复合数据类型,英文词频统计
1 ###列表### 2 list = ['lin', 'kai', 14, 29, 'xan'] 3 4 # 增 5 list.append(22) # 增加到列表尾 6 list.extend(['extend']) # 添加指定列表的所有元素 7 list.insert(2, '插入') # 在指定位置插入一个元素 8 print(list) 9 10 # 删 11 list.remove('xan') # 删除列表中值为'xan'的元素 12 list.pop() # 删除最后一个元素 13 list.pop(1) # 删除指定位置元素 14 del list[2:4] # 删除从2到4的元素 15 list.clear() # 删除所有项 16 print(list) 17 18 # 改 19 list = ['2', 'lin', 'kai', 14, 29, 'xan'] 20 list[0] = 'ig' 21 print(list) 22 23 # 查 24 print(list.index(14)) # 返回第一个值为x的元素的索引 25 26 # 遍历 27 for i in list: 28 print(i) 29 30 31 32 ###元祖### 33 tuple = ('Google', 'Baidu', 'oo', 'uu', 15, 26) # 元祖 34 35 # 元组中的元素值是不允许修改的,但我们可以对元组进行连接组合 36 tup1 = (1, 2, 3) 37 tup2 = ('a', 'b', 'c') 38 39 # 创建新的元组 40 tup3 = tup1 + tup2 41 print(tup3) 42 43 # 访问元祖 44 print("tup1[0]: ", tup1[0]) 45 46 # 遍历 47 for i in tup1: 48 print(i) 49 50 51 52 ###字典### 53 dict = {'a': '1', 'b': '2', 'c': '3'} # 字典 54 55 # 删 56 del dict['b'] # 删除键 'b' 57 dict.clear() # 清空字典 58 del dict # 删除字典 59 60 dict = {'a': '1', 'b': '2', 'c': '3'} 61 # 改 62 dict['a'] = '9' 63 # 增 64 dict['d'] = '4' 65 # 查 66 print(dict['a']) 67 68 # 遍历 69 for i, j in dict.items(): 70 print(i, ":\t", j) 71 72 73 74 ###集合### 75 set1 = {1, 2, 3} # 集合 76 set2 = set((1, 2, 3)) # 也是集合 77 print(set1) 78 print(set2) 79 80 # 增 81 set1.add(4) 82 print(set1) 83 84 # 删 85 set2.remove(1) # 移除值为1的元素,如果不存在则会发生错误 86 set2.discard(1) # 移除值为1的元素,如果不存在不会发生错误 87 set2.pop() # 随机删除一个元素 88 set2.clear() 89 print(set2) 90 91 # 查 92 print(1 in set1) # 存在则返回True 93 94 # 集合无序,不能修改指定的元素 95 # 遍历 96 for num in set1: 97 print(num)
总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 括号
- 有序无序
- 可变不可变
- 重复不可重复
- 存储与查找方式
| 列表 | 元祖 | 字典 | 集合 | |
|
括号 |
[] | () | {} | {} |
|
有序无序 |
有序 | 有序 | 无序,自动正序 | 无序 |
|
可变不可变 |
可变 | 不可变 | 不可变 | 可变 |
|
重复不可重复 |
可以 | 可以 | 可以 | 不可以 |
|
存储与查找方式 |
值 | 值 | 键值对(键不能重复) | 键(不能重复) |
词频统计
-
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
- 自定义停用词表
- 或用stops.txt
8.输出TOP(50)
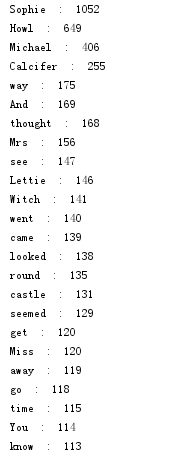
排序好的单词列表word保存成csv文件

1 import re 2 import pandas 3 from stop_words import get_stop_words 4 5 stop_words = get_stop_words('english') 6 7 file = open("../第三次作业/Howl’s Moving Castle.txt", "r+", encoding='UTF-8') 8 str = file.read() 9 10 str = re.sub('[\r\n\t,!?:;“‘’.\"]', '', str) 11 words = str.split(" ") 12 13 single = [] # 分词数组 14 excluding_words = [] # 排除的单词 15 quantity = [] # 单词次数 16 17 for word in words: 18 if (word not in single and word not in stop_words): 19 single.append(word) 20 21 tmp = single.copy() 22 while tmp: 23 # print(tmp[0], "出现次数:", words.count(tmp[0]), end=" ") 24 quantity.append(words.count(tmp[0])) 25 tmp.pop(0) 26 27 dic = dict(zip(single, quantity)) # 合成字典 28 dic = sorted(dic.items(), key=lambda item: item[1], reverse=True) # 排序 29 30 for i in range(50): 31 print(dic[i][0], " : ", dic[i][1]) 32 33 pandas.DataFrame(data=dic).to_csv('fenci.csv', encoding='utf-8') 34 35 print(stop_words) 36 37 file.close()
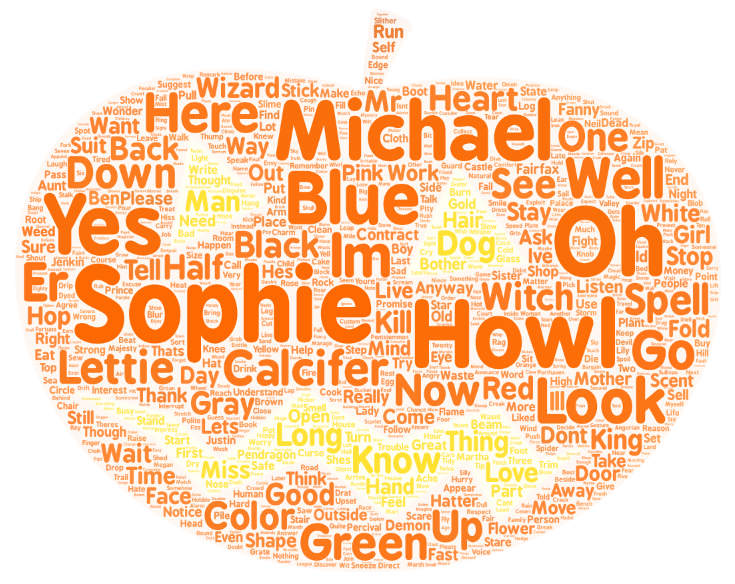
9.可视化:词云