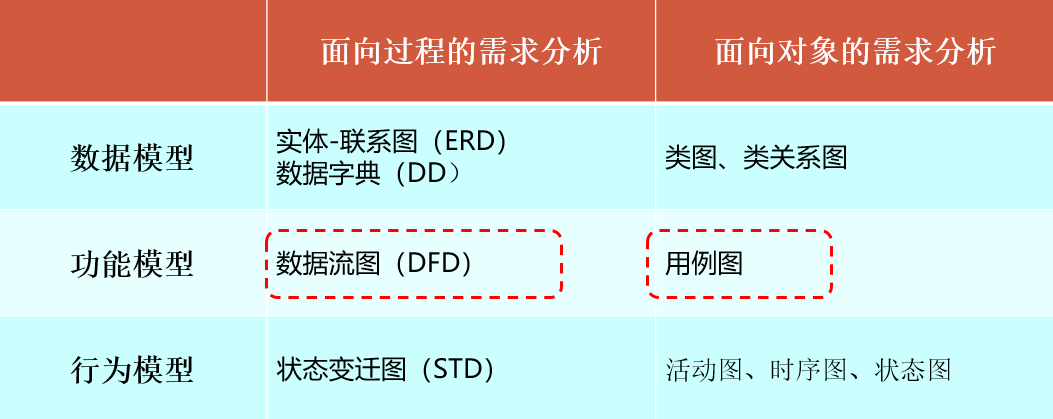
3.2面向过程的分析
需求分析模型
分类
面向过程分析模型
基本思想是用系统工程的思想和工程化的方法,根据用户至上的原则,自始自终按照结构化、模块化,自顶向下地对系统进行分析与设计。
面向对象分析模型
由5个层次(主题层、对象类层、结构层、属性层和服务层)和5个活动(标识对象类、标识结构、定义主题、定义属性和定义服务)组成。
分析模型描述工具
面向过程的分析建模工具总览
- 数据流图DFD——加工规约
- 实体——关系图ERD——数据对象描述(PSPEC)
- 状态变迁图STD——控制规约(CSPEC)
面向过程分析模型—结构化分析方法
- 面向数据流进行需求分析的方法
- 结构化分析方法适合于数据处理类型软件的需求分析
- 具体来说,结构化分析方法就是用抽象模型的概念,按照软件内部数据传递、变换的关系,自顶向下逐层分解,直到找到满足功能要求的所有可实现的软件为止
功能模型——数据流图DFD
主要图形元素:

数据流图图示例
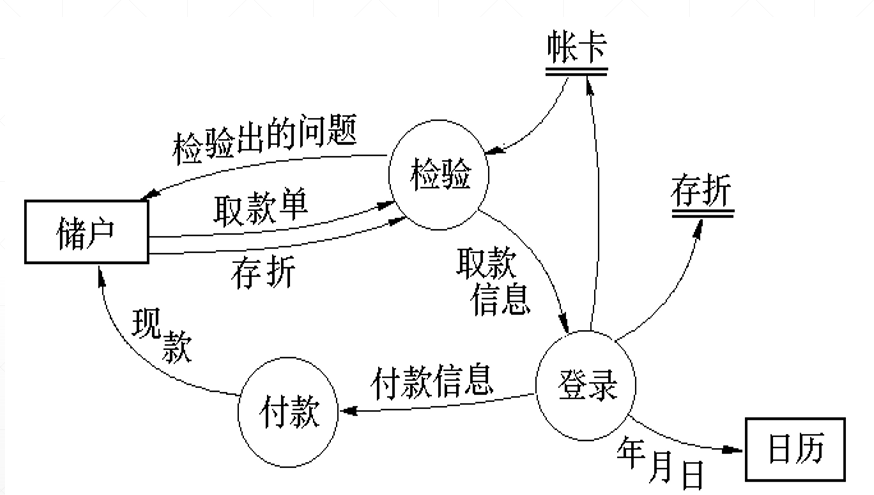
数据流图的层次结构
