期中爬虫综合作业
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
一、了解网站
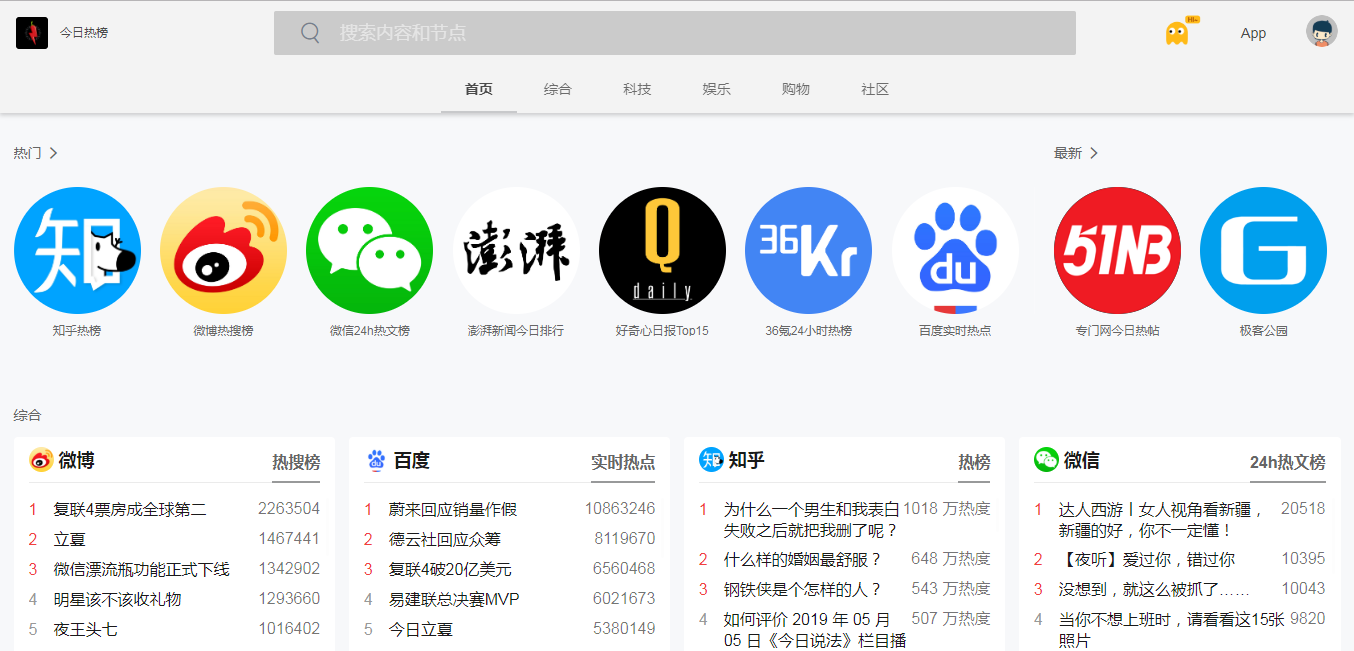
今日热榜是一个非常不错的新闻资讯网站,这里更多的一些新闻信息都可以及时的查看,及时的获取,需要看的一些行业新闻都可以让你分分钟解决自己的问题。
今日热榜网站特色:
1.这里需要的一些信息都可以看看,还是蛮值得期待的!
2.所有的资金都可以及时的获取,这里掌握最新的热点资讯,让你获取更多的信息!
