计算机网络——HTTP协议详解
一、前言
前段时间为了研究计算机网络,看了看《计算机网络自顶向下方法》这本书。不得不说这真是一本好书,内容详细,而且讲解的浅显易懂,采用了大量类比的方式进行讲解,而不是单纯的叙述理论,同时在每一章的后面都有大量的练习题以及很有意思的编程题,所以开头先来推荐一波。这本书我暂时只看到了第二章,刚看完HTTP的内容,所以写一篇HTTP相关的博客,就当是记笔记了。
二、详解
2.1 HTTP概述
HTTP是一个应用层的协议,全称是超文本传输协议,它是web的核心。HTTP由两个程序实现——客户端程序和服务端程序,而HTTP的作用简单来说就是客户端向服务器发请求,而服务器根据请求做出响应。HTTP定义了Web客户端向服务器请求资源的方式,以及Web服务器向客户端回送资源的方式,也就是HTTP的请求+响应模型。客户端向服务器发送请求报文请求资源,服务器接收到请求,向客户端回送包含这些资源的响应报文。

HTTP基于TCP协议,由TCP协议支持数据的传输,这说明HTTP协议是一个面向连接的可靠协议。当客户端向服务器请求资源时,首先将与服务器建立一个TCP连接,当TCP连接建立成功时,客户端和服务器之间就可以通过套接字接口访问TCP,客户端通过TCP连接传输请求报文,而服务器也通过这个TCP连接回送响应报文及资源。由于TCP的可靠传输,保证了HTTP的报文一定能够完整的送到服务器上,而服务器的响应也能完整的回送到客户。
HTTP请求的资源一般是一个Web页面,而一个Web页面是由一个或多个对象组成的,这个对象可能是一个html文件,一张图片,甚至是一段视频或者小程序。对于HTTP来说,组成一个Web页面的这些对象并不属于同一个资源,每一个对象都是一个单独的资源,需要逐一请求。假设我们向服务器请求一个Web页面,这个页面由一个html文件以及5张图片组成(html通过路径引用图片),则这个页面共有6个对象,当服务器接收到客户端对页面的请求后,将html文件通过响应报文返回,而客户端接收到响应的html文件后,发现它还引用了5张图片,这时客户端将再次发送5个HTTP请求,来分别请求这5张图片。
服务器向客户端发送被请求的文件,但是不记录任何客户的信息,所以当你连续向服务器请求同一份资源两次时,服务器也会给你响应两次,不会因为你已经请求过就不给你响应了。正是因为HTTP不记录客户的信息,所以它也是一个无状态协议。
2.2 非持续连接和持续连接的HTTP
大多数情况下,我们对Web服务器发出请求时,都不止发出一个请求,比如上面说到的包含5张图片的页面。那这个时候就需要考虑一个问题,对于这多次目的地相同的请求/响应,HTTP是对每一个请求/响应使用同一个TCP连接,还是每次请求单独创建一个TCP连接呢?这里就分两种情况,多次请求/响应使用同一个TCP连接的被称为持续连接,而每个请求/响应单独使用一个TCP连接,则被称为非持续连接。而HTTP默认使用的是持续连接,但是也可以通过配置,改用非持续连接。下面就来简单说一说两者的区别。
(1)非持续连接
非持续连接表示对于每一个请求/响应,都将单独建立一个TCP连接来进行。假设我们还是以之前说过的例子来讲解:我们向服务器请求一个包含5张图片的页面,而页面的路径假设就是HTTP://www.tewuyiang.cn/index.html(这是我的个人服务器,目前部署了一个制作简单的小游戏),当我们请求这个路径时,将发生以下情况:
HTTP客户进程通过80端口向服务器www.tewuyiang.cn发起一个TCP连接,80端口时HTTP的默认端口;HTTP客户进程通过套接字向服务器发送一个请求报文,请求资源的路径为/index.html;HTTP服务器进程通过套接字接收到该请求,从它的存储器(如:RAM)中搜索HTTP://www.tewuyiang.cn/index.html这个资源,生成一份响应报文,并将html页面封装进响应报文中,并通过套接字将此报文回送给客户端;HTTP服务器通知TCP断开连接(但是直到TCP确认客户端已经接收到完整的报文后,才会将连接断开);HTTP客户进程完整的接收到响应报文好,TCP连接断开。客户端解析响应报文后,发现封装的对象是一个html文件,且html文件包含5张图片的引用;- 重复上面步骤
1-4,请求页面包含的5张图片;