顶层:就是0层,是开发系统的总览。
向下一层,就是上一层的细化。
底层流图就是不能再分解的了。
(1) 加工
表示对数据进行的操作, 如“处理选课单” 、“产生发票”等
加工的编号,说明这个加工在层次分解中的位置 (分层DFD)
顶层是0层,由上向下是依次详细的解释。

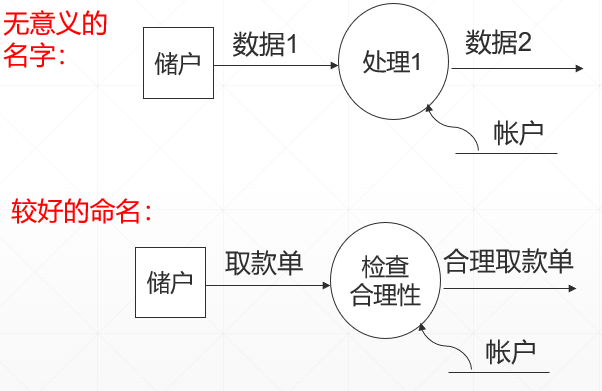
加工的命名
1)顶层的加工名就是整个系统项目的名字
2)尽量最好使用动宾词组,也可用主谓词组
3)不要使用空洞的动词
(2) 外部实体(数据源点/终点)
-
位于系统之外的信息提供者或使用者,称为外部实体。即存在于系统之外的人员或组织。如“学务科”等
-
说明数据输入的源点(数据源)或数据输出的终点(数据终点)
-
起到更好的理解作用,但不是系统中的事物
(3) 数据流
表示数据和数据流向, 由一组固定成分的数据组成 如“选课单”由“学号、姓名、课程编号、课程名”等成分组成
注意流向
数据流可从加工流向加工,也可在加工与数据存储或外部项之间流动;两个加工之间可有多股数据流
数据流的命名原则:
§1)用名词,不要使用意义空洞的名词
§2)尽量使用现实系统已有名字
