


树形数据结构总结一(堆,Trie,并查集)
转自:https://juejin.cn/post/6844903856778788878
树形结构是非常重要的一种数据结构。
应用:
我们可以通过平衡二叉树来实现排序问题,用树结构来表示源程序的语法结构,树也可以表示数据库或文件系统。
并且很多容器的底层都是树结构。

树结构的名词:
- 结点:表示树中的数据元素,A,B...H就是节点。
- 结点的度:结点所拥有的子树的个数,B的度为2。
- 树的度:树中各结点度的最大值,这里树的度为2。
- 叶子结点(Leaf Node):度为0的结点。D,H,F,G结点都是叶子结点。
- 孩子(Child):结点左右节点。在图中,结点D,E是结点B的孩子。
- 双亲(Parent):结点的上层结点叫该结点的双亲。结点B是D,E的双亲。
- 祖先(Ancestor):从根到该结点所经分支上的所有结点。A是其他所有节点的祖先。
- 子孙(Descendant):以某结点为根的子树中的任一结点。A之外的所有结点都是A的子孙。
- 兄弟(Brother):同一双亲的孩子。结点B,C互为兄弟,D,F互为兄弟,F,G互为兄弟。
- 堂兄弟(Sibling):同一层的双亲不同的结点。E和F互为堂兄弟。
- 结点的层次(Level of Node):从根结点到树中某结点所经路径上的分支数称为该结点的层次。A的层次为4。
- 树的深度(Depth of Tree):树中结点的最大层次数。这里树的深度为4。
这里只解释了二叉树(一个节点只有左右两个孩子的情况),当然树不一定只有两个孩子,比如下文会出现的并查集和Trie,但我们可以把大多数树转化为二叉树,这样更便于让我们理解概念。
二叉树中的概念:
满二叉树(完美二叉树):一个深度为k且有2^k - 1个结点的二叉树称为满二叉树

完全二叉树:完全二叉树从根结点到倒数第二层满足完美二叉树,最后一层可以不完全填充,其叶子结点都靠左对齐。
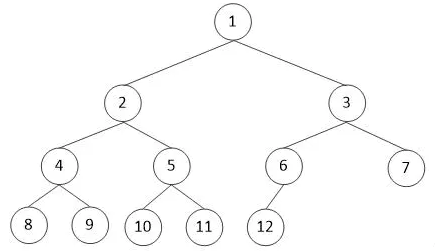
完满二叉树:所有非叶子结点的度都是2

平衡二叉树:每个节点的左右子树深度差不超过1
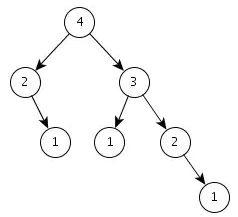
绝对平衡树:只有最后一层是叶子节点,并且满足二分搜索树的特点
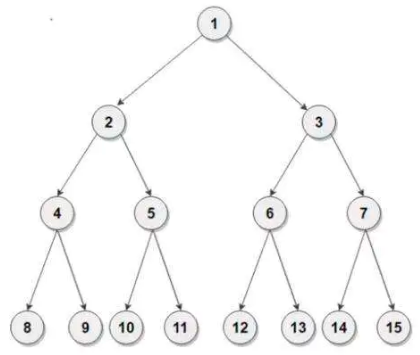
二分搜索树
如果现在有一个数组,给出一个数(这个数在数组中),要求找到这个数在这个数组的下标位置,我们只能一个一个去遍历查找,这个时候的时间复杂度是O(n),为了加快查找速度,如果我们得到的数组是排好序的,我们可以使用折半查找法,这样时间复杂度就为O(logn)了,速度会很快。而折半查找的思路就是利用了二分搜索的思想。
先来看二分搜索树的节点构造:
1 2 3 4 5 | class Node{ int data;//节点值 Node left;//左孩子 Node right;//右孩子} |
二分搜索树定义
节点的左子树的所有节点小于这个节点,节点的右子树的所有节点大于这个节点。
空树也算二分搜索树。
二分搜索树的操作
插入
二分搜索树的插入操作十分简单:
- 判断是否有根节点,没有当前节点作为根节点
- 有就做比较,比当前节点大就和它的右节点比较,比当前节点小就和它的左节点比较
- 如果比较到叶子节点就插入
- 重复2步骤,直到3步骤执行结束
插入的平均时间复杂度为O(logn)
删除
删除的操作稍微麻烦一些,将要删除的节点分为三种情况:
- 没有孩子:直接遍历到节点删除即可
- 有一个孩子:删除该节点,让这个节点的孩子节点移到这个节点的位置
- 有两个孩子:删除该节点,让这个节点的右孩子的最左节点X(左孩子的最右节点也可)移动到这个位置,这时X只有可能有右孩子,再对原来X的位置进行只有一个孩子时删除操作即可。
删除的平均时间复杂度为O(logn)
查找
查找和插入的方法类似,这里就不赘述了
查找的平均时间复杂度为O(logn)
DFS,BFS
如果想遍历一棵二叉树有两种方法,深度优先遍历和广度优先遍历,而深度优先遍历又可以分为前序,中序,后序遍历。
深度优先遍历(DFS):深度优先遍历的思想就是将节点先从每条分支先遍历完
前序遍历:节点-左孩子-右孩子
中序遍历:左孩子-节点-右孩子(二叉搜索树的中序遍历是有顺序的)
后序遍历:左孩子-右孩子-节点
广度优先遍历(BFS):从每一层开始遍历
下面来看个图来看具体的遍历时如何的:

- 前序遍历:ABCDEF
- 中序遍历:CBDAEF
- 后序遍历:CDBFEA
- 广度优先遍历:ABECDF
二分搜索树的作用
- 对数组来说它的增加,删除的时间要O(n),查找的时间也要O(n)。
- 对二分搜索树来说它的增加,删除,查找的时间都为O(logn)。
堆
堆的定义
堆是一种完全二叉树,并且一个节点要大于(小于)它的左右孩子
来看堆的节点构造:
1 2 3 4 5 | class Node{ int data;//节点值 Node left;//左孩子 Node right;//右孩子} |
堆的操作
对于堆来说他更注重将最大的放在首位和堆性质的维护。这里因为堆是一个完全二叉树,所以可以用数组来保存堆中的元素。
如图(以下使用最小堆,即每个节点小于它的孩子节点):

那么对于一个节点,我们可以很容易的找到这个节点的双亲结点和左右节点。
1 2 3 4 5 6 7 8 9 10 11 12 | // 获得双亲结点的下标int getParent(int index){ return (index - 1) / 2;}// 获得左孩子int getLeftChild(int index){ return index * 2 + 1;}// 获得右孩子int getRightChild(int index){ return index * 2 + 2;} |
插入,这一步要做的叫堆的sift up:
- 先将元素放到数组最后的位置
- 将这个元素与它的双亲节点进行大小比较,如果这个节点比它的双亲结点小,那么和这个节点交换位置
- 重复步骤2一直比较到头节点或是大于双亲结点的时候结束
删除(这里的删除指的是删除头元素、头节点的意思),这一步要做的叫堆的sift down:
- 将数组中下标为0的元素移除,并将数组中最后一个元素放到下标为0的位置
- 将当前位置为0的节点记为x,找出x的左右孩子中较小的那个元素的坐标记为y,将x与y比较,如果x小于y,那么x与y交换位置
- 重复步骤2一直到叶子节点或是大于y的时候结束
堆的作用
堆能够实现优先队列,在现实生活中也有优先队列的应用,例如排队的时候会先让老人和小孩到队列前面。
拓展
d叉堆
完全d叉树,根最小。可以想成原来我们的堆是二叉堆,这个d可以为2,3,4
索引堆
以上我们讨论的堆是比较每个节点的data,如果这个data是一种很庞大的数据结构,那么会很耗时。这时我们可以用索引堆,在原来堆的基础上用一个索引数组来存储数据元素的位置,即索引堆里面包含两个数组
二项堆
二项堆是二项树的集合。二项树也是一种树结构,二项树的第K棵树有2k个结点,高度是k;深度为d的结点共有个结点。二项堆就由一组二项树所构成。
还有斐波那契堆,Pairing堆等等。
线段树的作用
线段树能够解决一些算法问题,例如:
- 对一段区间进行染色(可以覆盖原来的颜色),m次对随即区间染色,问在[i,j]区间可以看见多少种颜色
- 求某个太空区间中天体总量
- 给出n个数,n<=1000000,和m个操作,每个操作修改一段连续区间[a,b]的值
如果用线段树这种结构就有一个方便的思路解决以上问题:
这里假设我们要求求解[1,7]的值我们直接获取tree[8]+tree[4]+tree[2]+即可,即[1,1]+[2,3]+[4,7]就得到[1,7]的值。
