



雪花算法实验
算法原理
SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图:

-
1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
-
41bit-时间戳,用来记录时间戳,毫秒级。
- 41位可以表示个数字,
- 如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至
- 也就是说41位可以表示年
-
10bit-工作机器id,用来记录工作机器id。
- 可以部署在个节点,包括5位datacenterId和5位workerId
- 5位(bit)可以表示的最大正整数是,即可以用0、1、2、3、....31这32个数字,来表示不同的datecenterId或workerId
-
12bit-序列号,序列号,用来记录同毫秒内产生的不同id。
- 12位(bit)可以表示的最大正整数是,即可以用0、1、2、3、....4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
SnowFlake可以保证:
- 所有生成的id按时间趋势递增
- 整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分)
C#版雪花算法:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace snowflake { public class SnowflakeIDcreator { private static long workerId=1; //机器ID private static long twepoch = 68020L; //唯一时间,这是一个避免重复的随机量,自行设定不要大于当前时间戳 private static long sequence = 0L; private static int workerIdBits = 4; //机器码字节数。4个字节用来保存机器码(定义为Long类型会出现,最大偏移64位,所以左移64位没有意义) private static long maxWorkerId = -1L ^ -1L << workerIdBits; //最大机器ID private static int sequenceBits = 10; //计数器字节数,10个字节用来保存计数码 private static int workerIdShift = sequenceBits; //机器码数据左移位数,就是后面计数器占用的位数 private static int timestampLeftShift = sequenceBits + workerIdBits; //时间戳左移动位数就是机器码和计数器总字节数 private static long sequenceMask = -1L ^ -1L << sequenceBits; //一微秒内可以产生计数,如果达到该值则等到下一微妙在进行生成 private static long lastTimestamp = -1L; private static object lockObj = new object(); /// <summary> /// 设置机器码 /// </summary> /// <param name="id">机器码</param> public static void SetWorkerID(long id) { SnowflakeIDcreator.workerId = Id; } public static long nextId() { lock (lockObj) { long timestamp = timeGen(); if (lastTimestamp == timestamp) { //同一微妙中生成ID SnowflakeIDcreator.sequence = (SnowflakeIDcreator.sequence + 1) & SnowflakeIDcreator.sequenceMask; //用&运算计算该微秒内产生的计数是否已经到达上限 if (SnowflakeIDcreator.sequence == 0) { //一微妙内产生的ID计数已达上限,等待下一微妙 timestamp = tillNextMillis(lastTimestamp); } } else { //不同微秒生成ID SnowflakeIDcreator.sequence = 0; //计数清0 } if (timestamp < lastTimestamp) { //如果当前时间戳比上一次生成ID时时间戳还小,抛出异常,因为不能保证现在生成的ID之前没有生成过 throw new Exception(string.Format("Clock moved backwards. Refusing to generate id for {0} milliseconds", lastTimestamp - timestamp)); } lastTimestamp = timestamp; //把当前时间戳保存为最后生成ID的时间戳 long nextId = (timestamp - twepoch << timestampLeftShift) | SnowflakeIDcreator.workerId << SnowflakeIDcreator.workerIdShift | SnowflakeIDcreator.sequence; return nextId; } } /// <summary> /// 获取下一微秒时间戳 /// </summary> /// <param name="lastTimestamp"></param> /// <returns></returns> private static long tillNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } /// <summary> /// 生成当前时间戳 /// </summary> /// <returns></returns> private static long timeGen() { return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds; } } }
