
注意力机制的数学公式梳理
本文为个人阅读笔记,参考《动手学深度学习》和蒲公英书《神经网络与深度学习》,两本书对RNN和attention都有简洁明了的介绍,深入浅出。
RNN回顾
循环神经网络使用隐状态存储到时间步t-1的序列信息:
时间步的隐状态可以用当前输入和先前隐状态来计算:
有许多不同的方法构建循环神经网络,最常见的隐状态计算方式:
输出层则类似于多层感知机中的计算:
循环神经网络存在梯度爆炸和梯度消失、只能建立短距离依赖关系和局部编码,且无法并行计算;使用全连接网络可以直接建模远距离依赖,但无法处理变长的输入序列、根据输入长度改变连接权重的大小。利用注意力机制可以有效解决。
注意力
比起RNN这种token-by-token的时序处理方式,注意力机制采用一种“软性”的信息选择机制,对所有输入信息进行加权平均,其选择的信息是所有输入向量在注意力分布下的期望:
其中, 是一个包含 个元素的向量序列, 是一个查询向量, 是第 个元素的权重,满足 。期望值 中 表示被选择信息的索引位置。
这个模型可以通过控制注意力分布 来使查询向量 更加关注向量序列 中的特定元素,从而更好地处理信息。
注意力分布 计算方式为:
其中, 是注意力打分函数,用来衡量 和查询向量 之间相似度,可以用加性模型、点积模型、缩放点积模型、或双线性模型计算。
键值对注意力
以上是普通的注意力机制(),更常用的键值对注意力函数如下:
使用注意力机制的优点是可以处理输入序列中的重要部分,削减噪声部分,提高计算效率。对于翻译任务,一个词的翻译应该与原句子中的特定词汇相关,而不是与整个句子相关,因此利用注意力机制使代表原/目标语的端到端模型表现更加优秀。
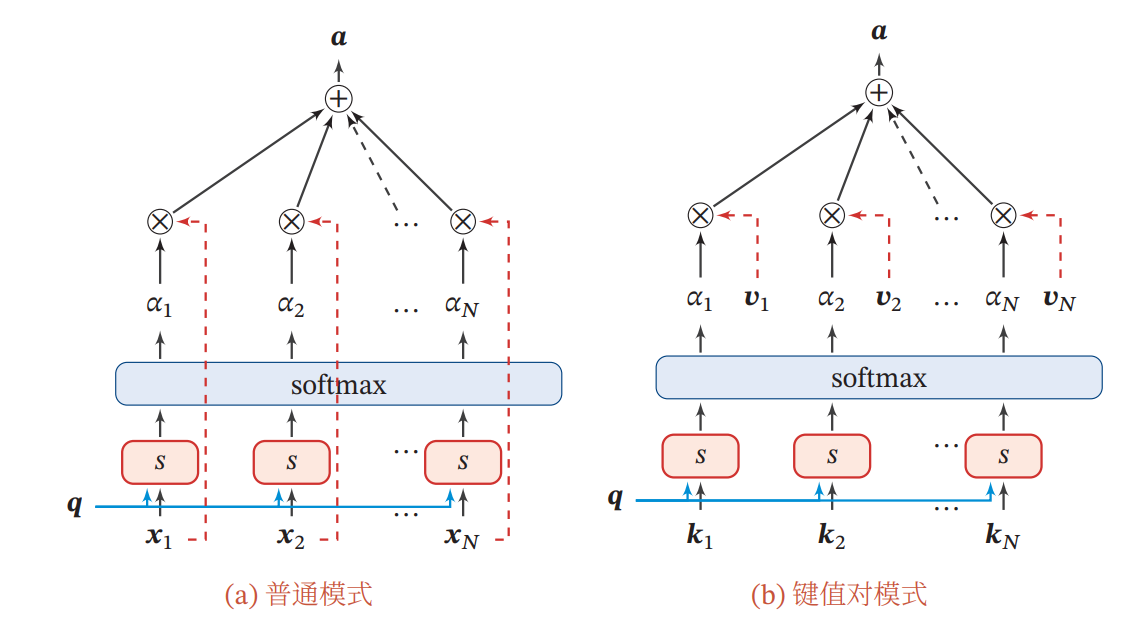
多头注意力
Transformer中用到的多头注意力能并行地从输入信息中选取多组信息:
其中 表示 个查询集合,每个查询集合具有相同的维度,即 。 表示第 个查询集合和 的注意力表示, 表示向量拼接。在这个公式中,多个查询 是用来探索数据中丰富性的。具体来讲,通过利用多个不同的查询向量 ,多头注意力机制可以在不同的方向上关注不同的特征。
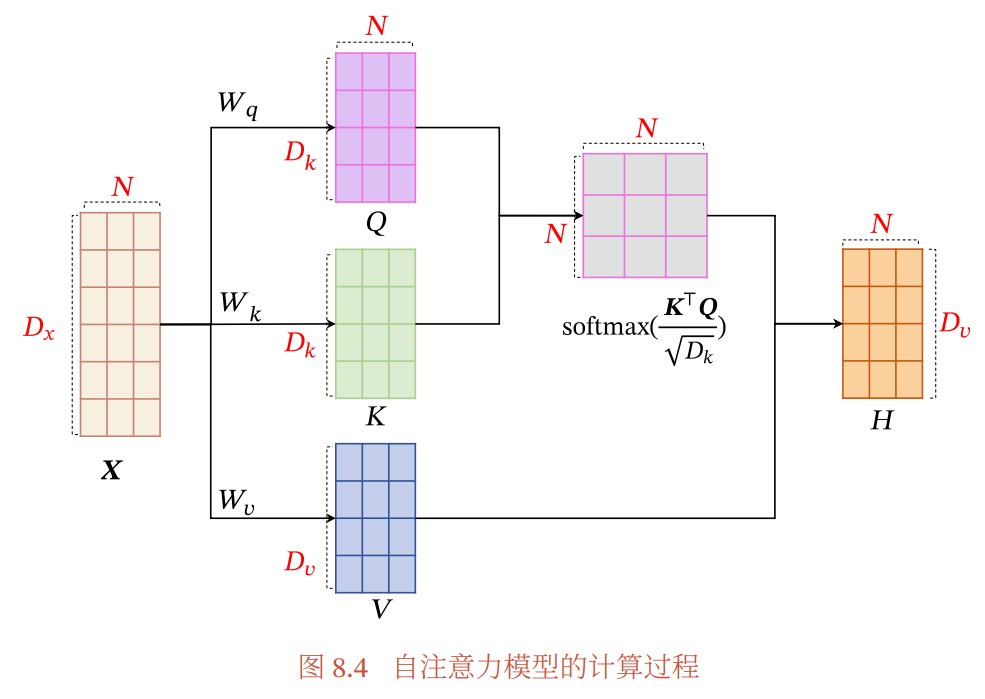
自注意力
相比普通的全连接模型,自注意力模型可以动态生成连接的权重。
对于整个输入序列 , 将其线性映射到三个不同的空间:
分别是由查询向量、键向量和值向量构成的三个投影矩阵.
如果使用缩放点积来作为注意力打分函数, 输出向量序列为:
是矩阵𝑸 和𝑲 中列向量的维度.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)