数据流与数据加工之间的关系
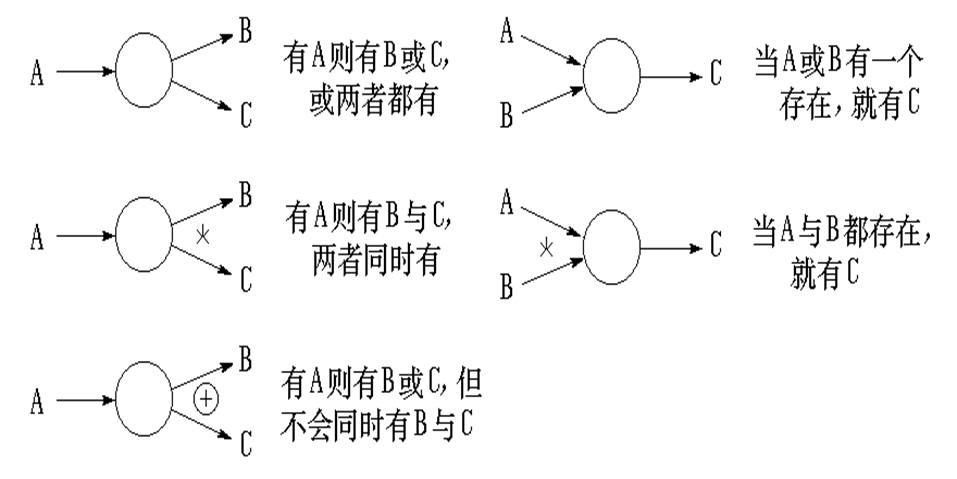
有这个小“火”标志的就好似一个“并”,不然就默认的是两个“或”。“⚪ + ”就是“不可能同时”
画数据流时需注意的问题
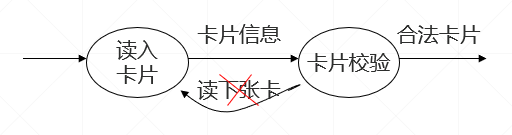
- 不要把控制流作为数据流
如:下图中读下张卡属于控制流,不应画出。
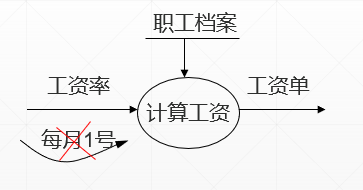
- 不要标出激发条件
(4) 数据存储
表示需要保存的数据流向, 如“ 学生档案”、“课程设置”等
数据存储与加工的方向一致、

分层数据流程图中,数据存储一般局限在某一层或某几层
命名方法与数据流相似
几种错误
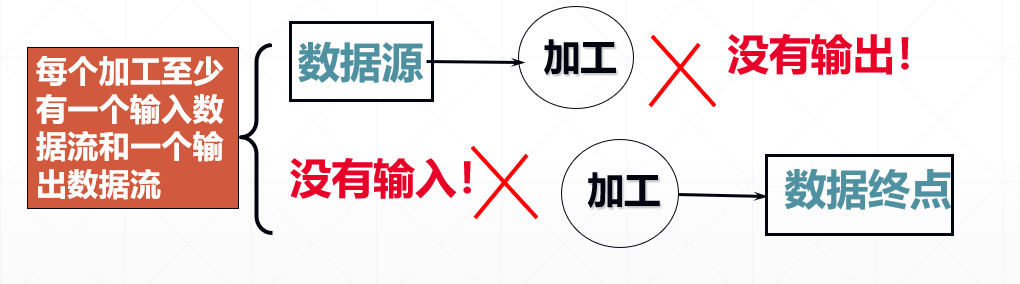
(1)
改正:每个加工至少有一个输入数据流和一个输出数据流
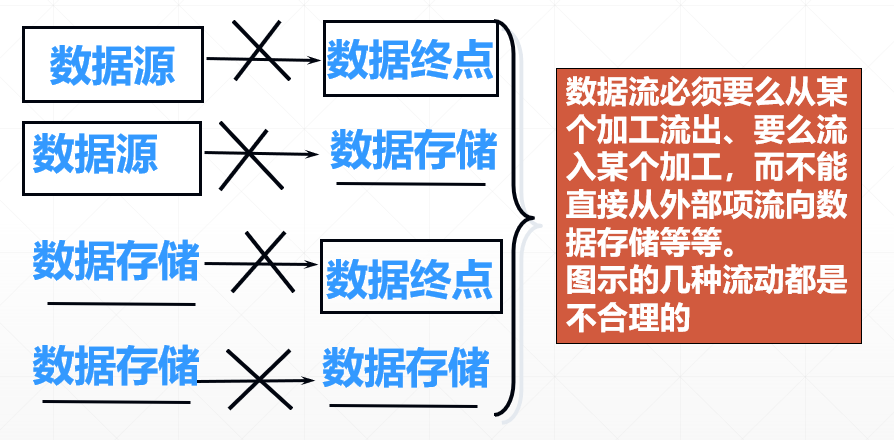
(2)
改正:数据流必须要么从某个加工流出、要么流入某个加工,而不能直接从外部项流向数据存储等等。
