系统设计-实战篇
计数系统设计(一):面对海量数据的计数器要如何做?
1.微博的评论数、点赞数、转发数、浏览数、表态数等等;
2.用户的粉丝数、关注数、发布微博数、私信数等等。
越是最近发布的微博,计数数据的访问量就越大,按照时间来分库分表会造成数据访问的不均匀,最后用了哈希的方式来做分库分表。
数据库 + 缓存的方式有一个弊端:无法保证数据的一致性,比如,如果数据库写入成功而缓存更新失败,就会导致数据的不一致,影响计数的准确性。
微博计数的数据具有明显的热点属性:越是最近的微博越是会被访问到,时间上久远的微博被访问的几率很小。所以为了尽量减少服务器的使用,我们考虑给计数服务增加 SSD 磁盘,然后将时间上比较久远的数据 dump 到磁盘上,内存中只保留最近的数据。当我们要读取冷数据的时候,使用单独的 I/O 线程异步地将冷数据从 SSD 磁盘中加载到一块儿单独的 Cold Cache 中。
总结:
- 数据库 + 缓存的方案是计数系统的初级阶段,完全可以支撑中小访问量和存储量的存储服务。如果你的项目还处在初级阶段,量级还不是很大,那么你一开始可以考虑使用这种方案。
- 通过对原生 Redis 组件的改造,我们可以极大地减小存储数据的内存开销。
- 使用 SSD+ 内存的方案可以最终解决存储计数数据的成本问题。这个方式适用于冷热数据明显的场景,你在使用时需要考虑如何将内存中的数据做换入换出。
计数系统设计(二):50万QPS下如何设计未读数系统?
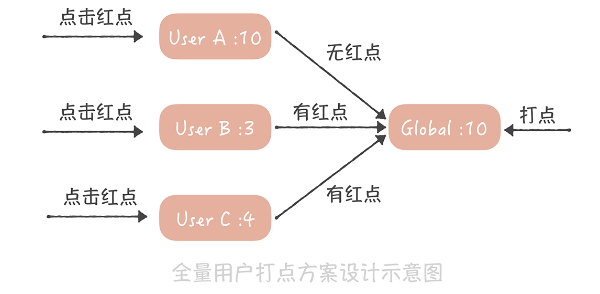
1个存储业务实体对1个用户直接计数就好
1对多,用户纬度记录最新访问时间或id
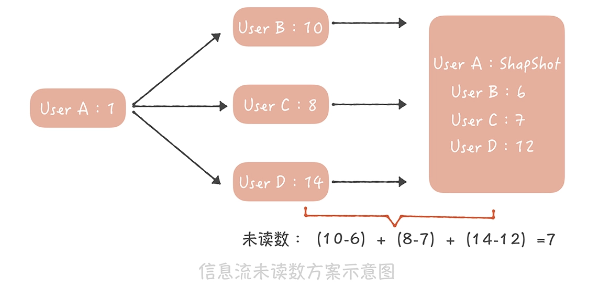
多对多,用户纬度记录每个关注对象的已读记录数
信息流设计:通用信息流系统的推拉模式要如何做?
1、一开始很简单,两张表,一张存储关注关系 ,一张存储微博消息,用户A发微博就是在相应的微博消息表中写入一条即可,用户B读微博也很简单,就是先得到自己关注的用户列表,然后定时去存储微博消息表中去读取自己关注的微博展示出来即可,优点是只有一份存储,缺点也很明显,对于这张表的读操作太多了,并发过大。
2、改成推模式,即写扩散机制,用户A发送一条消息,除了写入微博消息表以外,还要写入关注它的所有的用户的收件箱中(这个可以用redis来实现),然后用户去收件箱中读取消息即可,优点就是自己读自己的消息,跟别人没有竞争,缺点是多余存储,在大V用户发微博消息中有延迟,同时写入次数太多了,同时取消关注什么的也比较难操作。
3、后面改成了推拉结合的方式,即对于大V用拉模式,对于普通的用户继续用推模式。
4、后面出现了基于时间分区的拉模式,可以结合推模式来进行相应的弥补。



