
数据结构 第四章 字符串和多维数组
串的基本概念
串的概念
串(String)是零个或多个字符组成的有限序列。一般记作 S=“a1a2a3…an”,其中S是串名,用双引号括起来的字符序列是串值;ai(1≦i≦n)可以是字母、数字或其它字符。串中所包含的字符个数称为该串的长度。
(1)主串和子串
串中任意个连续字符组成的子序列称为该串的子串。包含子串的串相应地称为主串。
通常将子串在主串中首次出现时的该子串的首字符对应的主串中的序号,定义为子串在主串中的序号(或位置)。
(2)空白串和空串
长度为零的串称为空串(Empty String),它不包含任何字符。
通常将仅由一个或多个空格组成的串称为空白串(Blank String)。
空白串和空串的不同,如“ ”和“”分别表示长度为1的空白串和长度为0的空串。
(3)串相等
当且仅当两个串的值相等时,称这两个串是相等的,即只有当两个串的长度相等,并且每个对应位置的字符都相等时才相等。
串的基本运算
(1)串赋值
strassign(S,T),表示将T串的值赋给S串。
(2)联接
strcat(T1,T2),表示将T1串和T2串联接起来,组成一个新的T1串。
(3)求串长度
strlen (T),求T串的长度。
(4)子串
substr (S, i, len),表示截取S串中从第i个字符开始连续len个字符,构成一个新串(显然该新串是S串的子串)。
(5)串比较大小
strcmp(S,T),比较S串和T串的大小,若S
串的存储结构
顺序存储
定长顺序串
定长顺序串是将串设计成一种静态结构类型,串的存储分配是在编译时完成的。与前面所讲的线性表的顺序存储结构类似,可用一组地址连续的存储单元存 储串的字符序列。
定长顺序串类型定义如下:
#define MAXLEN 40 typedef struct { /*串结构定义*/
char ch[ MAXLEN]; /*存储字符串的一维数组,每个分量存储一 个字符*/
int len; /*字符串的长度*/
}
SString;
- 1
- 2
- 3
- 4
- 5
(1)串插入
/*在串 s 中下标为 pos 的字符之前插入串 t */
StrInsert(SString *s, int pos, SString t) {
int i;
if (pos<0 || pos>s->len)
return(0); /*插入位置不合法*/
if (s->len + t.len<=MAXLEN) { /*插入后串长≤MAXLEN*/
for (i=s->len + t.len-1;i>=t.len + pos;i--)
s->ch[i]=s->ch[i-t.len];
for (i=0;i<t.len;i++)
s->ch[i+pos]=t.ch[i];
s->len=s->len+t.len;
} else if (pos+t.len<=MAXLEN) { /*插入后串长>MAXLEN,但串 t 的字符序列可以全部插入*/
for (i=MAXLEN-1;i>t.len+pos-1;i--)
s->ch[i]=s->ch[i-t.len];
for (i=0;i<t.len;i++)
s->ch[i+pos]=t.ch[i];
s->len=MAXLEN;
} else { /*插入后串长>MAXLEN,并且串 t 的部分字符也要舍弃
for (i=0;i<MAXLEN-pos;i++)
s->ch[i+pos]=t.ch[i];
s->len=MAXLEN;
}
return(1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
(2)串删除
/*在串 s 中删除从下标 pos 起 len 个字符*/
StrDelete(SString *s, int pos, int len) {
int i;
if (pos<0 || pos>(s->len-len))
return(0); /*删除参数不合法*/
for (i=pos+len;i<s->len;i++)
s->ch[i-len]=s->ch[i]; /*从 pos+len 开始至串尾依次向前移动,实现删除 len 个字符*/
s->len=s->len - len; /*s 串长减 len*/
return(1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
