机器学习--信息 信息熵 信息增益
信息:
信息这个概念的理解更应该把他认为是一用名称,就比如‘鸡‘(加引号意思是说这个是名称)是用来修饰鸡(没加引号是说存在的动物即鸡),‘狗’是用来修饰狗的,但是假如在鸡还未被命名为'鸡'的时候,鸡被命名为‘狗’,狗未被命名为‘狗’的时候,狗被命名为'鸡',那么现在我们看到狗就会称其为‘鸡’,见到鸡的话会称其为‘鸡’,同理,信息应该是对一个抽象事物的命名,无论用不用‘信息’来命名这种抽象事物,或者用其他名称来命名这种抽象事物,这种抽象事物是客观存在的。引用香农的话,信息是用来消除随机不确定性的东西。在机器学习信息的定义是,如果待分类的事物可能划分在多个分类之中,则这个类(Xi)的信息定义如下:(也可以看成在数学里信息就是这个公式)

I(x)用来表示随机变量的信息,p(xi)指是当xi发生时的概率,这里说一下随机变量的概念,随机变量时概率论中的概念,是从样本空间到实数集的一个映射,样本空间是指所有随机事件发生的结果的并集,比如当你抛硬币的时候,会发生两个结果,正面或反面,而随机事件在这里可以是,硬币是正面;硬币是反面;两个随机事件,而{正面,反面}这个集合便是样本空间,但是在数学中不会说用‘正面’、‘反面’这样的词语来作为数学运算的介质,而是用0表示反面,用1表示正面,而“正面->1”,"反面->0"这样的映射便为随机变量,即类似一个数学函数。
在上面这个例子中正面和反面,即(Xi)在机器学习中可以看做为分类,(Xi)的发生的概率就是(Xi)这个类别在样本集中出现的次数除以样本总量,而(Xi)这个类的信息就是上面的公式。
信息熵:
信息熵的大小指的是了解一件事情所需要付出的信息量是多少,这件事的不确定性越大,要搞清它所需要的信息量也就越大,也就是它的信息熵越大。在机器学习中,熵值的计算如下公式:
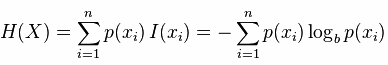
从公式上看,信息熵就是一件事每个类别的信息I(Xi)乘以它的发生的概率p(Xi)的和。
信息增益:
信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好,在概率中定义为:待分类的集合的熵和选定某个特征的条件熵之差(这里只的是经验熵或经验条件熵,由于真正的熵并不知道,是根据样本计算出来的),公式如下:
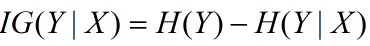
注意:这里不要理解偏差,因为上边说了熵是类别的,但是在这里又说是集合的熵,没区别,因为在计算熵的时候是根据各个类别对应的值求期望来得到熵。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号