
WWW2023 | 基于强化学习的多任务推荐
论文:Multi-Task Recommendations with Reinforcement Learning
摘要:近年来,多任务学习(MTL)在推荐系统(RS)应用中取得了巨大成功。 然而,当前基于 MTL 的推荐模型往往忽略用户-项目交互的会话模式,因为它们主要是基于项目数据集构建的。 此外,平衡多个目标一直是该领域的一个挑战,现有工作中通常通过线性估计来避免这一问题。 为了解决这些问题,在本文中,我们提出了一种强化学习(RL)增强的 MTL 框架,即 RMTL,使用动态权重来结合不同推荐任务的损失。 具体来说,RMTL 结构可以通过(i)从会话交互构建 MTL 环境和(ii)训练多任务 Actor-Critic 网络结构来解决上述两个问题,该结构与大多数现有的基于 MTL 的推荐兼容 模型,以及 (iii) 使用批评者网络生成的权重优化和微调 MTL 损失函数。 对两个真实世界公共数据集的实验证明了 RMTL 的有效性,其 AUC 高于最先进的基于 MTL 的推荐模型。 此外,我们还评估和验证 RMTL 在各种 MTL 模型之间的兼容性和可转移性。
https://arxiv.org/abs/2302.03328
1 引言
为了解决上述两个问题,我们提出了一种强化学习增强的多任务推荐框架 RMTL,它能够将交互中用户-项目的顺序属性合并到 MTL 推荐中,并自动更新任务中的权重 整体损失函数。 强化学习 (RL) 算法最近已应用于 RS 研究,它将顺序用户行为建模为马尔可夫决策过程 (MDP),并利用 RL 在每个决策步骤生成推荐 [32, 58]。 基于强化学习的推荐系统能够处理连续的用户-项目交互并优化长期用户参与度[2]。 因此,我们的 RL 增强框架 RMTL 可以将会话 RS 数据转换为 MDP 方式,并训练 Actor-Critic 框架来生成动态权重以优化 MTL 损失函数。 为了实现多任务输出,我们采用两塔 MTL 主干模型作为参与者网络,该模型通过针对每个任务的两个不同的批评者网络进行优化。 与具有逐项输入和恒定损失函数权重设计的现有 MTL 模型相比,我们的 RMTL 模型从会话式 MDP 输入中提取顺序模式,并自动更新每批数据实例的损失函数权重。 在本文中,我们重点关注 CTR/CTCVR 预测,这是电子商务和短视频平台的关键指标[26]。 在两个真实数据集上针对最先进的基于 MTL 的推荐模型进行的实验证明了所提出模型的有效性。