3.每天都可以搜罗全网最新的一些新闻信息,这里真的蛮开心
二、分析网站
网站分别分为:综合、科技、社区等模块
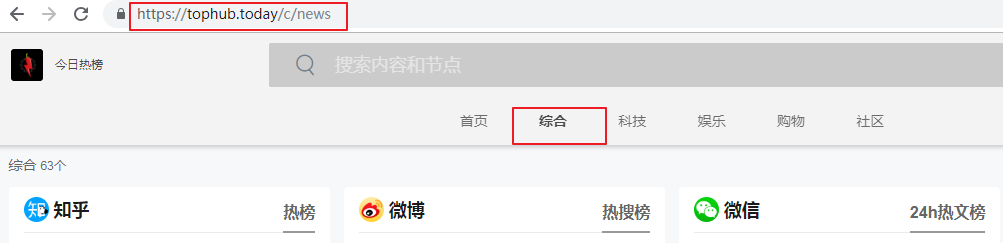
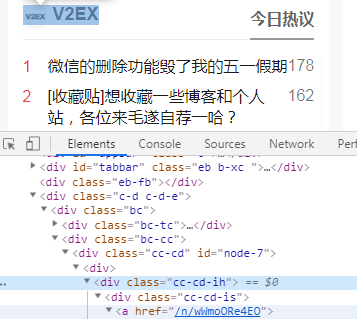
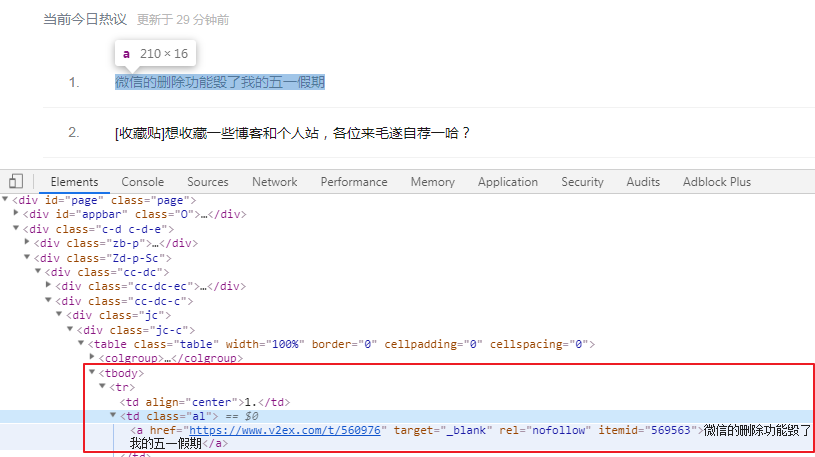
利用浏览器检查功能了解社区模块下的,V2EX的今日热议的节点链接
点击链接,进入V2EX的今日热议节点网站
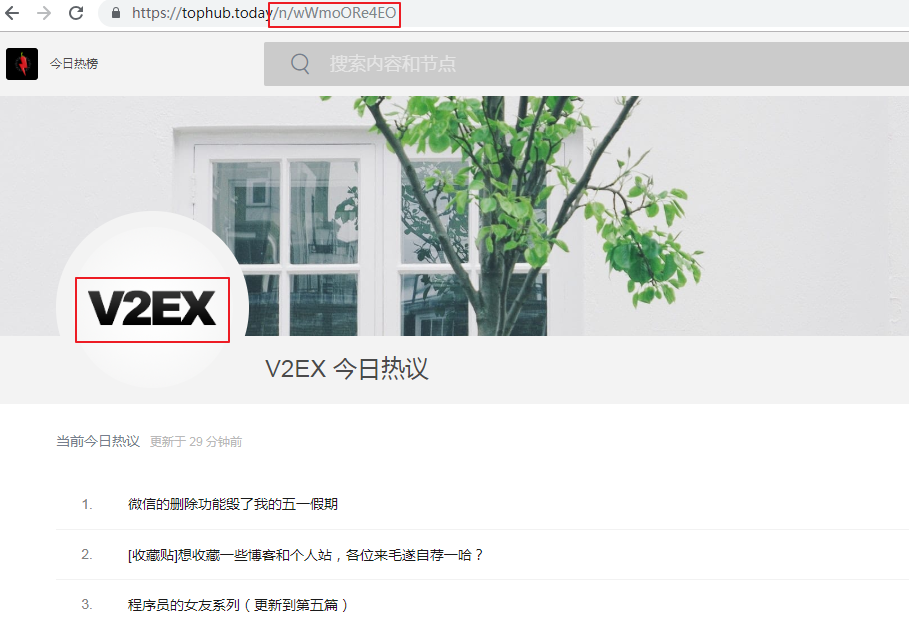
爬虫需求:爬取每个节点网站的标题
分析:利用浏览器检查功能,观察 '标题' 代码的共通性
三、代码
获取各模块的节点网站的链接:
1 def get_model_url(): 2 ua = UserAgent() 3 headers = {'User-Agent': ua.random} 4 tag_set = set() 5 6 url = 'https://tophub.today/c/{}?p={}' 7 subjects = ['news', 'tech', 'community'] 8 9 for sub in subjects: 10 for page in range(1, 10): 11 res = requests.get(url.format(sub, page), headers=headers) 12 res.encoding = 'utf-8' 13 soup = BeautifulSoup(res.text, 'lxml') 14 for span in soup.select('.cc-cd-is > a'): 15 tag_set.add(span['href']) 16 time.sleep(random.random() * 2) 17 18 return tag_set
爬取各模块的所有节点网站的标题,得到标题列表,写入到txt文件,拼接成字符串
1 def get_model_reci(tags_set): 2 print(tags_set) 3 ua = UserAgent() 4 headers = {'User-Agent': ua.random} 5 txt_list = [] 6 7 print('get_model_reci前'+ str(time.strftime('%m-%d %H:%M:%S', time.localtime(time.time())))) 8 9 url1 = 'https://tophub.today{}' 10 for ci in tags_set: 11 res = requests.get(url1.format(ci), headers=headers) 12 res.encoding = 'utf-8' 13 soup = BeautifulSoup(res.text, 'lxml') 14 for a in soup.select('tbody > tr > .al > a'): 15 txt_list.append(a.text.strip()+'\n') 16 time.sleep(random.random() * 2) 17 18 print('get_model_reci后' + str(time.strftime('%m-%d %H:%M:%S', time.localtime(time.time())))) 19 f = open('title_txt','w',encoding='utf-8') 20 f.writelines(txt_list) 21 f.close() 22 print('文件写入后' + str(time.strftime('%m-%d %H:%M:%S', time.localtime(time.time())))) 23 24 return ''.join(txt_list)
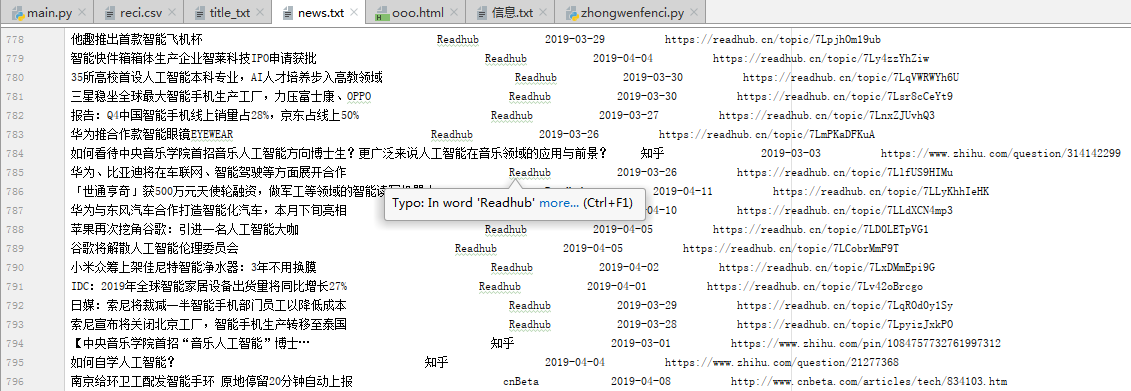
爬取得到39000条信息写入title_txt.txt文件:
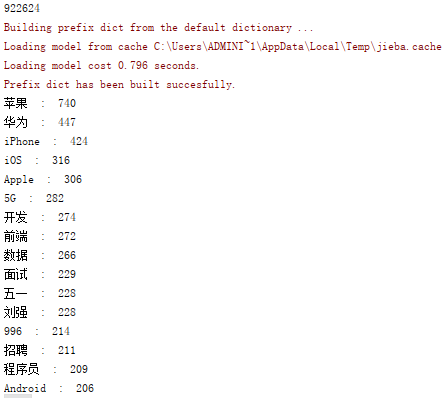
对爬取的标题信息进行分词,并计算其词频,进行排序,返回词频最高的前100个词的列表:
1 def get_reci(txt): 2 words = [] # 分词列表 3 4 f = open('title_txt', 'r', encoding='utf-8') 5 txt_list = f.readlines() 6 f.close() 7 8 for line in txt_list: 9 txt += line.strip() 10 print(len(txt)) 11 cut_words = list(jieba.cut(txt)) # 分词 12 13 reci_dict = {'l': 1} 14 for word in cut_words: 15 if word not in stop_words and len(word) > 1 : 16 if word in words: 17 reci_dict[word]+=1 18 continue 19 words.append(word) 20 reci_dict[word] = 1 21 22 dic = sorted(reci_dict.items(), key=lambda item: item[1], reverse=True) 23 24 l = [] 25 for i in range(100): 26 l.append(dic[i][0]) 27 print(dic[i][0], " : ", dic[i][1]) 28 29 return l
打印词云,并保存词频到reci.csv文件