如果将0-7采用二分搜索树的方法,并从1加到7那个就是7*O(logn)的复杂度。
线段树的操作
线段树主要针对于查询和修改,至于增加和删除我们不讨论。
查询
这里直接看如果需要查询一段区间该如何操作(懂了区间查询之后单个元素查询也会简单一些)
这里直接放一个例子来理解简单一些,例如现在我要查询[1,7]的值,让查找的值为x返回:
- 先查找根节点[0,7]中是否是自己要查找的,[1,7]并不等于[0,7],要查找的左区间大于节点的左区间,先从左子树[0,3]开始找,并把[1,7]分成[1,3]和[4,7]
- 从左子树[0,3]开始查,[1,3]和[0,3]不相等,要查找的左区间大于节点的左区间,从节点的左区间[0,1]再找,并把[1,3]分为[1,1]和[2,3]
- 从左子树为[0,1]开始查,因为是左子树,[1,1]和[0,1]不相等,和上面一样分为[1,1]和[2,3],所以[0,1]要再查找右子树[1,1]
- 这时[1,1]和[1,1]就相等了,返回[1,1]对应的值
- 接下来将之前返回的值分别和上面步骤留下来的[2,3],[4,7]相加,得到最终的值(因为[2,3],[4,7]都是在节点中直接可以找到的,就不用再分了)
[2,3]的值就是tree[4],[4,7]的值就是tree[2],[1,1]的值就是tree[8]
大概流程就是上面所述,可能一开始看有点晦涩,但结合代码来看使用递归还是挺清晰的
修改
修改的操作和查询的思路一样的,不过要对遍历过的节点进行修改,这里就不赘述了
实际上,能够用线段树解决的问题都能
Trie字典树
字典树不是二叉树,和它的名字一样,首先来看他的节点结构(根节点是不包含字符的,根节点的c是空)
class Node{ char c;//当前节点的字符 Node[] next;//当前节点的下一个节点 boolean end;//判断这个字母是不是一个结尾 }
我们可以发现字典树的每个节点由若干个指向下一节点的指针,整体字典树的结构如下图:
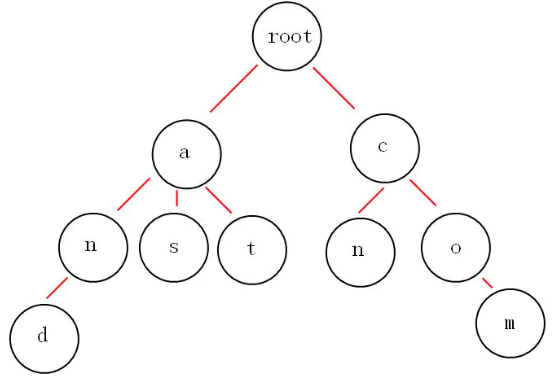
字典树的作用
可以看到上面的图用深度优先中序遍历的话他每遍历到叶子节点都是一个单词,如and,as,at,cn,com。
在以前的电话簿系统中,如果这时我们用二分搜索树去保存每个联系人的信息,假设我们的通讯录有一千万个联系人信息,那么我们通过名字去查询这个联系人的信息是非常费时的O(logn)。而如果我们用字典树,比如我们要查询一个名叫and的联系人,我们通过根节点在next中找a,在a节点中找n,再在n节点中找b(如果这里全是英文字母那么next也只有26种情况),这时我们的时间复杂度只和这个单词的长度有关O(K),K为单词长度。那么可见这种情况下字典树的优势非常明显。当然,字典树的这种设计也就是典型的用空间换取时间的思路。
字典树的操作
字典树的操作主要为增,删,查
在开始之前,解释一下end的作用,例如我们有一个as和一个ass(坏笑.jpg),我们如何判断ass这个单词是只有ass还是还有as这个单词呢?我们需要对每一个节点进行一个标识,标识这个单词是否在这里是一个完整的单词。例如ass,最后一个s中end就要为true,因为ass最后的s是ass的结尾。而如果还有个as单词,那么第一个s就要为true来代表as这个单词以s结束。
