7 NoSQL数据库
7 NoSQL数据库
❖7.1 NoSQL数据库概述
❖7.2 列存储数据库
❖7.3 键值对数据库
❖7.4 文档型数据库
❖7.5 图形数据库
啊啊啊啊
在Neo4J集群中,数据的写入是通过主服务器来完成的,数据的读取可以通过集群中的任意一个Neo4J实例来完成。
以下哪一项不是NoSQL的共同特征?
CAP
以下哪一项不是CAP的含义?
分布式
HBASE中表和区域的关系可以是什么?
1:N
7.1 NoSQL数据库概述
- 数据类型多样化:数字、视频、音频
- 数据结构化
- 数据存储方式多样化:(列式存储、键值存储、图存储、文档存储等)
关系数据库局限
高并发、数据多、扩展性不够、
分布式大数据处理
分布式文件系统(Distributed File System:DFS ):
是指文件系统的物理存储资源不在本地节点上,通过计算机网络与节点相连。
NOSQL的基础
NoSQL是Not Only SQL的缩写,即对关系型SQL数据库系统的补充。
• 相比传统数据库叫它分布式数据库管理系统更贴切, 数据存储被简化, 重点被放在了分布式数据管理上
• NoSQL并不单指一个产品或一种技术,它代表一族产品,以及一系列不同的、有时相互关联的、有关数据存储及处理的概念。
• 遵守BASE定理, 高性能,高可用性和可伸缩性。
• 高可扩展性、分布式计算、低成本、 架构的灵活性,半结构化数
据、 没有复杂的关系。
• 没有标准化、有限的查询功能(到目前为止)、最终一致不直观等
CAP理论
分布式事务
分布式事务ACID特征,原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
CAP理论
- Consistency一致性
- Availability可用性
- Partition Tolerance分区容忍性
一个分布式系统,最多只能同时较好的满足两个。
CAP是为了探索不同应用的一致性C与可用性A之间的平衡,选择什么样的方式: 放弃P?放弃A?放弃C?
----------------BASE
BASE
• BA: Basically Available --基本可用;系统能够基本运行,一直提供服务。
• S: Soft-state --软状态/柔性事务。"Soft state" 可以理解为"无连接"的
• E: Eventual Consistency --最终一致性 系统在某个时刻达到最终一致性。
• BASE定义为CAP中AP的衍生,在分布式环境下, BASE是数据的属性,BASE强调基本的可用性,按照功能划分数据库.
BASE—特点
• ACID是事物的特征, A(原子性)C(一致性)I(隔离性)D(持久性),ACID的特点是强一致性、隔离性、
采用悲观保守方法、难以变化;
• BASE的特点是弱一致性、可用性优先、采用乐观方法、适应变化并且简单快捷。
大数据下,很难满足ACID
2、NoSQL的技术
• 简单数据类型--键值
• 最终一致性,非结构化和不可预知的数据, 遵守CAP定理, 高性能,高可用性和可伸缩性
NoSQL的特点
• 优点表现在: 高可扩展性、分布式计算、低成本、 架构的灵活性,半结构化数据、 没有复杂的关系。
• 缺点: 没有标准化、有限的查询功能(到目前为止)、最终一致不直观等
NoSQL数据库的存储模型
- 列存储数据库,将同一列的数据存储在一起,可以存储结构化和半结构化数据
- 键值存储数据库,存储的数据是有键(key)和值(value)两部分
- 组成,通过key快速查询到其value,value的格式可以根据具体应用来确定
- 文档存储数据库,存储的内容是文档型的,可以用格式化文件(类似json、XML等)的格式存储 图存储数据库,数据以有向加权图方式进行存储
NoSQL数据库的特征
BASE: 相对于ACID特性,NoSQL数据库保证的是BASE特性(BASE是最终一致性和软事务
NoSQL数据库的应用场景
• 1、数据模型比较简单;
• 2、需要灵活性更强的IT系统;
