
四种I/O方式的对比
1. Buffered I/O
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
上下文切换:4次
CPU copy:2次
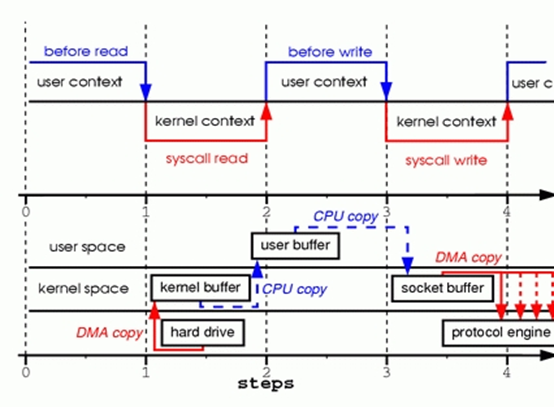
步骤1:read()系统调用使上下文从用户态切换到内核态。DMA engine从磁盘中读取文件内容,然后把数据保存在内核地址空间缓存。
步骤2:CPU从内核缓存复制数据到用户缓存,read()系统调用返回。Read()返回后,上下文从内核态切换到用户态。现在,数据储存在用户地址空间缓存。
步骤3:write()系统调用使上下文从用户态切换到内核态。CPU把用户缓存中的数据复制到内核缓存中。这个内核缓存通常与某个特定的socket关联。
步骤4:write()系统调用返回,使上下文从内核态切换到用户态。DMA engine把数据从内核缓存传递到protocal engine,这个过程是独立且异步的。独立且异步的意思是,write()返回不代表已经将所有数据写入到protocal engine,甚至不代表数据传输已经开始。write()返回仅仅表示Ethernet driver已经接受我们的数据传输,这项任务被置入一个队列。
这种IO被称为缓存IO(buffered io). 当应用程序访问某块数据的时候,操作系统内核会先检查这块数据是不是因为前一次对相同文件的访问而已经被存放在操作系统内核地址空间的缓冲区(页缓存)内,如果在内核缓冲区中找不到这块数据,Linux操作系统内核会先将这块数据从磁盘读出来放到操作系统内核的缓冲区里去。
2. Direct I/O
你可以对fd进行O_DIRECT的设置
fcntl(file, F_SETFD, O_DIRECT | O_SYNC | oldflags);
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
直接IO会把磁盘上的数据直接复制到用户地址空间,而不经过内核地址空间。直接IO适合自缓存应用(self-caching applications)。某些应用程序有自己的数据缓存机制,不需要使用操作系统内核缓存,这种应用程序称为自缓存应用。
内核缓存区对读写磁盘数据做了优化,包括按顺序预读取,在成簇磁盘块上执行IO等等。因此在普通的应用中使用直接IO会降低性能。
一般会在数据库系统使用直接IO。数据库系统的高速缓存和IO优化机制均自成一体,无需内核消耗CPU时间和内存去完成相同的任务。
直接IO中read和write的行为必须是同步的,但是O_DIRECT不保证同步,因此O_DIRECT必须与O_SYNC连用来保证同步行为。
请慎用。
3. 内存映射:使用mmap()代替read()
tmp_buf = mmap(file, len);
write(socket, tmp_buf, len);
上下文切换:4次
CPU copy:1次
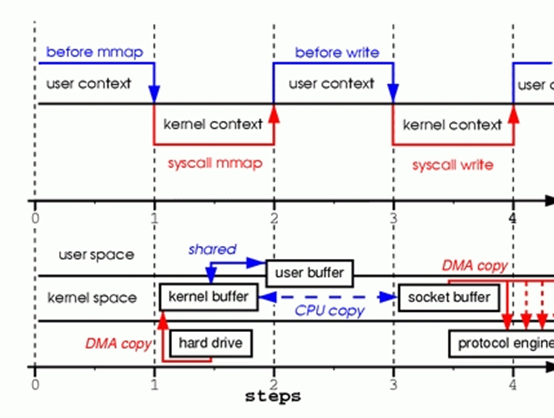
步骤1:mmap()系统调用使上下文从用户态切换到内核态。DMA engine从磁盘中读取文件内容,然后把数据保存在内核地址空间缓存。CPU将该内核缓存区与用户进程共享。
步骤2:write()系统调用使上下文从用户态切换到内核态。 CPU把数据从原来的内核缓存复制到另一片与socket关联的内核缓存区。
步骤3:write()系统调用返回,使上下文从内核态切换到用户态。DMA engine把数据从内核缓存传递到protocal engine。
使用mmap()代替read()可以减少一次CPU copy,但增加了share动作。当复制的数据量很大,一次CPU copy的花费大于share的花费时,使用mmap()代替read()是能优化性能的。但是,mmap()+write()有一个陷阱:You will fall into one of them when you memory map a file and then call write while another process truncates the same file.write()系统调用会被信号SIGBUS中断,这个信号的默认动作是kill进程然后dump core。作为一个server程序,我们通常不希望被KILL。我们有两种方法解决这个问题:
第一个方法是修改SIGBUS的信号处理程序,将其改为简单的return。这样,SIGBUS信号就不会kill进程,write()会返回被信号中断前已经成功写入的字符数,并设置errno。但是当该进程因其他问题收到SIGBUS信号时,却也简单的return了,这会掩盖运行时出现的巨大问题。因此,不推荐使用方法一。
第二个方法是使用文件租借锁 (windows系统中称为opportunistic lock)。让进程a获得租借锁,当进程b对正在传输的文件进行截断时,内核会给进程a发送信号,进程a会被中断,以防止该进程访问到无效地址并被SIGBUS中断。进程a的write()会返回中断前写入的字符数,并设置errno。以下是租借锁的示例代码