数据流图示例:仓库管理与订货系统
某仓库业务的工作过程如下:
-
企业职工填写领料单,经主管审查签名批准后,职工到仓库领取零件。
-
仓库保管员检查领料单是否符合审批手续,填写是否正确等,不正确的领料单退还职工,填写正确的领料单则办理领料手续,进行登记,修改库存量并给予零件。
-
当某种零件的库存量低于事先规定的临界值时,登记需要采购零件的订货信息,为采购部门提供一张订货单。要求用计算机辅助领料工作和编制订货单。
仓库业务系统数据流图
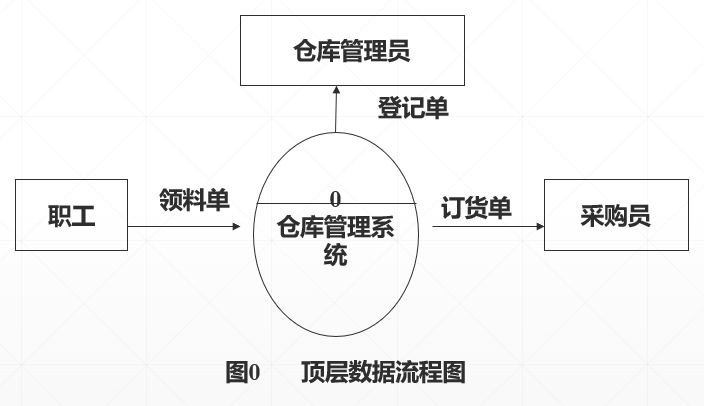
第一步:绘制数据流图顶层
-
首先确定系统的输入和输出,画出顶层数据流图。
-
经过分析,主要数据流输入的源点和输出终点是职工和仓库管理员、采购员。
-
之间的数据流:领料单、登记单、订货单
这个数据流图只是一个高层的系统逻辑模型,它反映了目标系统要实现的功能
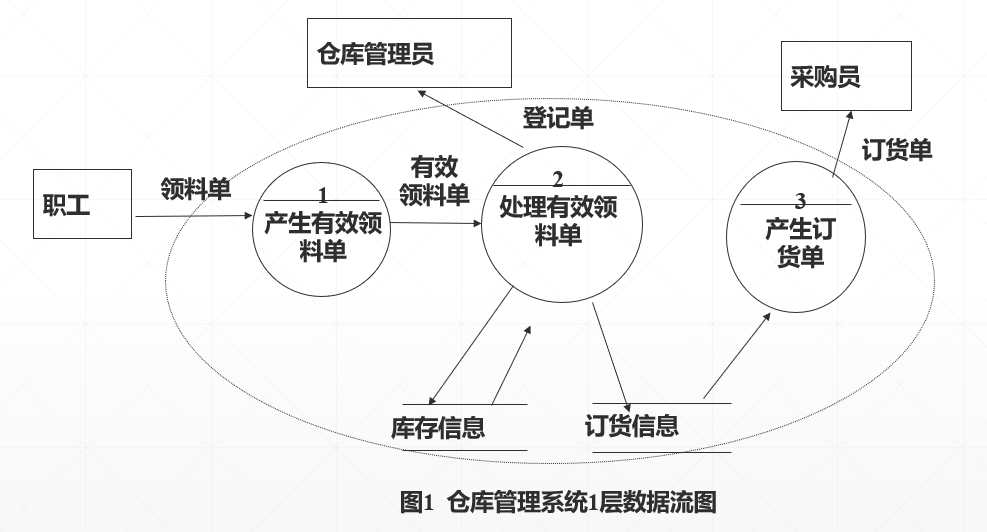
第二步:绘制数据流图1层
从输入端开始,根据仓库业务工作流程,画出数据流流经的各加工框,逐步画到输出端,得到1层数据流图。