增加
增加的逻辑就很简单了,例如增加一个geek
定位到头节点,判断next中是否有g,没有的话先构造节点g(所有新构造的节点end为false),再加入到当前节点的next之中,然后移动到节点g
同理判断e,构造并定位到下一个节点,然后e,然后k
当移动到节点k时,代表单词插入到结尾了,就要设置end为true
删除
例如上图中我们要删除an这个单词
通过头节点到达a,在达到n,如果n的next不为空,那么把n的end改为false即可
如果n的next为空,那么删掉n,回溯到上个节点删掉next中n这个值,再判断next之中是否为空,不空的话结束。空的话再删除a,结束。
查找
例如现在我们要查找and
通过根节点的next找a,存在,当前节点换位a节点
判断a节点的next找n,存在,当前节点换位n节点
判断n节点的next找d,存在,当前节点换位d节点,这时要查找的单词到结尾了,再判断d的end是否为true,true的话表示找到,否则就是没找到。
并查集
并查集是一种树形结构,又叫“不相交集合”,保持了一组不相交的动态集合,每个集合通过一个代表来识别,代表即集合中的某个成员,通常选择根做这个代表。
并查集的作用:
可以解决连接问题,网络中节点连接状态,路径问题。
举个例子,例如我们有若干个城镇,不同城镇之间可能会有相连的道路,将这些城镇看成节点,然后判断哪些城镇之间是可以通路的。
并查集的结构:
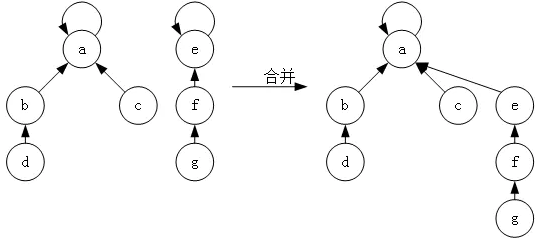
如图,我们将每个节点看成一个城镇
先看左边的图,也就是合并前的图,我们可以说d和c是连通的,g和e是连通的,c和f是不相通的。
如果这时我们想在b城镇和f城镇之间连通,这时,我们不能直接将b和f相连,应该让f的根节点加到d的根节点下,那么这里f的根节点是e,b的根节点是a,也就是直接让a成为e的双亲节点,如图。
我们可以看到并查集的逻辑结构是一种树结构,但每个节点有的只是自己的父亲节点。
并查集的操作
因为并查集主要是来解决路径查找问题的,所以相应的对并查集就需要一个操作isConnect来判断两个节点是否相连。如果两个节点之后可以连通,那么就需要union操作将两个节点连通
判断节点是否相通:
boolean isConnect(Node p, Node q)
通过上面的分析我们知道了判断节点是否相连主要比较的是根节点,所以只要得到p的根节点和q的根节点再判断两个节点是否相同即可。
节点合并:
void unionElements(Node p, Node q)
和一开始分析的时候一样,我们可以先求得p节点的根节点,再求得q节点的根节点,让q节点的根节点的双亲结点指向p节点的根节点即可。
拓展
路径压缩:
有可能出现所有的节点都在一条链上,而我们可以将整棵树弄成只有两层。如图



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决
2018-01-24 解决Android sdk无法下载的问题