andrew ng machine learning week1 课堂笔记
一、 什么是机器学习:两种定义
定义1:Arthur Samuel described it as: "the field of study that gives computers the ability to learn without being explicitly programmed." 机器学习就是赋予机器不用精确编程便能学习的能力。
定义2:Tom Mitchell provides a more modern definition: "A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."如果一个计算机程序针对任务T的表现P由于经验E的存在而被改善,我们说就这个程序关于任务T和表现P,对经验E进行了学习(这个翻译真的是有点绕口,简单说就是机器表现因为经验而得到改善,那么就说是机器从经验中学得)。
二、监督学习和无监督学习:Supervised Learning and unsupervised Learning

三、模型表示

他们之间的关系以及经典房价预测问题中假设的定义(单变量线性回归)
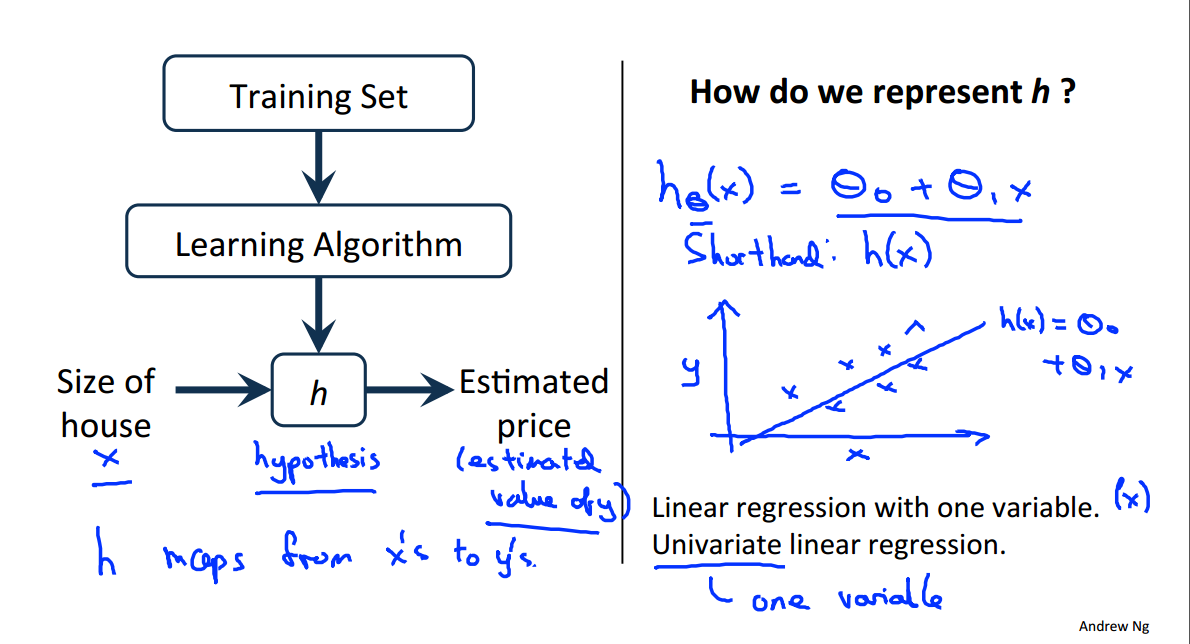

问题是参数的选取,我们应该尽可能地让假设值与真实值接近,也是就是最小化我们的代价函数,代价函数的定义如下。
四、代价函数cost function
