

redis 梳理笔记(二)
一.redis 分布式
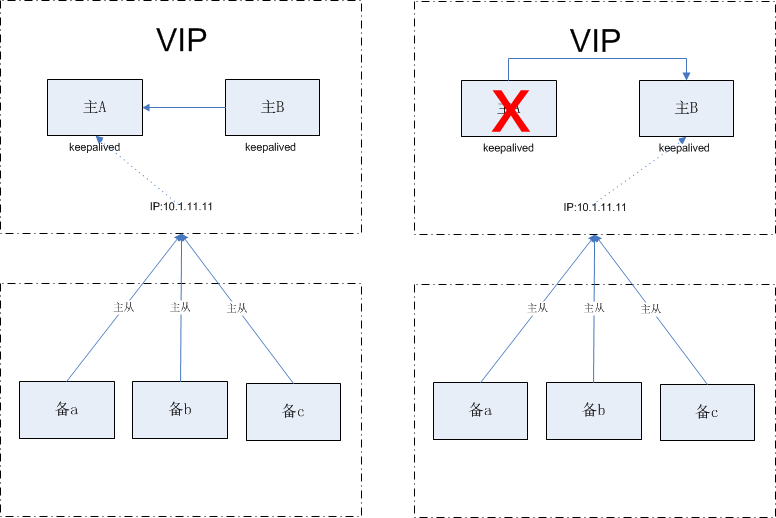
redis+keepalived (虚ip漂移)
- redis 100秒平均写入并发 3.6w (写入与keepalived监控程序无关)
- .redis 数据库内存已占有80% 100秒平均写入并发 2.6w
- 6g的redis 数据库 执行一次bgsave需要 32s 内存消耗 3g 期望内存至少预留4g
- .6g的redis 数据库 执行一次bgrewriteaof 需要 13-20秒, 1g 用完 期望预留4g
- .测试主备切换时间花费及服务可用性,数据量为6g(A 为主库, B为备库,C为从库)
A库 手动kill (13:32)keepalived 切换 服务到B库(13:35)B库备份数据库到 *.rdb, cpu 飙升 ,开始执行主从同步(13:36)B库rdb 执行完成花费37秒 开始传输*.rdb到c 库 (14:13)C库接受完毕*.rdb传输,传输花费34秒 (14:47秒)C库执行load *.rdb到内存中 (花费47秒)次秒从库数据库不可用 (15:34)主库挂掉 到完全服务可用 花费122秒
- 带宽:最大峰值 805Mb/s,约100MB/s (6g)
总结:在此过程:写3秒不可用;读 47秒不可用;切换到完全可用近2分钟
sentinel
twemproxy(vips之前架构)
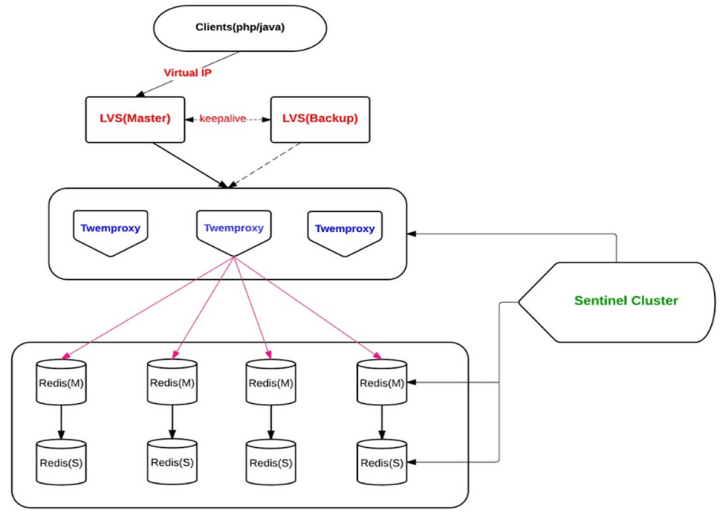
- 优点
- sharding逻辑对开发透明,读写方式跟单个redis一致
- 可以作为cache和storage的proxy
- 缺点
- 架构复杂,层次多 包含lvs、twemproxy、redis、sentinel
- 管理成本跟硬件成本很高
- 流量高的系统、proxy节点数和redis个数接近
- redis层仍然扩容能力差,预分配足够的redis存储节点
crc32 katema 网卡流量
二、redis 几种数据结构
hash
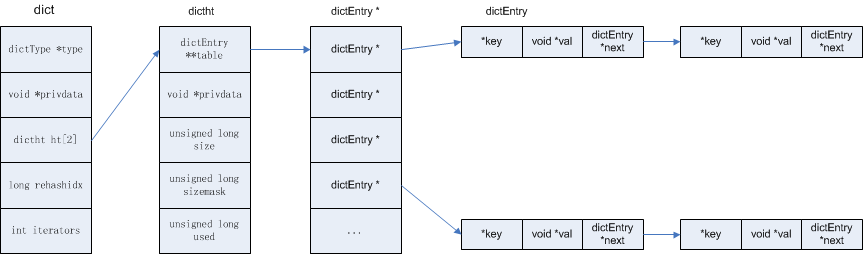
//单向链表结构 typedef struct dictEntry { void *key;//key值指针 union {// void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next;//单向链表下个元素指针 } dictEntry; //hash表类型 typedef struct dictType { unsigned int (*hashFunction)(const void *key);//哈希计算方法,返回整形变量 time33 //hash*33+hash+ord(1) void *(*keyDup)(void *privdata, const void *key);//对key进行拷贝 void *(*valDup)(void *privdata, const void *obj);//对value进行拷贝 int (*keyCompare)(void *privdata, const void *key1, const void *key2);//key比较器 void (*keyDestructor)(void *privdata, void *key);//销毁key,析构函数 void (*valDestructor)(void *privdata, void *obj);//销毁value,析构函数 } dictType; /* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */ //hash表结构 typedef struct dictht { dictEntry **table; //hash 表中如果出现hash 碰撞 就用单向连表保存数据结构 unsigned long size;//桶个数 unsigned long sizemask;//size-1,方便定位 