任意选择词频最高的前100个词,模拟 今日热榜 的搜索get方法得到 相关热词新闻的标题 、出处、时间、链接,将其写入news.txt文件
1 def get_info_from_search(search_tag): 2 url = 'https://tophub.today/search?q=%E5%88%98%E5%BC%BA' 3 ua = UserAgent() 4 headers = {'User-Agent': ua.random} 5 txt_list = {} 6 7 url1 = 'https://tophub.today/search?q={}' 8 9 for t in search_tag: 10 print(t) 11 url = quote(url1.format(t), safe=";/?:@&=+$,", encoding="utf-8") # 中文编码 12 print(url) 13 res = requests.get(url, headers=headers) 14 res.encoding = 'utf-8' 15 soup = BeautifulSoup(res.text, 'lxml') 16 17 tmp = [] 18 title = [] 19 href = [] 20 author = [] 21 p_time = [] 22 for a_content in soup.select('tbody > tr > .al > a'): 23 title.append(a_content.text) 24 for a_href in soup.select('tbody > tr > .al > a'): 25 href.append(a_href['href']) 26 for td in soup.select('tbody > tr > td:nth-of-type(4)'): 27 author.append(td.text) 28 for td in soup.select('tbody > tr > td:nth-of-type(5)'): 29 p_time.append(td.text) 30 time.sleep(random.random() * 2) 31 32 for i in range(len(title)): 33 tmp.append(title[i]) 34 tmp.append(href[i]) 35 tmp.append(author[i]) 36 tmp.append(p_time[i]) 37 38 txt_list[t] = tmp 39 return txt_list
观察get方式搜索关键词
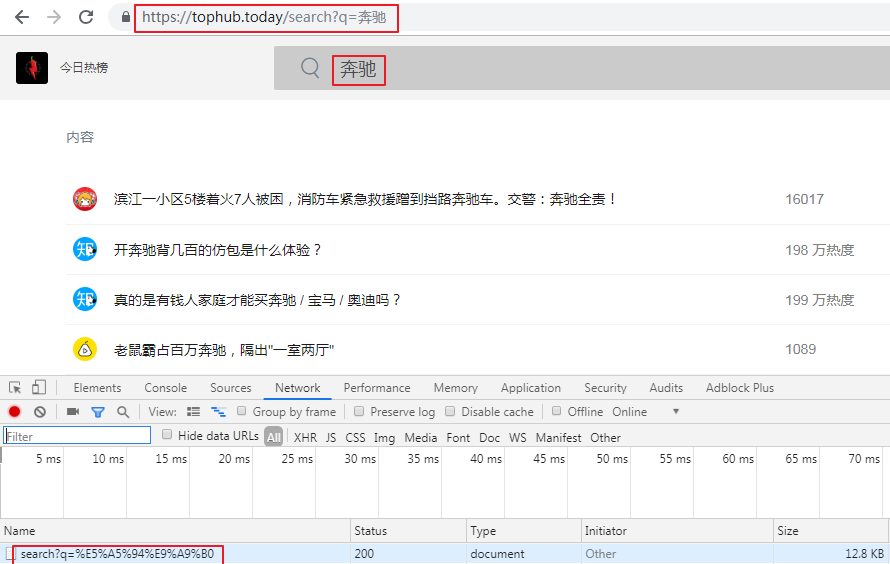
得到相关热词新闻的标题 、出处、时间、链接,将其写入news.txt文件