This takes an average difference (actually a fancier version of an average) of all the results of the hypothesis with inputs from x's and the actual output y's.代价函数的意义是假设预测值与真实值之间的差异,这里是均方误差(Mean squared error)。
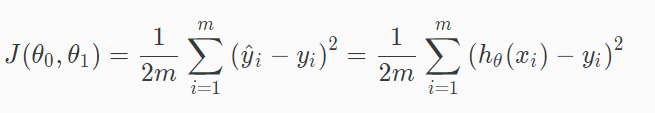
总结一下,这就是我们要解决的问题:
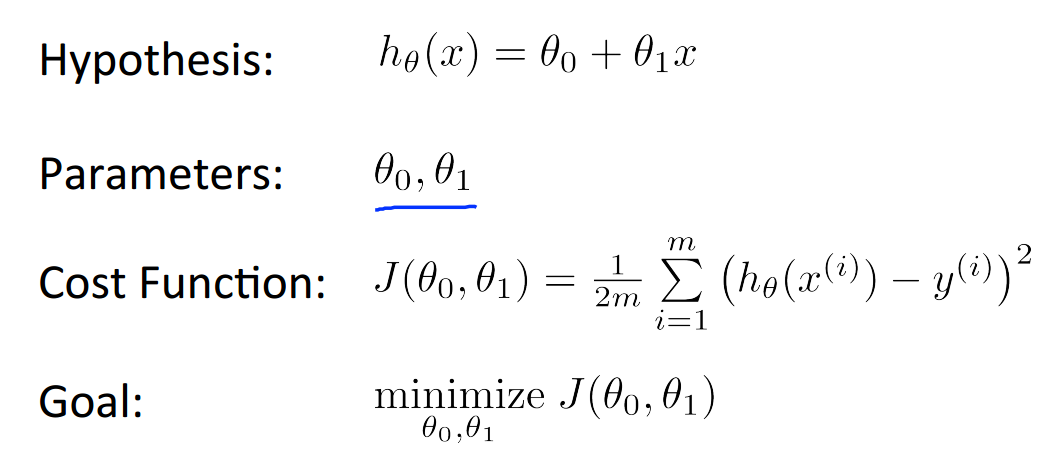
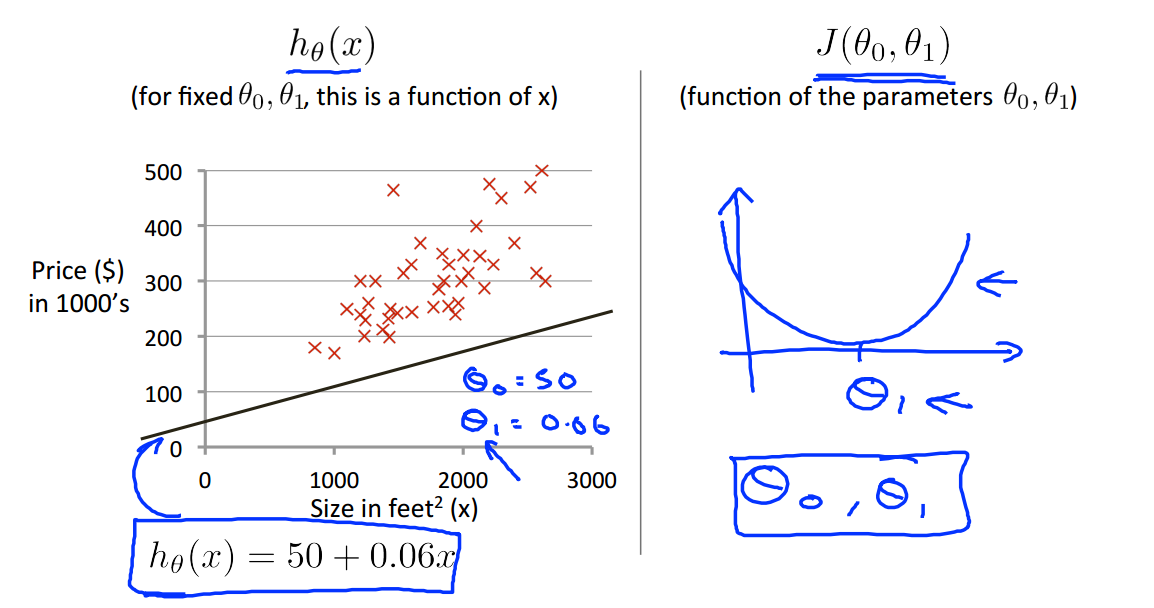