用法:
全局里定义一次
SnowflakeIDcreator.SetWorkerID(100);
然后直接可使用:
SnowflakeIDcreator.nextId()
下面实验用100个线程同时并发生成id
1.验证是否会重复;2.测试算法速度;3.与直接lock进行id生成的区别
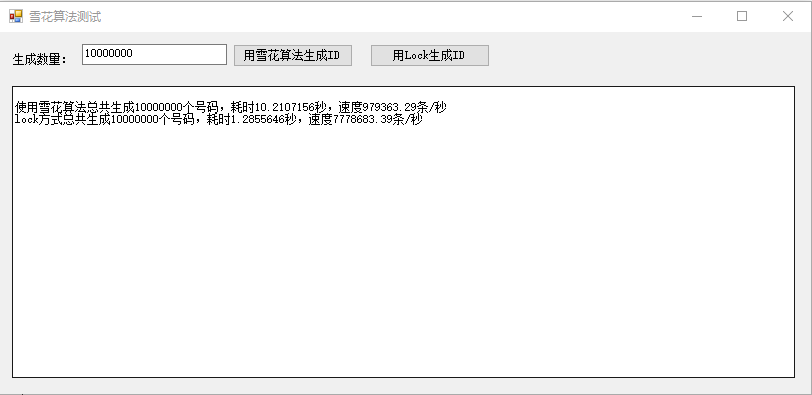
算法实验界面:
Demo代码:
using System; using System.Collections.Concurrent; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading; using System.Threading.Tasks; using System.Windows.Forms; namespace snowflake { public partial class Form1 : Form { public Form1() { InitializeComponent(); } ConcurrentBag<long> ids = new ConcurrentBag<long>(); ManualResetEvent resetEvent = new ManualResetEvent(false); /// <summary> /// 用雪花算法生成id测试 /// </summary> /// <param name="sender"></param> /// <param name="e"></param> private void btnCreate_Click(object sender, EventArgs e) { int count = int.Parse(txtNum.Text); ids = new ConcurrentBag<long>(); SnowflakeIDcreator.SetWorkerID(100); resetEvent.Reset(); List<Task> tsks = new List<Task>(); for (int i = 0; i < 100; i++) { tsks.Add( Task.Factory.StartNew(new Action(()=>{ taskprocess(); }))); } DateTime dt1 = DateTime.Now; resetEvent.Set(); Task.WaitAll(tsks.ToArray()); double takeseconds = (DateTime.Now - dt1).TotalSeconds; double speed = ids.Distinct().Count() / takeseconds; txtMsg.Text += "\r\n"; txtMsg.Text += string.Format("使用雪花算法总共生成{0}个号码,耗时{1}秒,速度{2}条/秒", ids.Distinct().Count(), takeseconds,speed.ToString("F2")); } private void taskprocess() { resetEvent.WaitOne(); for (int i = 0; i < 100000; i++) { ids.Add(SnowflakeIDcreator.nextId()); } } /// <summary> /// 直接用lock生成id /// </summary> /// <param name="sender"></param> /// <param name="e"></param> private void button1_Click(object sender, EventArgs e) { int count = int.Parse(txtNum.Text); ids = new ConcurrentBag<long>(); resetEvent.Reset(); List<Task> tsks = new List<Task>(); for (int i = 0; i < 100; i++) { tsks.Add(Task.Factory.StartNew(new Action(() => { taskprocess2(); }))); } DateTime dt1 = DateTime.Now; resetEvent.Set(); Task.WaitAll(tsks.ToArray()); double takeseconds = (DateTime.Now - dt1).TotalSeconds; double speed = ids.Distinct().Count() / takeseconds; txtMsg.Text += "\r\n"; txtMsg.Text += string.Format("lock方式总共生成{0}个号码,耗时{1}秒,速度{2}条/秒", ids.Distinct().Count(), takeseconds, speed.ToString("F2")); } private void taskprocess2() { resetEvent.WaitOne(); for (int i = 0; i < 100000; i++) { ids.Add(IDCreator.getSeqID()); } } } }
其中lock方法生成的代码:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace snowflake { public class IDCreator { static long m_curid = 1; static object mlock = new object(); public static long getSeqID() { lock (mlock) { if (m_curid > long.MaxValue) { m_curid = 1; } m_curid++; return m_curid; } } } }
测试结论:雪花算法每秒生成100w条左右,而Lock方式直接生成id速度可达到777w条,只是雪花算法可以分布式,带了机器码和时间戳。如果程序基于单机运行,直接lock速度更快。