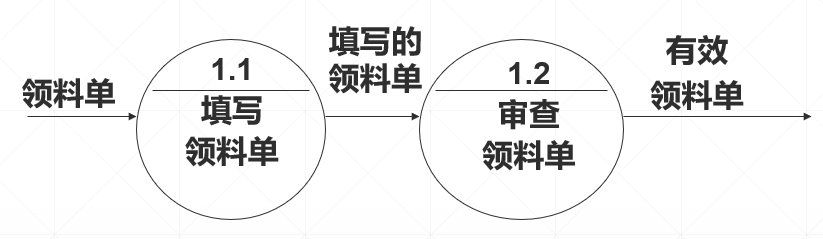
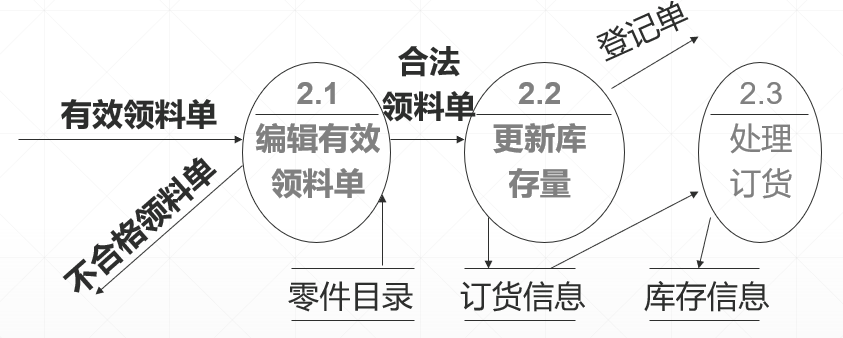
第三步:绘制数据流图2层——细化每一个加工框
(1)细化
 -->
-->
(2)细化
 -->
-->
第四步:合成
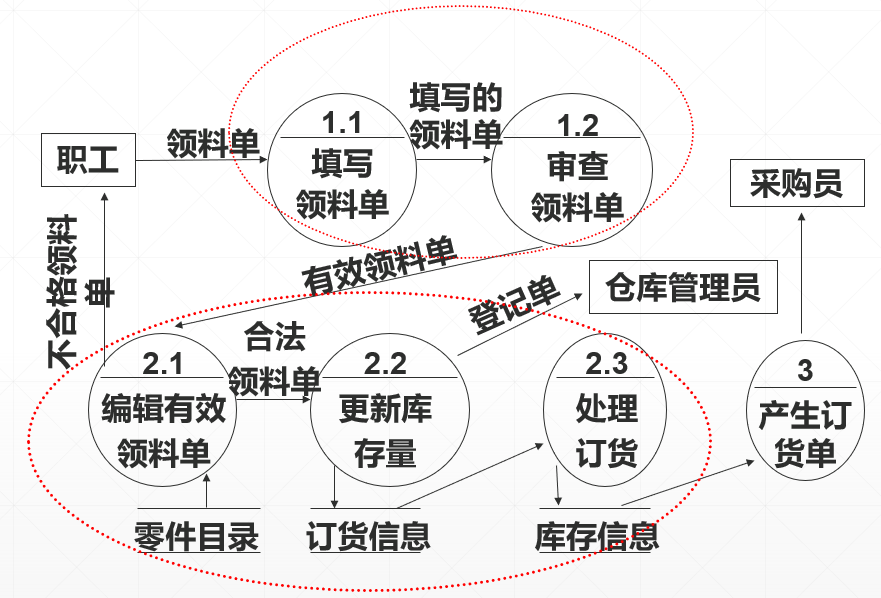
第五步:检查与调整数据流图
在分析过程中,由于每个人的经验和思路不尽相同,对数据流图的分解方案可以有多种形式,不是唯一的。
对每一张数据流图进行检查,如果太不均衡,就需要进行调整,尽量使分解后的各个软件子系统的复杂性得到均衡。
检查数据流图的原则
1)数据流图上所有图形符号只限于前述四种基本图形元素
2)数据流图的主图必须包括前述四种基本元素,缺一不可
3)数据流图的主图上的数据流必须封闭在外部实体之间
4)每个加工至少有一个输入数据流和一个输出数据流
5)在数据流图中,需按层给加工框编号。编号表明该加工所处层次及上下层的亲子关系
6)规定任何一个数据流子图必须与它上一层的一个加工对应,两者的输入数据流和输出数据流必须一致。此即父图与子图的平衡
7)图上每个元素都必须有名字