堆串
字符串包括串名与串值两部分,而串值采用堆串存储方法存储,串名用符号表存储。
这类串操作实现的算法为:先为新生成的串分配一个存储空间,然后进行串值的复制。
C语言已经有一个称为堆的自由存储空间,并可用函数malloc()和函数free()完成动态存储管理。因此,可以直接利用C语言中的“堆”来实现堆串。此时堆串可定义如下:
typedef struct {
char *ch; // 若是非空串, 则按串长分配存储区, 否则 ch 为NULL
int length; //串长度
} HString ;
- 1
- 2
- 3
- 4
(1)求串长
int strlen(HString s) {
return s.length;
}
- 1
- 2
- 3
(2)置空
Status clearstring(HString s) {
if (s.ch){
free(s.ch);
s.ch=NULL;
}
s.length=0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(3)生成堆
//生成一个其值等于串常量chars的串t
Status strassign(HString t, char *chars){
if(t.ch)
free(t.ch); //释放原空间
i=strlen(chars); //求串长
if (!i) {
t.ch=NULL;
t.length=0;
} //空串
else{
if(!(t.ch=(char *)malloc(i*sizeof(char)))) //申请存储
exit(OVERFLOW);
for (j=0;j<i;j++)
t.ch[j]=chars[j]; //复制
t.length=i;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
(4)比较函数
int strcmp(HString s, HString t) {
//S>T, 返回值>0; S==T, 返回值0 ; S<T, 返回值<0
for(i=0;i<s.length && i<t.length; ++i)
if(s.ch[i]!=t.ch[i])
return(s.ch[i]-t.ch[i]);
return s.length-t.length;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(5)拼接函数
// 用T返回由S1和S2联接而成的新串
Status strcat(HString t, HString s1,HString s2) {
if(!(t.ch)=(char*)malloc(s1.length+s2.length)*sizeof(char)))
exit(OVERFLOW);
for(j=0; j< s1.length ; j++)
t.ch[j]=s1.ch[j];
for(k=0;k< s2.length ;k++)
t.ch[j+k]=s2.ch[k];
t.length=s1.length+s2.length;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(6)求子串
//用Sub返回串S的第pos个字符起长度为len的子串
Status substr(HString sub, HString s, int pos, int len) {
if (pos<1 || pos>s.length || len<0 || len>s.length-pos+1)
return ERROR;
if (sub.ch)
free(sub.ch); // 释放旧空间
if (!len) {
sub.ch=NULL;
sub.length=0;
} // 空子串
else{
sub.ch=(char *)malloc(len*sizeof(char));
for(j=0;j<len;j++)
sub.ch[j]=s.ch[pos-1+j];
s.length=len;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
链式存储
由于串也是一种线性表,因而也可以采用链式存储。因为串是一个特殊的线性表(表中每 个元素就是一个字符)。
在具体实现时,一个链表存放一个串值,每个结点既可以存放一个字符, 如下所示:
typedef struct node{
char data;
struct node *next;
}lstring;
- 1
- 2
- 3
- 4
但这种方式存储的密度太低,为了提高存储的密度,使得每个节点能够存储多个字符,为便于操作,再增加一个尾指针,结构可定义如下:
#define BLOCK_SIZE 4 //每结点存放字符个数
typedef struct Block { // 结点结构
char ch[ BLOCK_SIZE ];
struct Block *next;
} Block;
typedef struct { // 串的链表结构
Block *head, *tail; // 串的头和尾指针
int len; // 串的当前长度
} BLtring;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
模式匹配
BF算法
(1)算法思想:
将主串的第pos个字符和模式的第1个字符比较,若相等,继续逐个比较后续字符;若不等,从主串的下一字符 (pos+1) 起,重新与第一个字符比较。直到主串的一个连续子串字符序列与模式相等 。返回值为S中与T匹配的子序列第一个字符的序号,即匹配成功。否则,匹配失败,返回值 0 。
(2)程序段:
int S_index(SString t, SString p, int pos) {
int n,m,i,j;
m=strlen(t); n=strlen(p);
for (i=pos-1; i<=m-n; i++){
for (j=0; j<n && t[i+j]==p[j]; j++) ;
if(j==n)
return(i+1);
}
return(0);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
KMP算法(略)
例题
例1
若n为主串长,m为子串长,则串的古典(朴素)匹配算法最坏的情况下需要比较字符的总次数为__________。
(n - m + 1) * m
例2
设有两个串s和t,其中t是s的子串,求子串t在主串s中首次出现位置的算法。
解:
int S_index(SString s, SString t) { //找到返回下标(>=1),否则返回0;串类型为SString
int n,m,i,j;
m=strlen(s);
n=strlen(t);
for (i=0; i<=m-n; i++){
for (j=0; j<n && s[i+j]==t[j]; j++) ;
if(j==n) return(i+1);
}
return(0);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
数组的定义
在C语言中,一个二维数组类型可以定义为其分量类型为一维数组类型的一维数组类型,也就是说:
typedef elemtype array2[m][n];
- 1
等价于:
typedef elemtype array1[n];
typedef array1 array2[m];
- 1
- 2
数组一旦被定义,它的维数和维界就不再改变。因此,除了结构的初始化和销毁之外,数组只有存取元素和修改元素值的操作。
数组的存储方式
数组一般采用顺序存储,又分为行优先和列优先。数组的地址计算具有以下前提三要素:
-
开始结点的存放地址(即基地址)。
-
维数和每维的上、下界。
-
每个数组元素所占用的单元数 L。
设一般的二维数组是A[c1…d1, c2…d2],这里c1,c2不一定是0。
行优先存储时的地址公式为:LOC(aij)=LOC(c1,c2)+[(i-c1)*(d2-c2+1)+(j-c2)]*L。其中,c1,c2为数组基地址,i-c1为aij之前的行数,d2-c2+1为总列数,j-c2为aij本行前面元素个数,L为单个元素长度。
列优先存储的通式为:LOC(aij)=LOC(ac1,c2)+[(j-c2)*(d1-c1+1)+(i-c1)]*L。
特殊矩阵
对称矩阵
(1)定义
在一个n阶方阵A中,若元素满足下述性质:aij=aji(0≤i, j≤n-1),即元素关于主对角线对称。
(2)存储方式
不失一般性,按“行优先顺序”存储主对角线以下元素,存储空间节省一半,如下所示:
a11
a21 a22
a31 a32 a33
…………………………
an1 an2 an3 …ann