非持续连接的缺点很明显,那就是对于每一个请求/响应都需要建立TCP连接,这样将导致服务器需要维护的连接大大增加,比如一个页面包含10张图片,那总共就得2建立11给连接,这样将给服务器造成巨大的压力。而好处就是,多个连接可以同时建立(一个浏览器一般可以同时建立5-10个连接),表示有多个通道,通道之间传输数据是并行的,多个请求/响应可以同时进行,这样就不会造成排队的情况,效率较高。
(2)持续连接
持续连接表示某个客户端与一个服务器建立连接后,在一段时间内,向服务器发送的请求以及服务器发送的响应,都可以通过这一条连接来进行。这个应该很好理解。而持续连接也分为两种:
- 不带流水线的持续连接:这表示一次性只能进行一个请求/响应,而下一个必须得等上一次完成后才进行;
- 带流水线的持续连接:这表示对对象的请求可以一个个发出,而不需要等未完成的请求结束(但不是完全并行);
对于长时间未使用的连接,HTTP会将它关闭,而这个超时时间也可以进行配置。
持续连接的好处也很明显,那就是节省资源,多个请求共用一个连接;但是缺点就是效率可能相对要低一些。HTTP的默认模式就是带流水线的持续连接。
2.3 HTTP报文格式
接下来,我们就来谈一谈HTTP协议的报文格式吧。HTTP的报文分为请求报文和响应报文。
(1)请求报文
下面是一段我从浏览器截取下来的HTTP的请求报文,请求的资源是一张图片:

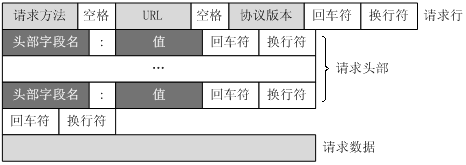
HTTP请求报文的第一行为请求行,剩下的都叫首部行,下面我来一行一行解释上面的内容:
首先是第一行,也就是请求行,它包含三部分内容:请求方法,资源路径,HTTP协议版本,它们三者由空格隔开。第一部分的请求方法表示客户端向浏览器发送的请求的类别,我们常用的请求方式是GET和POST请求:
- GET:向服务器请求资源,服务器将请求的资源返回;
- POST:向服务器提交数据并请求处理(比如说提交表单),数据被包含在请求体中。
POST请求可能会导致新的资源的建立和/或已有资源的修改;
上面两个请求方式都是HTTP1.0中定义的,而HTTP1.0除了上面两个请求方法,还有一个HEAD请求:
- HEAD:类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头;
在HTTP1.1中,又新增了六种请求,分别是OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法,它们的定义我就不一个个列出来了,大家可以点击后面的连接查阅——HTTP请求方法。
紧随请求方法之后的是资源在HTTP服务器上的路径,报文中的路径是/img/prop3.png,表示我们请求的是HTTP服务器路径下,img文件夹下的prop3.png这张图片。这之后的HTTP1.1表示的就是这次请求使用的HTTP的版本了。
请求行下面的都是首部行,而首部行都是name: value格式的,name表示这个首部的名字,而value就是首部的具体值了。第一个首部行的名字叫Host,表示的是HTTP服务器所在的地址,而这里的地址是www.tewuyiang.cn。第二个首部行的名字是Connection,这个表示的就是我们上面提到的HTTP的连接类型了,而它的值是keep-alive,就是告诉服务器,使用的是持续连接,若值为close,表示的就是非持续连接。第三个首部行User-Agent的作用就是指明用户代理,也就是告诉服务器,发送这次HTTP请求的浏览器的类型。第四个首部行Accept的作用告诉服务器自己希望接收的资源的类型,若服务器响应的资源与此不一致,将会报错,而从上面的报文中可以看出,这个请求希望受到一张图片。Referer的作用是用来防止恶意请求,提高访问资源的安全性。Accept-Encoding的作用是告知服务器,当前浏览器支持的编码类型。Accept-Language的作用是告知HTTP服务器客户端想要获取资源的语言版本,若服务器中不包含此语言版本,则将回送默认版本。
下面这张图是HTTP请求报文的标准格式:
(2)响应报文
同样,我们先来看一段响应报文:
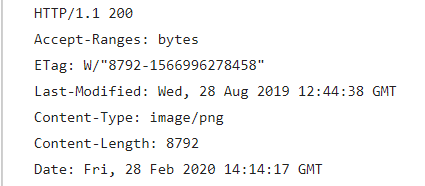
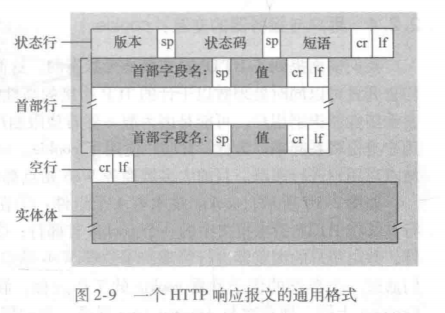
响应报文的第一段由两部分组成,分别是HTTP版本以及状态码,上面的报文中,HTTP的版本为1.1,与请求的版本相同,之后紧跟的状态码为200,这是最常见的状态码,表示请求成功。若还想知道其他状态码,可以点击菜鸟教程查阅,这里列出常见的四种:
