利用Python实现一个WC程序
项目要求
wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。
实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
基本功能列表
- wordCounter.exe -c file.c //返回文件 file.c 的字符数
- wordCounter.exe -w file.c //返回文件 file.c 的词的数目
- wordCounter.exe -l file.c //返回文件 file.c 的行数
扩展功能
- wordCounter.exe -s file //递归处理目录下符合条件的文件。
- wordCounter.exe -a file.c //返回更复杂的数据(代码行 / 空行 / 注释行)。
空行: 本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如`“{”`。
代码行:本行包括多于一个字符的代码。
注释行: 本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:
`} // 注释`,在这种情况下,这一行属于注释行。
fileName: 文件或目录名,可以处理一般通配符
3. -x 参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。
一、开发前PSP表格预估
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 40 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 630 | 750 |
| Development | 开发 | 400 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 30 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 240 | 300 |
| · Code Review | · 代码复审 | 40 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 50 | 40 |
| Reporting | 报告 | 60 | 60 |
| · Test Report | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 630 | 750 |
二、项目完成情况
编程语言:python
基本功能列表:
- wordCounter.exe -c file.c //返回文件 file.c 的字符数(实现)
- wordCounter.exe -w file.c //返回文件 file.c 的词的数目 (实现)
- wordCounter.exe -l file.c //返回文件 file.c 的行数(实现)
扩展功能:
- wordCounter.exe -s file //递归处理目录下符合条件的文件。(实现)
- wordCounter.exe -a file.c //返回更复杂的数据(代码行 / 空行 / 注释行)。(实现)
空行: 本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如`“{”`。
代码行:本行包括多于一个字符的代码。
注释行: 本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:
`} // 注释`,在这种情况下,这一行属于注释行。
fileName: 文件或目录名,可以处理一般通配符
3. -x 参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。(未实现)
三、项目设计
项目大致流程图:
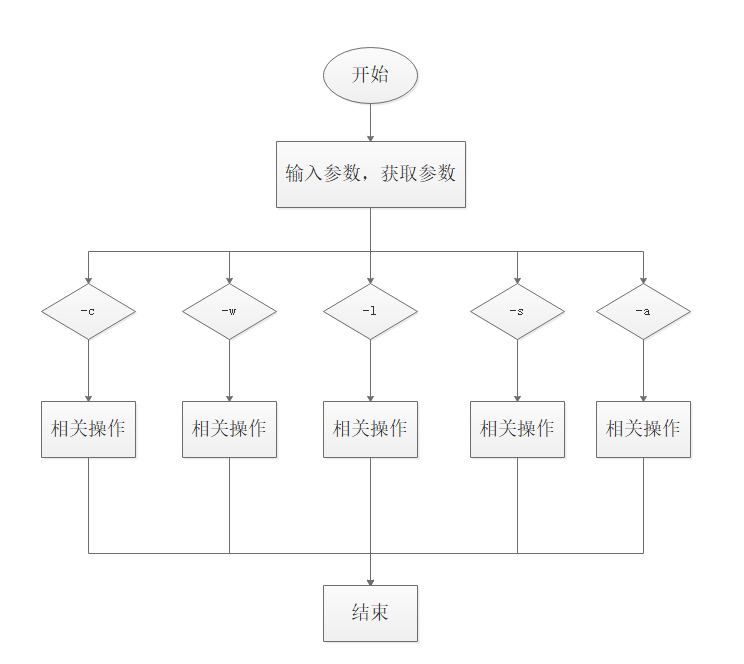
四、关键代码
RecurveDir 函数查找文件夹下符合条件的文件,使用`glob`类匹配输入的文件夹下的文件存在列表中,然后遍历文件列表,从中递归查找符合条件的文件。
def RecurveDir(dirPath): """ 递归查找符合条件的文件 :param: dirPath: 目录的路径 :return: 符合条件的文件 """ fileList = [] pathFileInfo = "*.*" pathList = glob.glob(os.path.join(dirPath, '*')) for mPath in pathList: if fnmatch.fnmatch(mPath, pathFileInfo): fileList.append(mPath) #print(fileList) elif os.path.isdir(mPath): #print(mPath) fileList += RecurveDir(mPath) else: pass return fileList
下面这段是统计代码行,空行,注释行的逻辑代码,需要考虑的情况挺多,有单行注释和多行注释等
with open(fileName, 'r', encoding = 'utf-8') as f: for index, line in enumerate(f, start=1): stripLine = line.strip() #判断多行注释是否开始 if not isComment: if stripLine.startswith("'''") or stripLine.startswith('"""') or stripLine.startswith('/*'): isComment = True startComment = index #单行注释,考虑多种情况 elif stripLine.startswith('#') or stripLine.startswith('//') or re.findall('^[}]+[\s\S]+[//]+', stripLine): commentLines += 1 elif stripLine == '' or stripLine == '{' or stripLine == '}': blankLines += 1 else: codeLines += 1 #多行注释已经开始 else: if stripLine.endswith("'''") or stripLine.endswith('"""') or stripLine.endswith('*/'): isComment = False commentLines += index -startComment + 1 else: pass
五、测试
运行 python wordCounter.py -h
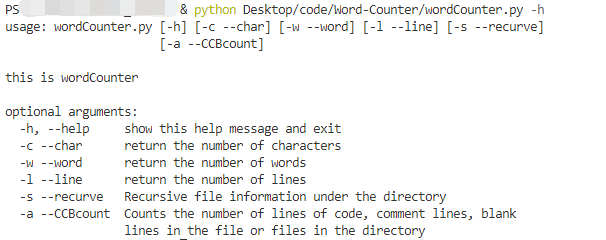
分别运行
python wordCount.py -c wordtest.txt python wordCount.py -w wordtest.txt python wordCounr.py -l wordtest.txt
结果:

运行:
python wordCount.py -s wordtest python wordCount.py -a wordtest python wordCount.py -a wordtest.txt
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号