8)数据流图中不可夹带控制流!!!【最重要】
9)初画时可以忽略琐碎的细节,以集中精力于主要数据流
数据流图的改进:
检查正确性 —— 提高易理解性 —— 重新分解
(1) 检查DFD的正确性
-
数据守恒
-
数据存储的使用
-
父图和子图的平衡
数据守恒
数据不守恒的情况有两种:要么多了要么少了。
1)某个加工输出的数据并无相应的数据来源,可能是某些数据流被遗漏了。

2)一个加工的输入并没有用到,这不一定是错误。可与用户进一步讨论,是否属于多余的数据流。

数据存储的使用
判断:是否存在“只读不写”或“只写不读”的数据存储 (注意在所有的DFD中检查)
如下,对于YY,只有写入,没有流出,这是错误的
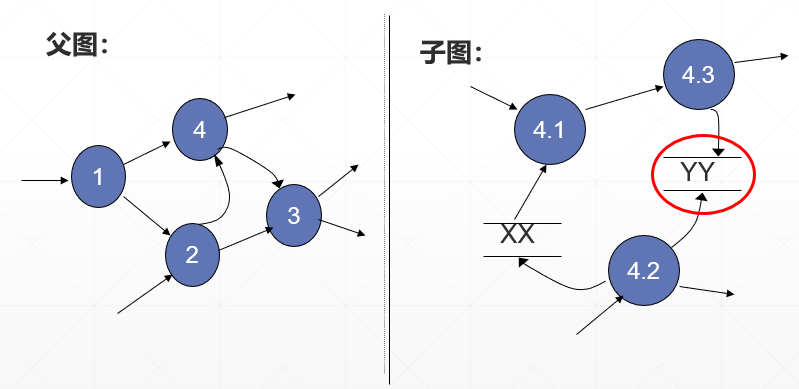
(2) 提高易理解性
-
简化加工之间的联系
-
注意分解的均匀
-
适当地命名
简化加工之间的联系
应尽量减少加工之间输入输出数据流的数目。因为加工之间的数据流越少,各个加工的功能就越相对独立。
例: 加工1和2之间的太多数据流。
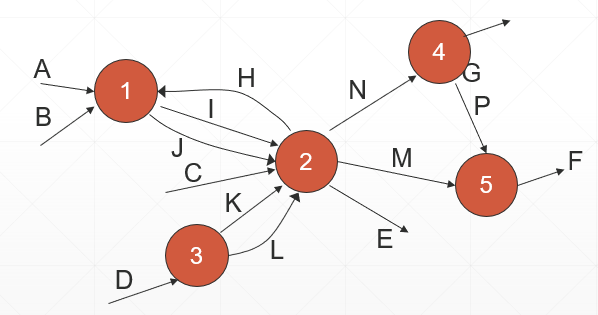
分解的均匀