unsigned long used;//实际保存的元素数 } dictht; //hash表主表 typedef struct dict { dictType *type;//hash表类型 void *privdata; dictht ht[2];//新旧两张hash 表 long rehashidx; /* rehashing not in progress if rehashidx == -1 */ int iterators; /* number of iterators currently running */ } dict; //迭代器 typedef struct dictIterator { dict *d; //当前hash 字典 long index;//当前索引 int table, safe;// dictEntry *entry, *nextEntry;//循环结构体 以及下一个dictEntry * 结构体 /* unsafe iterator fingerprint for misuse detection. */ long long fingerprint; } dictIterator;
#当发生hash碰撞时,dict_can_resize会变成真 当bgsave(快照)&© on write(aof)也会强制变成真 rehash
# use "activerehashing yes" if you don't have such hard requirements but
# want to free memory asap when possible.
# 每100毫秒,redis将用1毫秒的时间对Hash表进行重新Hash。
# 采用懒惰Hash方式:操作Hash越多,则重新Hash的可能越多,若根本就不操作Hash,则不会重新Hash
# 默认每秒10次重新hash主字典,释放可能释放的内存
# 重新hash会造成延迟,如果对延迟要求较高,则设为no,禁止重新hash。但可能会浪费很多内存
activerehashing yes
list
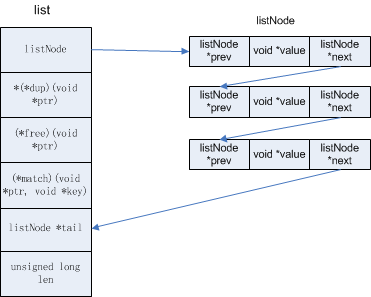
typedef struct listNode { struct listNode *prev; struct listNode *next; void *value; } listNode; typedef struct listIter { listNode *next; int direction; } listIter; typedef struct list { listNode *head; listNode *tail; void *(*dup)(void *ptr); void (*free)(void *ptr); int (*match)(void *ptr, void *key); unsigned long len; } list;
三、一些建议
- Master最好不要做任何持久化工作(AOF日志文件),特别是不要启用内存快照做持久化。(一旦主库挂了或者不可用,没啥毛用)
- 如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
- 为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
- 尽量避免在压力较大的主库上增加从库
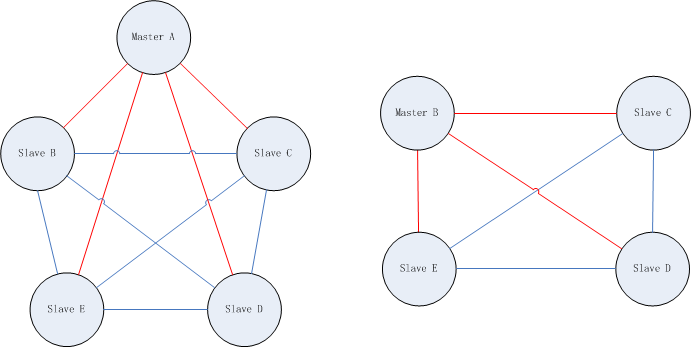
- 为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系为:Master<--Slave1<-- Slave2<--Slave3.......,这样的结构也方便解决单点故障问题,实现Slave对Master的替换,也即,如果Master 挂了,可以立马启用Slave1做Master,其他不变(现在看来也是然并卵)。
如果问题,欢迎指教

 浙公网安备 33010602011771号
浙公网安备 33010602011771号