Golang性能优化实践
内存警察
警惕一切隐式内存分配
典型case:
函数返回了字符串、切片,警惕一切字符串

传进去的输入,函数内部重新分配了一个新的内存返回
对象复用
1.sync.pool
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | import "sync"func NewPoolCh[T any](fn func() T, chLen int) *PoolCh[T] { return &PoolCh[T]{ ch: make(chan T, chLen), pool: NewPool(fn), }}type PoolCh[T any] struct { ch chan T pool *Pool[T]}func (p *PoolCh[T]) Get() T { select { case x := <-p.ch: return x default: return p.pool.Get() }}func (p *PoolCh[T]) Put(x T) { select { case p.ch <- x: default: p.pool.Put(x) }}func NewPool[T any](fn func() T) *Pool[T] { return &Pool[T]{ pool: &sync.Pool{New: func() any { return fn() }}, }}type Pool[T any] struct { pool *sync.Pool}func (p *Pool[T]) Get() T { return p.pool.Get().(T)}func (p *Pool[T]) Put(x T) { p.pool.Put(x)} |
保证有一个ch大小的对象可用

假设有cpu核数那么多并发任务,可以保证gc的时候有保底在
2.局部cache
sync.pool毕竟加锁,要本地ctx能挂载临时对象集,那肯定比pool效率高

currAccmulator在for循环之外的一个临时变量

封装在ctx里面的一个临时变量,跟随ctx整个生命周期销毁

storage存储,后续还能复用
slice复用
1.len与cap

func TestD(t *testing.T) { ints := make([]int, 0, 6) ints = append(ints, 6, 6, 6, 6, 6, 6) // The clear built-in function clears maps and slices. // For maps, clear deletes all entries, resulting in an empty map. // For slices, clear sets all elements up to the length of the slice clear(ints) logger.DEBUG("ints", ints, " cap: ", cap(ints), " len:", len(ints)) ints = ints[:0] // len == 0, cap == 6 之前的元素还在 logger.DEBUG("ints", ints, " cap: ", cap(ints), " len:", len(ints)) ints = append(ints[:0], 1, 2, 3) // 这样就覆盖了原来的元素 logger.DEBUG("ints", ints, " cap: ", cap(ints), " len:", len(ints)) // recap additionalItems := 10 intsLen := len(ints) if n := intsLen + additionalItems - cap(ints); n > 0 { ints = append(ints[:cap(ints)], make([]int, n)...) } ints = ints[:intsLen] // resize size := 10 if cap(ints) > size { ints = ints[:size] } else { ints = make([]int, size) } }
1 2 3 4 5 | === RUN TestD2024/06/13 23:24:27 [DEBUG] ints[0 0 0 0 0 0] cap: 6 len:6 2024/06/13 23:24:27 [DEBUG] ints[] cap: 6 len:0 2024/06/13 23:24:27 [DEBUG] ints[1 2 3] cap: 6 len:3 |
slice内部对象复用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | type Tags struct { tags []Tag freed bool}type Tag struct { Key []byte Value []byte}func (t *Tags) AddTag(key, value string) { if cap(t.tags) > len(t.tags) { t.tags = t.tags[:len(t.tags)+1] } else { t.tags = append(t.tags, Tag{}) } tag := &t.tags[len(t.tags)-1] tag.Key = append(tag.Key[:0], key...) tag.Value = append(tag.Value[:0], value...)} |
假设这样一个场景,原始数据是
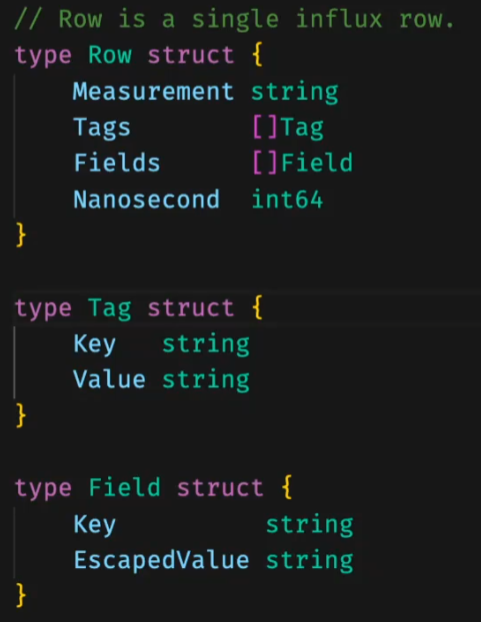
由于string是定长,没办法复用,只能由byte数组转化而来。所以变成这样:

Row里面持有的内存其实是tagsPool、fieldsPool里面的。网络协议先append到stringsPool里,假设读到的是一个"hello",stringsPool一个长度为5的切片,再unsafe转换到tag上
2.string与bytes

避免string到byte数组额外的拷贝
跨类型复用
1.unsafe
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | func ToUnsafeSlice[T any](b []byte) (ts []T) { if len(b) == 0 { return nil } elemSize := unsafe.Sizeof(*new(T)) if len(b)%int(elemSize) != 0 { panic("ToUnsafeSlice: len(b) is not a multiple of elemSize") } bh := (*reflect.SliceHeader)(unsafe.Pointer(&b)) th := (*reflect.SliceHeader)(unsafe.Pointer(&ts)) th.Data, th.Len, th.Cap = bh.Data, bh.Len/int(elemSize), bh.Cap/int(elemSize) return ts}func ToUnsafeBytes[T any](ts []T) (b []byte) { if len(ts) == 0 { return nil } elemSize := unsafe.Sizeof(*new(T)) bh := (*reflect.SliceHeader)(unsafe.Pointer(&b)) th := (*reflect.SliceHeader)(unsafe.Pointer(&ts)) bh.Data, bh.Len, bh.Cap = th.Data, th.Len*int(elemSize), th.Cap*int(elemSize) return b}func MarshalInt64s(dst []byte, is []int64) []byte { dst = encoding.MarshalUint32(dst, uint32(len(is))) dst = append(dst, ToUnsafeBytes(is)...) return dst}func UnsafeUnmarshalInt64s(src []byte) ([]int64, []byte, error) { if len(src) < 4 { return nil, src, errors.New("UnmarshalInt64s: src too short") } n := encoding.UnmarshalUint32(src) src = src[4:] if len(src) < int(n)*8 { return nil, src, errors.New("UnmarshalInt64s: src too short") } is := ToUnsafeSlice[int64](src[:n*8]) return is, src[n*8:], nil} |
2.arena
any interface也是指针
生命周期管理
- 改造代码结构,让数据在其中单向流动
- 确定数据生命周期的起点和终结点
- 中间环节确定自己是借用关系还是拥有关系
有起点和终点,中间对这块数据不会新增新的内存去对主数据做变更

所有的数据在influx.Parse里产生,rows是influx.Parse这个函数里的成果。但如果还涉及改动里面的数据,比如map,那么只能做深拷贝。当你复用内存的时候需要关注内存的生命周期

r.output.Consume是不持有table的,如果要对table进行改动,那么需要重新拷贝一个对象来操作
当一个函数返回一个新的内存的时候,需要思考这个内存到底哪来的

上面的gzip函数把本该放回pool对象的g返回出去了,这样导致了内存所有权问题
但下面的函数的target其实是对content的拷贝,又产生了一份新的内存。讲道理gzip可以再把这部分内存当作参数传进来