一张图中,如果某些加工已是基本加工(细节),而另一些加工还可进一步分解成三、四层,则应考虑重新分解。
适当命名
如果难以为DFD图中的成分(数据流、加工等)命名,往往说明分解不当, 可考虑重新分解。
(3) 重新分解
在画第N层时意识到在第N-1层或第N-2层所犯的错误,此时就需要对第N-1层、第N-2层作重新分解。
重新分解的做法
1)把需要重新分解的某张图的所有子图连接成一张。
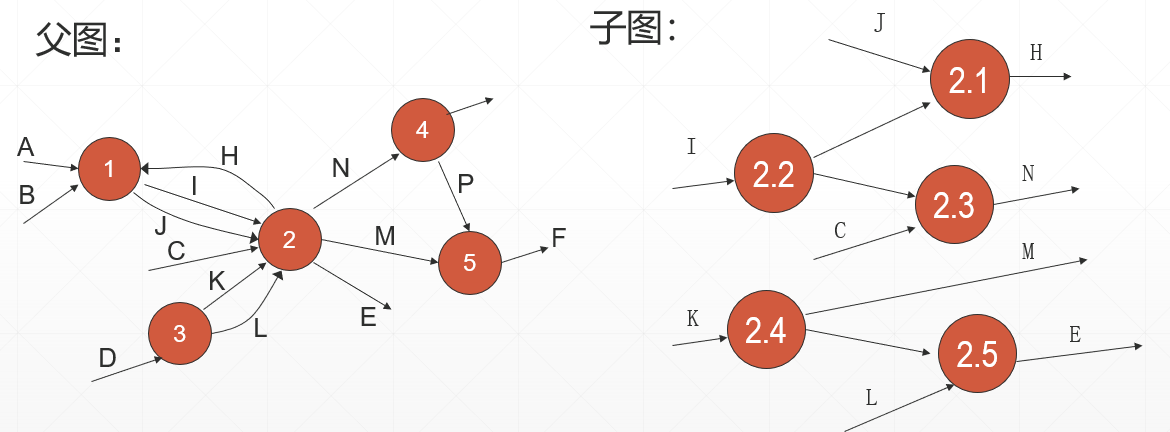
- 重新连接起来

2) 把图分成几部分,使各部分之间的联系最少。
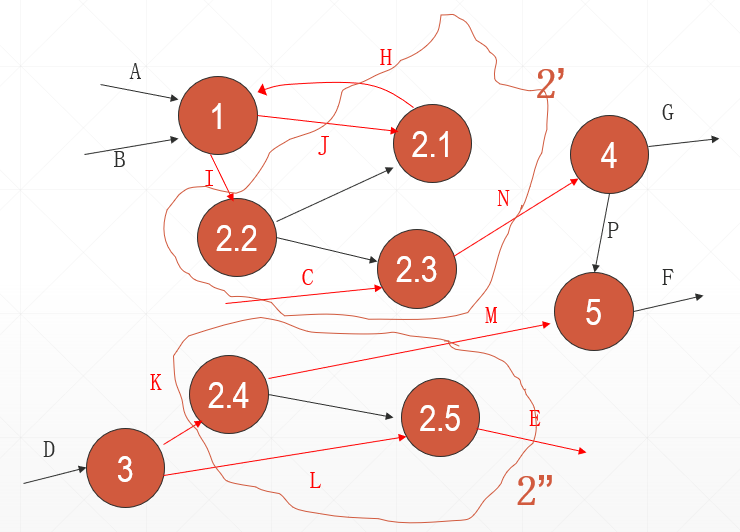
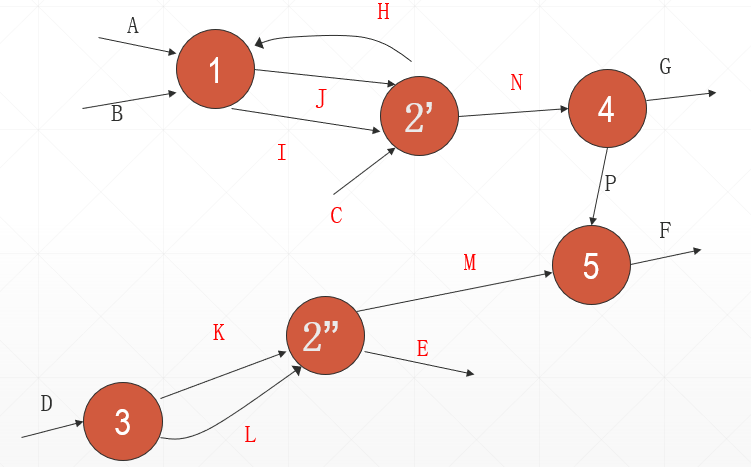
3)重新建立父图,即把第2)步所得的每一部分画成一个圆,而各部分之间的联系就是加工之间的界面。

4)重新建立各张子图,这只需把第2)步所得的图按各部分的边界剪开即可。
5) 为所有的加工重新命名和编号。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号