在这个下三角矩阵中, i i i ii i iiiaij 的对应关系为:

在aij之前有i 行,共有3 x i-1个非零元素,在第 i 行,有j-i+1个非零元素,即非零元素aij的地址为: Loc(aij) = Loc(sa[k]) =LOC(0,0)+[3*i-1+(j-i+1)]*d=LOC(0,0)+(2*i+j)*d 。
稀疏矩阵及存储
概念
在实际应用中,经常会遇到另一类矩阵:其矩阵阶数很大,非零元个数较少,零元很多,且非零元的排列无规律可寻,则称这类矩阵为稀疏矩阵。
精确地说,设在的矩阵A中,有s个非零元。令e = s / (m*n),称e为矩阵A的稀疏因子。通常认为e≤0.05时称矩阵A为稀疏矩阵。
稀疏矩阵由表示非零元的三元组及行列数唯一确定,一个三元组(i, j, aij)唯一确定了矩阵A的一个非零元。
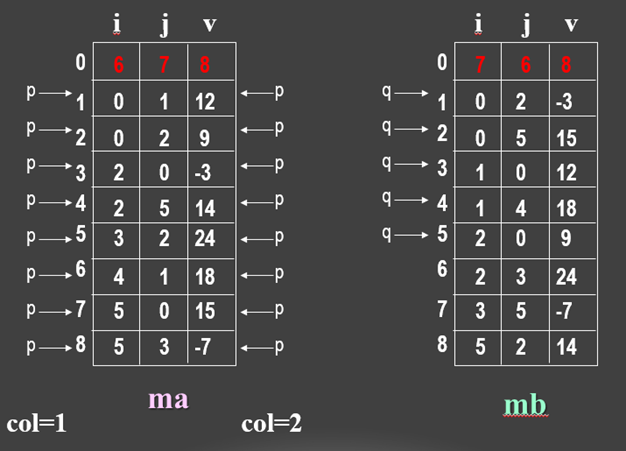
例如:下列三元组表: ( (0,1,12), (0,2,9), (2,0,-3), (2,5,14), (3,2,24), (4,1,18), (5,0,15), (5,3,-7) ),加上(6,7,8) ——矩阵的行数、列数及非零元数便可作为矩阵M的另一种描述:

三元组表表示法
对于稀疏矩阵的压缩存储,采取只存储非零元素的方法。由于稀疏矩阵中非零元素 aij的分布没有规律,因此,要求在存储非零元素值的同时还必须存储该非零元素在矩阵中所处的行号和列号的位置信息,这就是稀疏矩阵的三元组表表示法。
每个非零元素在一维数组中的表示形式如下图所示:
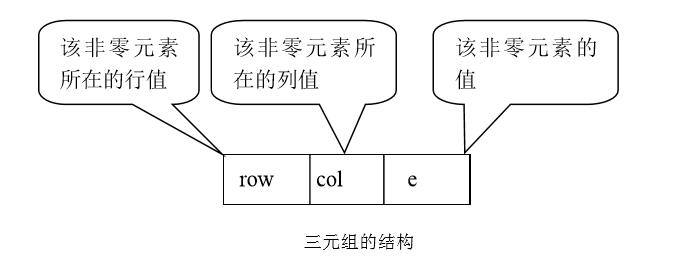
假设以顺序存储结构来表示三元组表,则可得到稀疏矩阵的一种压缩存储方法——三元顺序表。其定义如下:
#define maxsize 1000
typedef int datatype;
typedef struct {
int i,j; /* 非零元的行、列下标 */
datatype v; /* 元素值 */
} triplet;
typedef struct {
triplet data[maxsize]; /* 三元组表 /
int m,n,t; / 行数、列数、非零元素个数 /
} tripletable; / 稀疏矩阵类型 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
因此上面的三元组表的三元组顺序表表示如下:
| i | j | v |
|---|---|---|
| 0 | 1 | 12 |
| 0 | 2 | 9 |
| 2 | 0 | -3 |
| 2 | 5 | 14 |
| 3 | 2 | 24 |
| 4 | 1 | 18 |
| 5 | 0 | 15 |
| 5 | 3 | -7 |
| M[0].i | M[0].j | M[0].t |
|---|---|---|
| 6 | 6 | 8 |
显然,三元组顺序表存储会失去随机存取功能。
三元组顺序表的转置
一个m×n的矩阵A,它的转置B是一个n×m的矩阵,且a[i][j]=b[j][i],0 ≤ i < m,0 ≤ j < n,即A的行是B的列,A的列是B的行。
将A转置为B,就是将A的三元组表M[0].i置换为表B的三元组表M[0].i,如果只是简单地交换a.data中i和j的内容,那么得到的b.data将是一个M[0].i顺序存储的稀疏矩阵B,要得到按行优先顺序存储的b.data,就必须M[0].i。
解决思路:只要做到:
- 将矩阵行、列维数互换;
- 将每个三元组中的i和j相互调换;
- 重排三元组次序,使mb中元素以N的行(M的列)为主序。
(1)方法一:按M的列序转置
即按mb中三元组次序依次在ma中找到相应的三元组进行转置。为找到M中每一列所有非零元素,需对其三元组表ma从第一行起扫描一遍。由于ma中以M行序为主序,所以由此得到的恰是mb中应有的顺序。
算法分析:T(n)=O(M的列数n * 非零元个数t )=O(n * t),若 t 与m * n同数量级,则T(n)=O(m * n2)。由此可见,进行转置运算时,虽然节省了存储单元,却大大增加了时间复杂度。
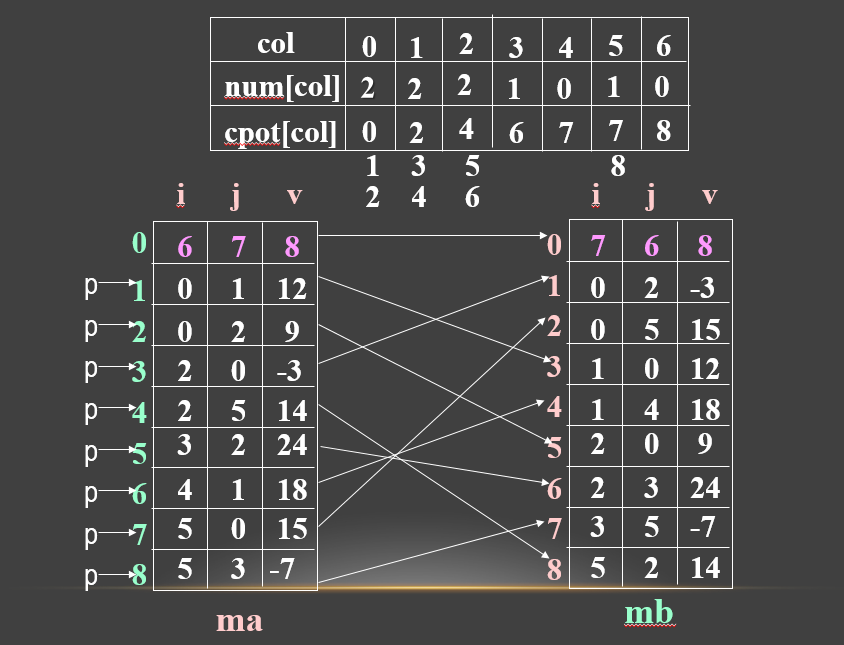
(2)方法二:快速转置