我们的工作贡献总结如下:(i)将多任务推荐问题转换为演员批评家强化学习方案,能够实现会话级多任务预测; (ii) 我们提出了一种强化学习增强的多任务学习框架 RMTL,它可以为损失函数设计生成自适应调整的权重。 RMTL兼容大多数现有的基于MTL的推荐模型; (iii) 对两个真实世界数据集的广泛实验证明了 RMTL 比 SOTA MTL 模型优越的性能,我们还验证了 RMTL 在各种 MTL 模型之间的可迁移性。
2 提出的框架
本节将详细描述我们的方法,即RMTL框架,该框架通过动态调整损失函数权重实现会话式多任务预测,有效解决现有工作的瓶颈。
2.1 预备知识和符号
会话式多任务推荐。 我们注意到,选择损失函数作为逐项多目标组合可能缺乏从数据中提取顺序模式的能力。 在我们的工作中,我们提出了会话级多目标损失,它通过最小化每个会话的加权累积损失来优化目标。 给定一个 𝐾-task1 预测数据集,其中 𝐷 := 𝑢𝑠𝑒𝑟𝑛,𝑖𝑡𝑒𝑚𝑛, (𝑦𝑛,1, ..., 𝑦𝑛,𝐾) 𝑁 𝑛=1 ,其中包含 𝑁 用户项交互记录,其中𝑢𝑠𝑒𝑟𝑛 和 𝑖𝑡𝑒𝑚𝑛 表示 第 𝑛 个用户项目 𝑖𝑑。 每个数据记录都有对应任务的𝐾 二进制 0-1 标签𝑦1、····、𝑦𝐾。 我们将会话定义为 {𝝉𝑚} 𝑀 𝑚=1 ,每个会话𝝉𝑚包含𝑇𝑚不同的离散时间戳:𝜏𝑚 = 𝜏𝑚,1, · · · , 𝜏𝑚,𝑡, · · · , 𝜏𝑚,𝑇𝑚 , 𝜏𝑚,𝑡 所在的位置 会话𝑚中的时间戳𝑡。 相应的标签用 n (𝑦 𝑠 𝑡,1 , ..., 𝑦𝑠 𝑡,𝐾) o 表示。 由 𝜃 𝑠 1 , ..., 𝜃𝑠 𝐾 参数化的所有会话的会话损失函数定义为:
2.2 框架概述
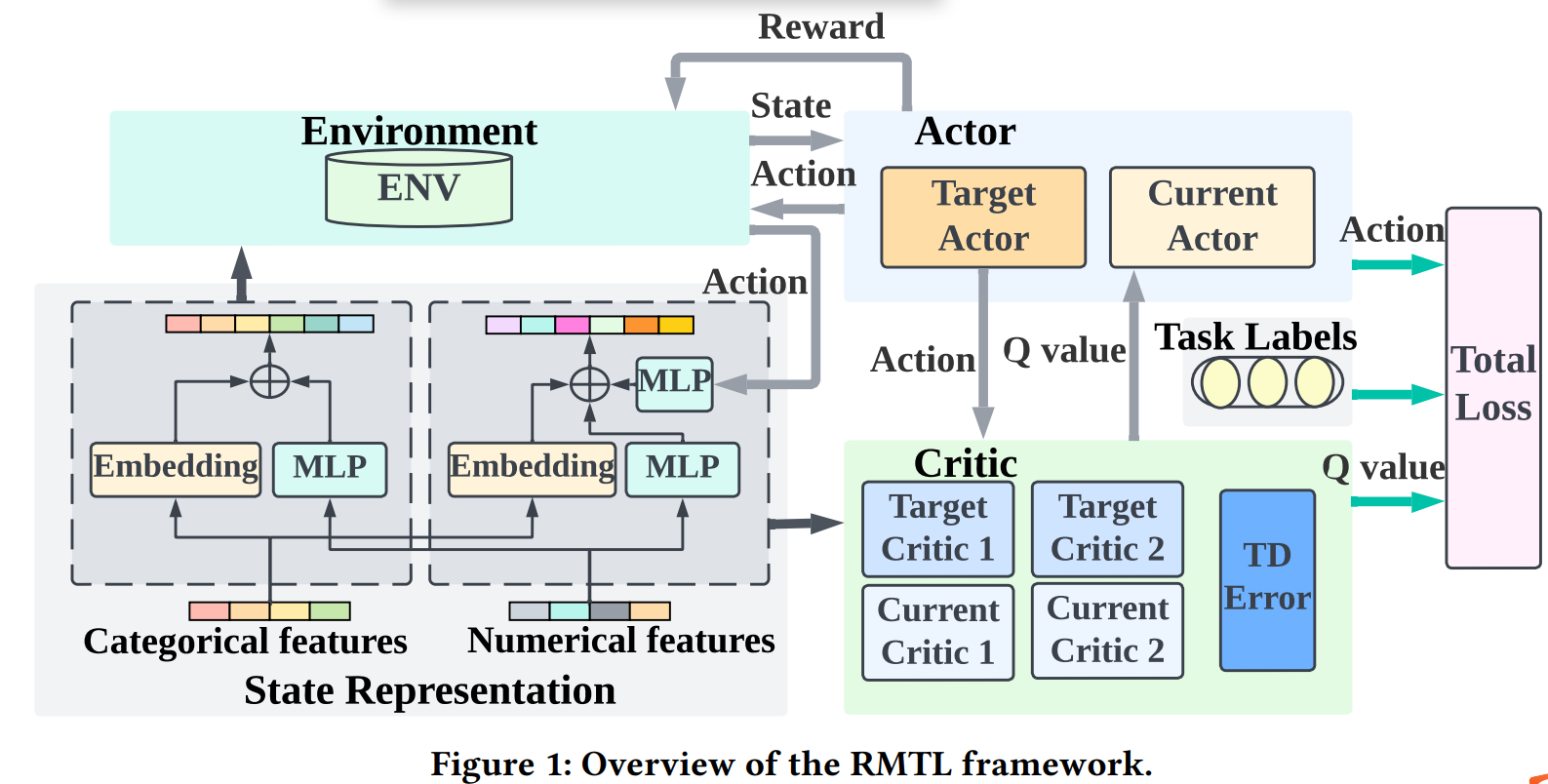
我们在图 1 中展示了 RMTL 的框架,其中包含状态表示网络、参与者网络和评论家网络。 RMTL 的学习过程可以概括为两个步骤:
• 前进步骤。 给定用户-项目组合特征,状态表示网络根据时间戳𝑡处的输入特征生成状态𝑠𝑡。 然后,我们从提取状态信息的参与者网络中获取动作(𝑎1,𝑡,𝑎2,𝑡)。 动作值 (𝑎1,𝑡, 𝑎2,𝑡) 和用户-项目组合特征由 MLP 层和嵌入层进一步处理,作为批评者网络的输入,用于从批评者网络计算 Q 值 𝑄(𝑠𝑡 , 𝑎𝑘,𝑡 ;𝜙𝑘)对于每项任务𝑘。 最后,整体损失函数为


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人