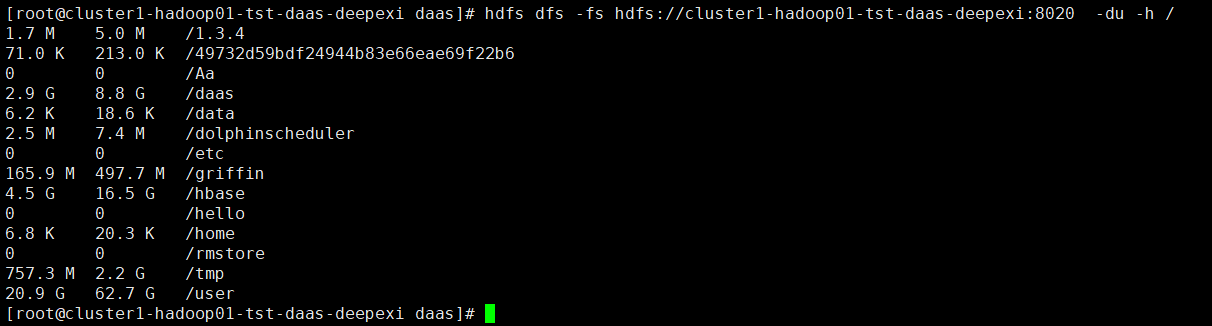
统计hdfs服务器上某文件大小,如:
hdfs dfs -fs hdfs://cluster1-hadoop01-tst-daas-deepexi:8020 -du -h /
常用命令参数:
功能:输出这个命令参数手册
-help
功能:显示目录信息
-ls
示例: hadoop fs -ls hdfs://hadoop-server01:9000/
备注:这些参数中,所有的hdfs路径都可以简写
-->hadoop fs -ls / 等同于上一条命令的效果
功能:在hdfs上创建目录
-mkdir
示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd
功能:从本地剪切粘贴到hdfs
-moveFromLocal
示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
功能:从hdfs剪切粘贴到本地
-moveToLocal
示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt
功能:追加一个文件到已经存在的文件末尾
--appendToFile
示例:hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt
可以简写为:
Hadoop fs -appendToFile ./hello.txt /hello.txt
功能:显示文件内容
-cat
示例:hadoop fs -cat /hello.txt
功能:显示一个文件的末尾
-tail
示例:hadoop fs -tail /weblog/access_log.1
功能:以字符形式打印一个文件的内容
-text
示例:hadoop fs -text /weblog/access_log.1
功能:linux文件系统中的用法一样,对文件所属权限
-chgrp
-chmod
-chown
示例:
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt
功能:从本地文件系统中拷贝文件到hdfs路径去
-copyFromLocal
示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
功能:从hdfs拷贝到本地
-copyToLocal
示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz
功能:从hdfs的一个路径拷贝hdfs的另一个路径
-cp
示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
功能:在hdfs目录中移动文件
-mv
示例: hadoop fs -mv /aaa/jdk.tar.gz /
功能:等同于copyToLocal,就是从hdfs下载文件到本地
-get
示例:hadoop fs -get /aaa/jdk.tar.gz
功能:合并下载多个文件
-getmerge
示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,...
hadoop fs -getmerge /aaa/log.* ./log.sum
功能:等同于copyFromLocal
-put
示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
功能:删除文件或文件夹
-rm
示例:hadoop fs -rm -r /aaa/bbb/
功能:删除空目录
-rmdir
示例:hadoop fs -rmdir /aaa/bbb/ccc
功能:统计文件系统的可用空间信息
-df
示例:hadoop fs -df -h /
功能:统计文件夹的大小信息
-du
示例:
hadoop fs -du -s -h /aaa/*
功能:统计一个指定目录下的文件节点数量
-count
示例:hadoop fs -count /aaa/
功能:设置hdfs中文件的副本数量
-setrep
示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz
<这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量>


 浙公网安备 33010602011771号
浙公网安备 33010602011771号