• 3、对数据库性能要求较高;
• 4、不需要高度的数据一致性;
• 5、对于给定key,比较容易映射复杂值的环境。
• 许多云环境下的新型应用,如社交网络网、移动服务、协作编辑等
。云计算时代海量数据管理系统的设计目标为可扩展性、弹性、容
错性、自管理性和“强一致性”。
7.2 列存储数据库
数据库以行、列的二维表的形式表示数据,以一维字符串的方式存储课程数据库
• Course_id Course_name Course_type Course_hours Course_credit
• C001 数据库原理及应用 学科基础 64 4
• C002 操作系统基础 学科基础 64 4
• C003 面向对象程序设计 学科基础 48 3
行式数据库把数据一行一行存储。
存储的效果是字符串:C001,数据库原理及应用,学科基础,64,4,C002,操作系统基础,学科基础,64,4,C003,面向对象程序设计,学科基础,48,3
列式数据库把数据一列一列中存储
• 存储的效果是字符串:C001,C002,C003,数据库原理及应用,操作系统基础,面向对象程序设计,学科基础,学科基础,学科基础,64,64,48,4,4,4
特点
查询中的选择规则是通过列来定义的,列式存储数据库是自动索引化的;数据压缩比高,查询速度高
HBASE数据库
HBase是一个开源的非关系型分布式数据库(NoSQL),实现的编程语言为 Java
- 面向列(族)的存储
- 数据类型单一
- 有可扩展性。
HBASE数据模型
• HBase 以表的形式表达和存储数据,表由行和列组成,列划分为若干
个列族(row family)。
• HBase表的逻辑视图是基于行键(rowkey)、列族(column family)、列限定符(column qualifier)和时间版本(version)
HBase没有数据类型,任何列值都被转换成字符串进行存储;
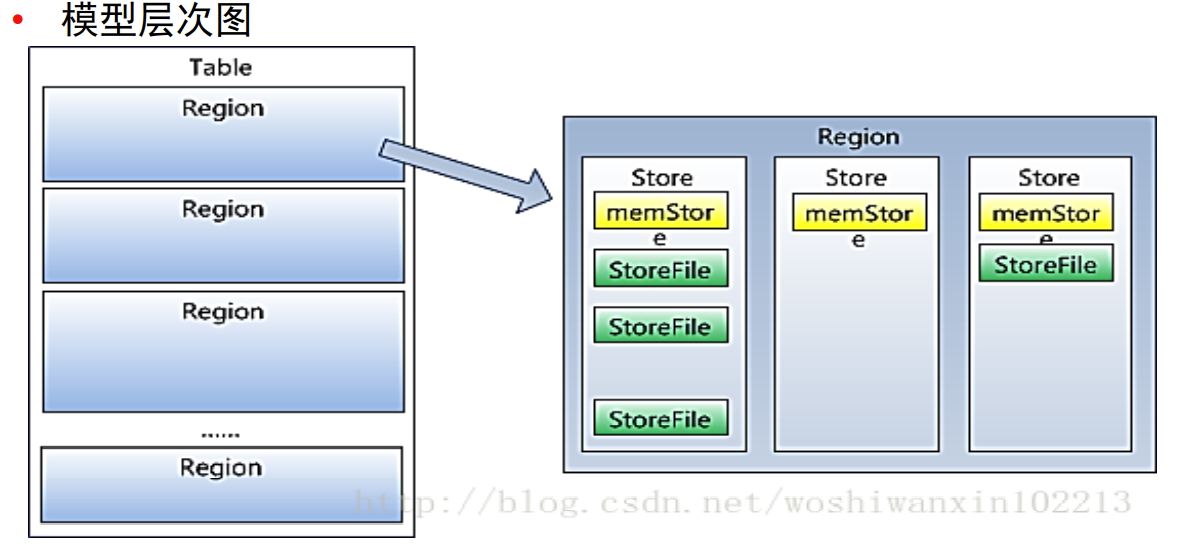
HBase数据存储的层次的关系
全是1对多关系
HBASE的应用场景
• 对象存储
• 时空数据
• 消息/订单
• Feeds流
• NewSQL
7.3 键值对数据库
键值存储可以同时在内存和硬盘上保存数据, 进行非常快的保存和读取处理, 并且保存在硬盘上的数据不会消失, 即使消失也可以恢复---Redis。
二、键值数据库的数据模型
• 1 数据结构:键值模型(Key-Value模型),每行记录由主键和值两个部分组成,值可以是各种类型的数据
• 2 数据操作: Get( key )、Set( key, value )、Delete( key )等
• 3 数据完整性: 针对单个键的操作才区别“一致性”
Redis数据库
• Redis ,开源的KV数据库。
• Redis的缺点是数据库容量受到物理内存的限制。
• Redis可保存多种数据结构,单个值的最大限制是1GB。
用到的类型:字符串String、List链表、Hash哈希表
特点
• Redis将键值存储在主存中,快速读写。
所有操作都是原子的
7.4 文档型数据库
文档是处理信息的基本单位。
文档可以很长、很复杂、可以无结构
将数据存储为一 个文档,数据结构由键值对组成,字段值可以包含其他文档,数组及 文档数组。
{ name:
"Wangxin",
• status: "student"
• groups:["course", "experiment"]
• }
每一行的存储格式为 field:value。
多个键及其关联的值有序地放置在一起就是文档。 文档是一组键值(key-value)对(即BSON)。
• 每个文档可以匹配所表示实体的数据域。 • 数据关系有两种:引用和嵌入文档。 • 写操作在文档级别是原子性的,没有单个写操作对超过一个文档或者 超过一个集合是原子性的。
MongDB的特点
模式自由; • 支持动态查询; 通过网络访问。
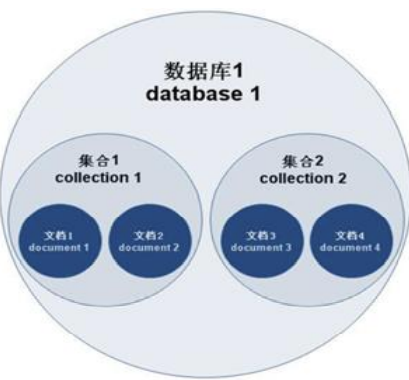