/* l_type can be F_RDLCK F_WRLCK */
if(fcntl(fd, F_SETLEASE, l_type)){
perror("kernel lease set type");
return -1;
}
你应该在mapping file前获得租借锁,在你完成写之后释放租借锁。
fcntl(fd, F_SETLEASE, F_UNLCK)
4. zero copy : sendfile()
从Linux2.1开始,引入了sendfile()
sendfile(socket, file, len);
上下文切换:2次
CPU copy:1次或0次
sendfile()与前面3节相比,只进行一次系统调用。因此,把用户态和内核态之间的上下文切换从4次减少到2次。
CPU copy次数取决于硬件是否支持gather operation
如果硬件不支持gather operation:
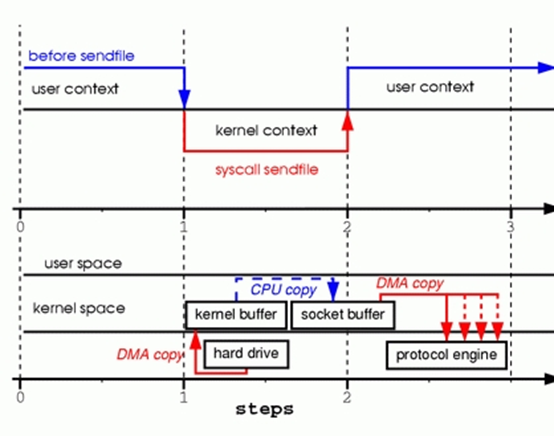
步骤1:sendfile()系统调用使上下文从用户态切换到内核态。DMA engine把文件内容复制到内核缓存区。然后CPU把该内核缓存区的数据复制到另一片与socket关联的内核缓存区。
步骤2:sendfile()系统调用返回,使上下文从内核态切换到用户态。DMA engine把数据从内核缓存传递到protocal engine。
如果调用sendfile()时,文件被截断。sendfile()会在在访问到无效地址前返回,以防止被SIGBUS信号中断。
如果硬件支持gather operation,且Linux2.4以上:
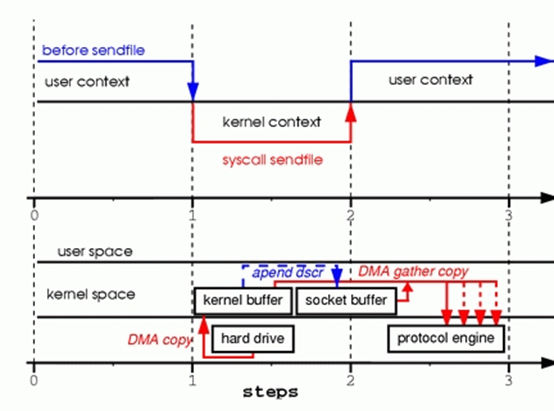
数据不会从kernel buffer复制到sokcet buffer.仅会把包含kernel buffer地址和长度的信息的描述符append到socket buffer.DMA engine会把数据从kernel buffer直接传到protocol engine.
Sendfile()的一个问题是缺乏标准的实现。
Linux的sendfile()实现提供了file to file和file to socket的接口,但是solaris和HP-UX仅提供了file to socket.
Linux的sendfile()不支持vectored tranfers.
solaris和HP-Ux的sendfile()有额外的参数
Linux的sendfile() notes:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
out_fd是待写的fd, in_fd是待读的fd。
在2.4-2.6.33,out_fd必须是一个socket。2.4以前和2.6.33后,out_fd可以是任何文件。
sendfile最多传输(2,147,479,552) bytes
当你使用sendfile()发送文件到TCP socket,但是需要在发送文件内容之前发送一些header,你可以对TCP socket设置TCP_CORK,以减少发送的数据包的数量。
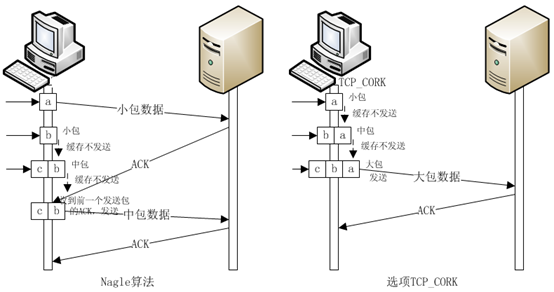
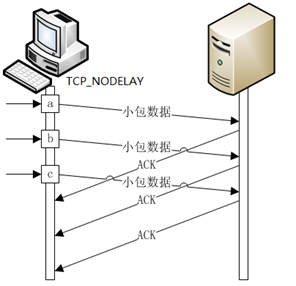
TCP发送数据包的算法
默认:采用nagle算法,当TCP buffer中的数据超过一个MSS时,发送数据,否则等待收到ACK后再发送数据。
对socket设置TCP_NODELAY:禁用nagle算法,TCP buffer接受到数据后马上发送
对socket设置TCP_CORK:当TCP buffer中的数据超过一个MSS时,发送数据,否则等待时间到达200 毫秒后再发送数据。当这个选项被取消,那么所有被阻塞的数据也将发送出去。
TCP_CORK的用法是在写数据前设置TCP_CORK,在分别写完header和body后,取消TCP_CORK。这可以避免header+body长度小于一个MSS导致发送延时的情况
sendfile()如果想要做到zero copy,那么被读文件的未写入到被写文件的部分不能被修改
目前sendfile()由splice()实现的,是对splice()的包装。
splice() moves data between two file descriptors without copying between kernel address space and user address space.
但是两个fd中必须有一个是pipe。Stack over flow的Damon不建议使用splice(),因为现在的实现不够完善
番外小记
O_NONBLOCK对网络IO有效,对磁盘IO并没有作用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号