- 200 - 请求成功;
- 301 - 资源(网页等)被永久转移到其它URL;
- 404 - 请求的资源(网页等)不存在;
- 500 - 内部服务器错误;
第一行之后的这些行,被称为首部行,与请求报文中的首部行类似,也是name: value。第一个首部行的名称叫做Accept-Ranges,它的作用是告知客户端,此资源是否支持范围请求,而范围请求可以支持断点续传和多线程分片下载,bytes表示支持,而none表示不支持。Last-Modified的作用后面说缓存时单独拿出来说。Content-type的作用就是标识资源的类型,这里image/png表示资源是一张图片。Content-Length表示资源的字节数,图片中的值是8729,表示这张图片共有8729个字节。最后一个Date的作用就是表示服务器发送该响应报文的日期时间。
下面这一张是HTTP响应报文的标准格式,可以看到,在最后面还有一个叫实体体的部分,这里就是用来放服务器回送的资源的,例如请求的图片。
2.4 Web缓存器
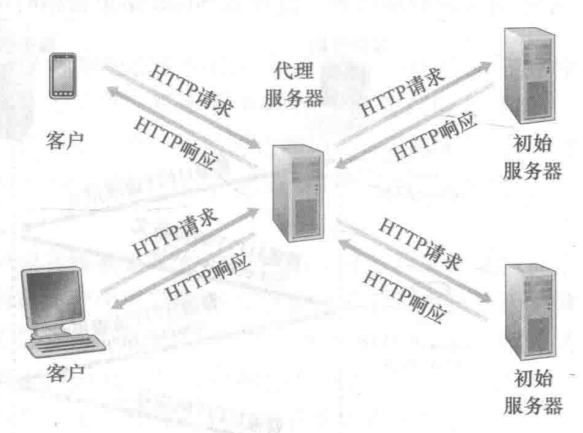
Web缓存器也叫代理服务器,它在某些情况下可以代替HTTP服务器满足客户的需求。Web缓存器有自己的存储空间,并保存有最近被请求资源的副本。它的作用故名思意,就是提供缓存机制的。若部署了Web缓存器,则可以配置浏览器,使得浏览器的HTTP请求首先发送至Web缓存器,下面我们通过一个例子来讲解Web缓存器的机制。
假设我现在要请求www.tewuyiang.cn这个服务器上的prop3.png这张图片,结果将发生以下情况:
HTTP客户端创建一个到Web缓存器的TCP连接,并向Web缓存器发送一个请求报文;Web缓存器接收到请求报文,查看自己的本地是否包含被请求资源的副本,若包含,则由Web缓存器创建响应报文,并将此副本通过响应报文返回给HTTP客户端;- 若
Web缓存器中不包含此资源的副本,则Web缓存器将向HTTP服务器(这里指的就是www.tewuyiang.cn)发起一个TCP连接,并向服务器请求客户端需要的资源; - 服务器创建响应报文,将请求的资源响应给缓存器,缓存器接收到响应报文,解析响应报文携带的资源,并复制一份副本存储在本地,然后重新创建一份响应报文,并将副本封装进其中,发送给最初请求资源的客户端;
通过上面的步骤我们可以看到,Web缓存器在这个过程中,既充当服务器的角色,又充当客户端的角色。而部署了Web缓存器后,将大大减少服务器响应资源的时间。
2.5 条件GET方法
介绍完上面的Web缓存器后,很多人可能会有一个疑问:怎么能够保证Web缓存器上的资源是最新的呢,若服务器上的资源被更新,而我们请求获得的却是缓存器上没有被改变的旧资源怎么办?HTTP自然是有办法解决这个问题,这时候就要用到我们在讲解响应报文时跳过的首部行Last-Modified了,而这种机制叫做条件GET。
Last-Modified首部行记录的是当前被请求的资源,在服务器上最后被修改的时间。当我们请求一个Web缓存器上没有的资源时,Web缓存器向HTTP服务器转发该请求,而服务器响应缓存器,同时在响应报文中包含Last-Modified首部行。Web缓存器在存储资源的副本时,同时也将Last-Modified的值存了下来。当下一次有客户端请求此资源时,Web缓存器会发送一个条件GET请求到服务器,请求中包含这个时间值,且此时的命名为Last-Modified-Since。服务器接收到这个时间值后,将它与服务器本地记录的这个资源的最后修改时间进行比较,若两者相等,表示上次请求到这次请求之间,这个资源并未更新,服务器将告知Web缓存可以直接使用它存储的副本;若两者不相同,则服务器会将最新的资源,以及新的Last-Modified发送至Web缓存器,Web缓存器更新本地的副本,并响应给客户端。
三、总结
上面的内容对HTTP协议以及它的一些机制进行了一个大致的介绍,相信看完之后,能够让你对HTTP有一个大致的了解。当然HTTP的内容肯定不止这些,只是限于篇幅,以及我的知识储备,这篇博客就先写上这些吧。日后有时间,再写一写HTTP的其他部分,例如cookie和session。
四、参考
《计算机网络——自顶向下方法(原书第七版本)》