即按ma中三元组次序转置,转置结果放入mb中恰当位置。此法关键是要预先确定M中每一列第一个非零元在mb中位置,为确定这些位置,转置前应先求得M的每一列中非零元个数。
设两个数组:
num[col]:表示矩阵M中第col列中非零元个数。
cpot[col]:指示M中第col列第一个非零元在mb中的下标。
显然有:
cpot[0]=0;
cpot[col]=cpot[col-1]+num[col-1]; (1<= col <= ma[0].j)
- 1
- 2
链式存储
(1)特点
-
带行指针向量的单链表表示;
-
每行的非零元用一个单链表存放;
-
设置一个行指针数组,指向本行第一个非零元结点;若本行无非零元,则指针为空。
(2)表头结点与单链表结点类型定义
typedef struct node{
int col;
int val;
struct node *link;
}JD;
typedef struct node *TD;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
十字链表
与用二维数组存储稀疏矩阵相比较,用三元组表表示法的稀疏矩阵不仅节约了空间,而且 使得矩阵某些运算的时间效率优于经典算法。
但是当需进行矩阵加法、减法和乘法等运算时,有时矩阵中非零元素的位置和个数会发生很大的变化。如A =A+B,将矩阵 B 加到矩阵 A 上, 此时若用三元组表表示法,势必会为了保持三元组表“以行序为主序”而大量移动元素。
为了避免大量移动元素,介绍稀疏矩阵的链式存储法———十字链表,它能够灵活地插入因运算而产生的新的非零元素,删除因运算而产生的新的零元素,实现矩阵的各种运算。
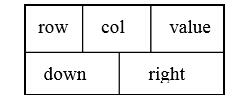
在十字链表中,矩阵的每一个非零元素用一个结点表示,该结点除了(row,col,value)以外, 还要有以下两个链域:
-
right:用于链接同一行中的下一个非零元素。 -
down:用于链接同一列中的下一个非零元素。
在十字链表中,同一行的非零元素通过right域链接成一个单链表。同一列的非零元素通过down 域链接成一个单链表。
这样,矩阵中任一非零元素M[i][j]所对应的结点既处在第i行的行链表上,又处在第j列的列链表上,这好像是处在一个十字交叉路口上,所以称其为十字链表。
同时再附设一个存放所有行链表的头指针的一维数组和一个存放所有列链表的头指针的一维数组。整个十字链表的结构如图所示。
十字链表的结构类型定义如下:
typedef struct OLNode {
int row, col; /*非零元素的行和列下标*/
ElementType value;
struct OLNode *right, *down; /*非零元素所在行表、列表的后继链域*/
}OLNode; *OLink;
typedef struct {
OLink row_head, col_head; /行、列链表的头指针向量/
int m, n, len; /稀疏矩阵的行数、列数、非零元素的个数/
}CrossList;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
广义表
广义表是线性表的推广。线性表中的元素仅限于原子项(单个数据元素),即不可以再分,而广义表中的元素既可以是原子项,也可以是子表(另一个线性表)。 (如果ai是单个数据元素,则称ai为广义表的原子 )。
定义
广义表是n≥0个元素a0, a1, …, an-1的有限序列,其中每一个ai或者是原子,或者是一个广义表。
广义表通常记为GL=(a0,a1,…,an-1),其中GL为广义表的名字,n为广义表的长度, 每一个ai为广义表的元素。一般用大写字母表示广义表,小写字母表示原子。
称第一个元素a0为广义表GL的表头,其余部分(a1,…an-1)为GL的表尾,分别记作:head(GL)=a0 ,tail(GL)=(a1,…an-1)。
说明
-
广义表是线性表的一种推广。
-
广义表的定义是递归的。因为在描述广义表的时候又用到了广义表的概念。
-
广义表是多层次结构。
-
一个广义表可以为其它广义表所共享。
举例
(1) A=( ), A为空表,长度为0。
(2) B=(a, (b,c)),B是长度为2的广义表,第一项为原子,第二项为广义表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号