现在应该通过什么方法取得最优的参数使得代价函数J的值为极小值点呢?——梯度下降法
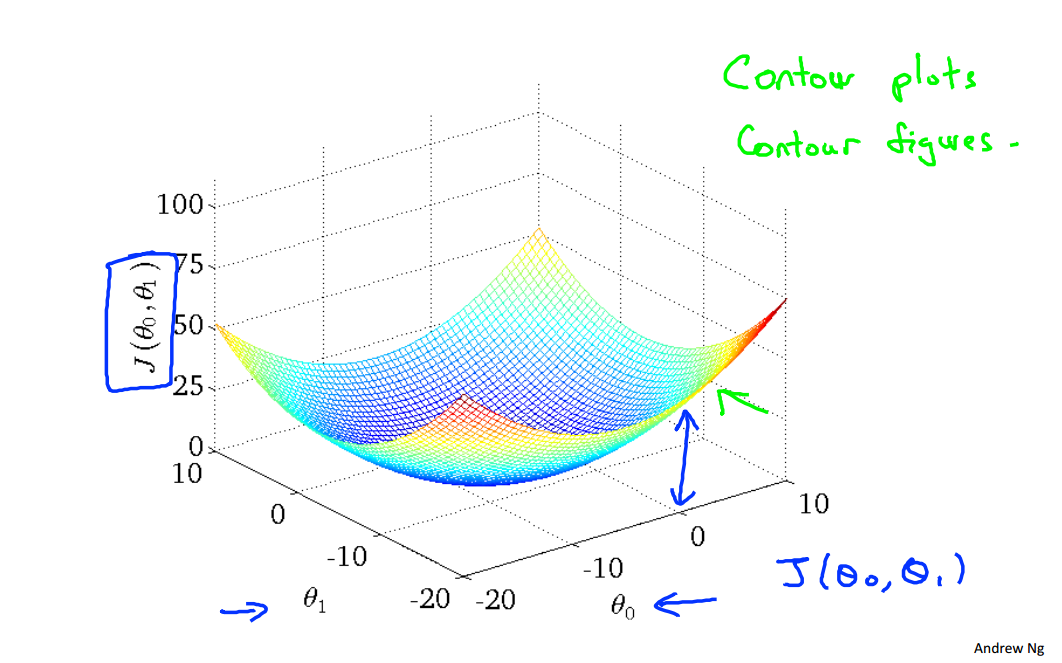

通过选取合适的参数,在等值线图中的中心点也就是最小值点,得到假设函数,从而进行其他房价的预测。
梯度下降法的大纲:
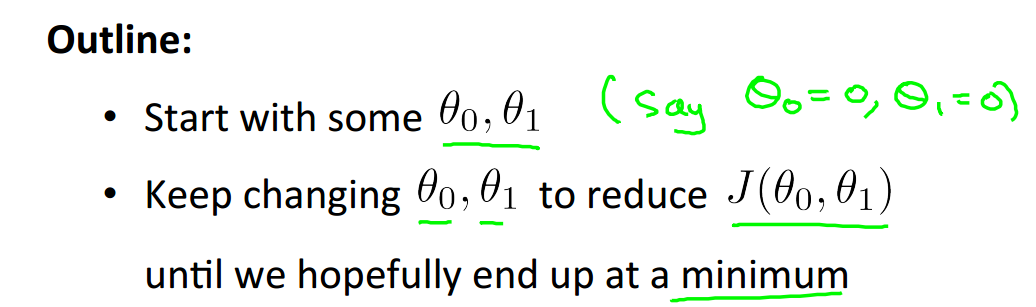
1. 初始化参数值
2. 不断改变参数以朝着代价减小的方向前进,知道我们得到我们需求的最小值


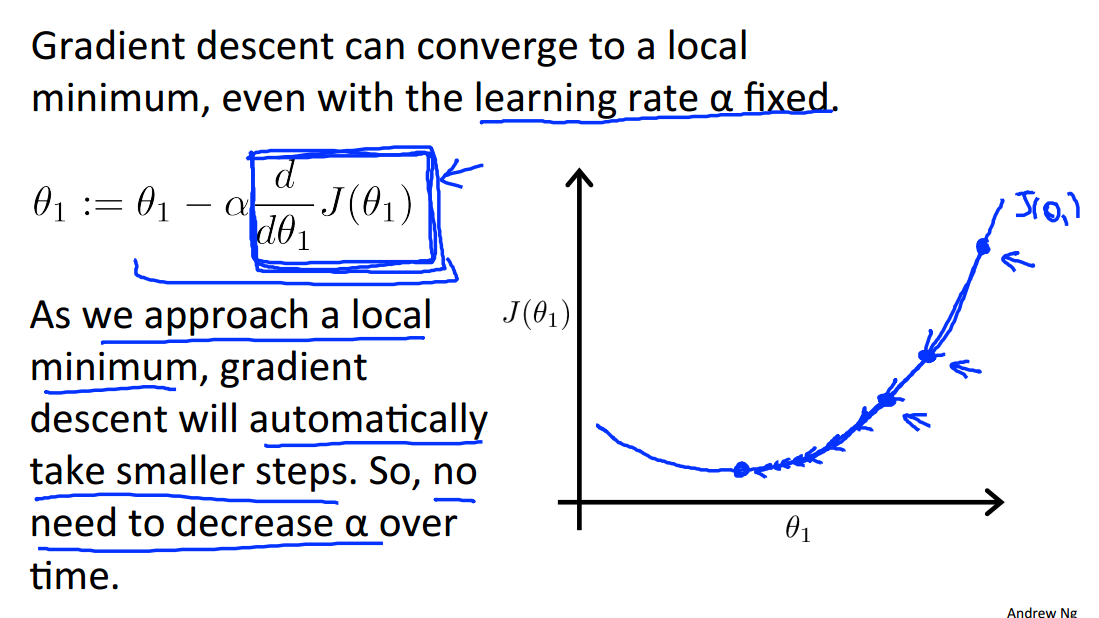
学习速率α对于梯度下降法的影响:
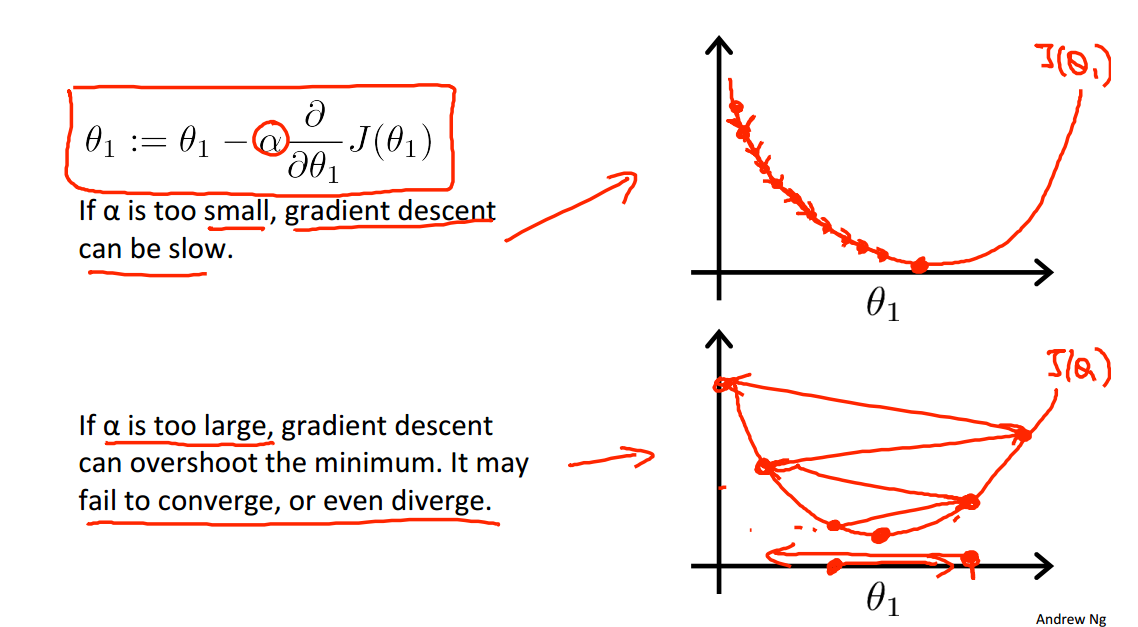