基本的概念是文档、集合、数据库。
文档是MongoDB中数据的基本单元
MongoDB文档不能有重复的键。
文档的键是字符串。文档中的 值不仅可以是字符串,也可以是其他数据类型(或者嵌入其 他文档)
层次关系:
文档—集合---数据库。
MongoDB的应用场景
适合:网站数据
不适合:高度事务性的系统,例如银行或会计系统。
7.5 图形数据库
像寻找朋友的朋友的社交图,这样的网状数据遍历查询----图数据库。
图数据库源起欧拉和图理论,面向/基于图的数据库
以“图”数据结构存储和查询数据,数据模型以节点和关系(边)体 现,也处理键值对
图特征:包含节点和边;节点上有属性(键值对);
边有名字和方向 ,开始\结束节点;边可有属性。
图是顶点和边的集合,或图是一些节 点和关联联系(relationship)的集合
基本概念
G=(V, E) , V=vertex(节点) , E=edge(边) 。节点和关系属 性;节点多个标签(类别);一个属性图是由顶点(Vertex),边( Edge),标签(Lable),关系类型和属性组成的有向图
顶点-节点(Node),边--关系(Relationship)点和关系--实体, 节点是独立存在的,节点有设置标签,相同标签节点属于一个分组或 集合; • 关系通过关系类型来分组,类型相同的关系属于同一个集合。关系是 有向的
图数据模型
图就是二元关系。利用一系列由线(称为边)或箭头(称为弧)连接 的点(称为节点)
• 弧(u,v)表示为u→v
路径是一列节点(v1,v2,…,vk)
图的实现--两种
图的应用包括最短路径、可达集、 各种搜索算法等。这些都给图 的应用提供理论基础。
邻接表、邻接矩阵
通过关系来连接各个结点。
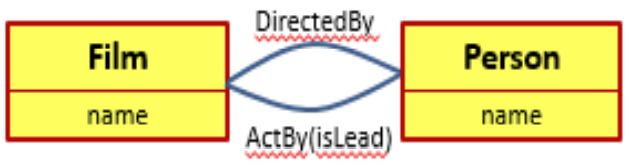
多个关系
如果两个实体之间拥有多种关系,就需要在它们之间创建多个关联 表。 • 在一个图形数据库中,只需要标明两者之间存在着不同的关系,例 如用DirectBy关系指向电影的导演,或用ActBy关系来指定参与电 影拍摄的各个演员
Neo4J图数据库
Neo4j查询语言名为CQL( Cypher Query Language), 不使用schema ,可以满足任何形式的需求,
速度快、规格大、可备份
每个实体都有ID(Identity)唯一标识,每个节点由标签(Lable)分组,每个关系都有一个唯一的类型,属性图模型的基本概念有:
Neo4j的两种使用方式:嵌入式模式,服务器 模式
例子
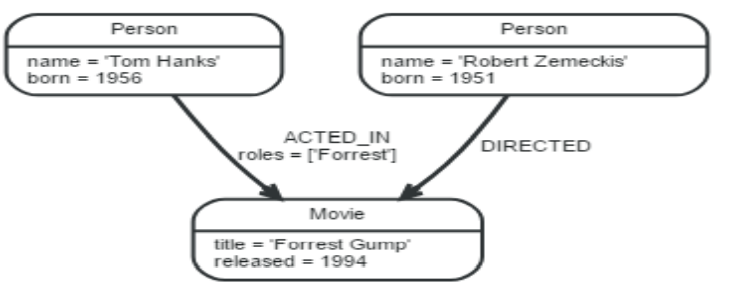
在下面的图形中,存在三个节点和两个关系共5个实体;
Person 和Movie是Lable,ACTED_ID和DIRECTED是关系类型,name, title,roles等是节点和关系的属性。有两个标签(对分组进行查询,能够缩小查询的节点范围,提高查询的性能。)Person和Movie,
• 实体包括节点和关系,节点有标签和属性,关系是有向的,链接 两个节点,具有属性和关系类型
• 3,属性(Property), 是一个键值对
每个节点都有name属性,用于命名节点。
• 在示例图形中,Person节点有两个属性name和born,Movie节点有两个
属性:title和released。
关系类型ACTED_IN有一个属性:roles(扮演的角色),该属性值是一个数组,而关系类型为DIRECTED的关系没
有属性。
• 遍历(Traversal)
Neo4j 的存储结构是什么?
(1) 存储 node 的文件, 存储节点数据、节点label及其序列Id包括存储节点数组、数组的下标即该节点的ID
(2)存储 relationship 的文件: 存储关系数据、关系组数据、关系类型、
(3)存储 label 的文件:
(4)存储 property 的文件:属性数据、类型、索引等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号