当越来越接近局部最小值时,梯度下降法会自动地迈出更小的步子,所以不需要减小α的值:
五、梯度下降法求解一元线性回归

梯度值的计算:
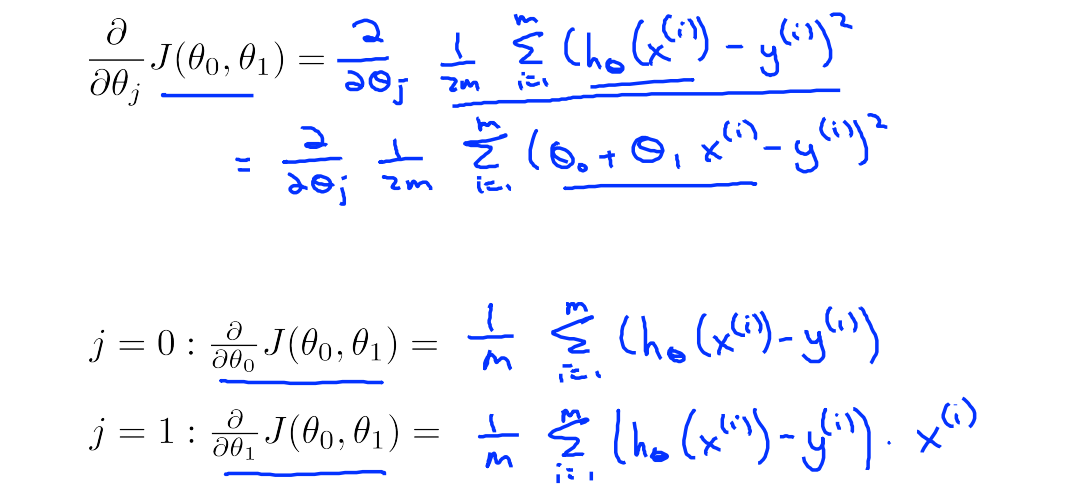
每一次迭代中参数的变化:

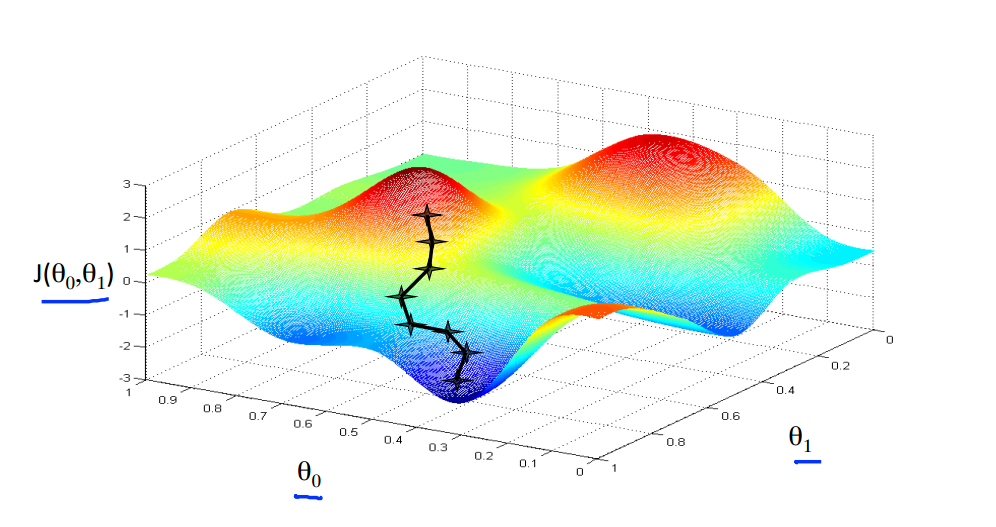
迭代过程演示:
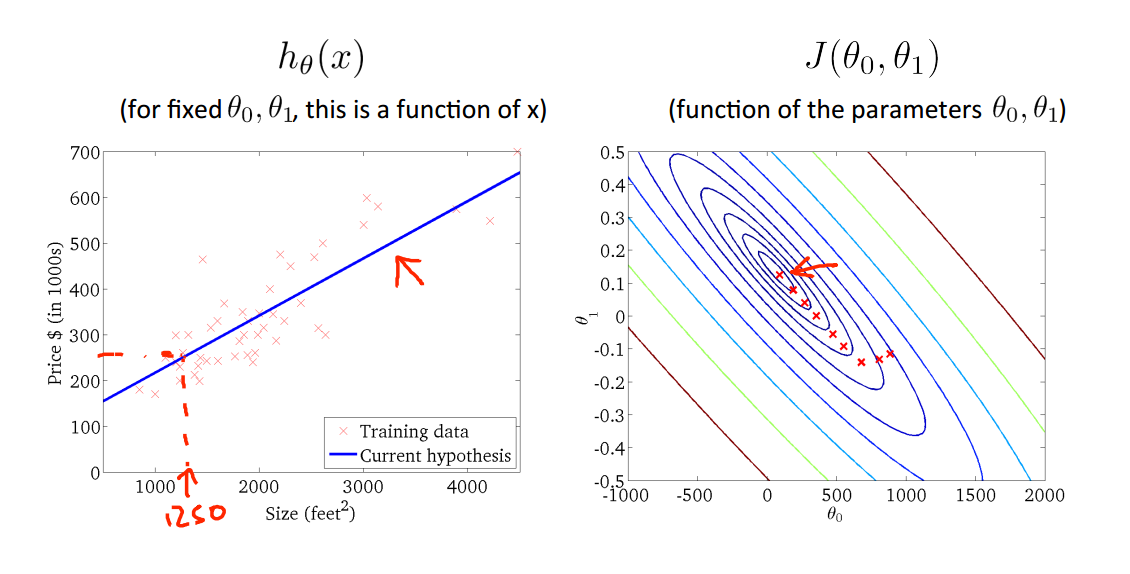
批梯度下降法,每一次参数迭代使用训练集中的所有样本;而随机梯度下降法是更新所有的参数只用一个样本。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号