字节跳动发布开源 Lip Sync AI 模型,视频换声对口型超轻松!
ByteDance新开源模型LatentSync,视频换声对口型超轻松!
阅读时长:9分钟
论文地址: https://arxiv.org/pdf/2412.09262
发布时间:2025年1月8日

字节跳动最近推出了LatentSync,这是一款全新的、最先进的开源视频唇形同步模型。它是一个基于音频条件潜在扩散模型的端到端唇形同步框架。
这听起来有点拗口,但简单来说,你可以上传一段某人说话的视频,以及一个你想要替换原始音频的音频文件。然后人工智能会叠加新的音频,并调整说话者的嘴唇动作,使其与上传的音频完美匹配。

最终生成的是一个极具说服力的深度伪造视频,尽管可能会让人感觉有点怪异。
说实话,这个领域的变化速度让我惊叹不已。就在一年前,人工智能视频中的唇形同步还不尽人意,嘴巴的动作常常看起来很诡异。而现在,有了LatentSync,我们正迈入一个轻松制作令人信服的深度伪造类视频的新时代。
LatentSync的工作原理
LatentSync框架使用Stable Diffusion直接对复杂的视听相关性进行建模。然而,基于扩散的唇形同步方法由于各帧扩散过程的变化,往往缺乏时间一致性。
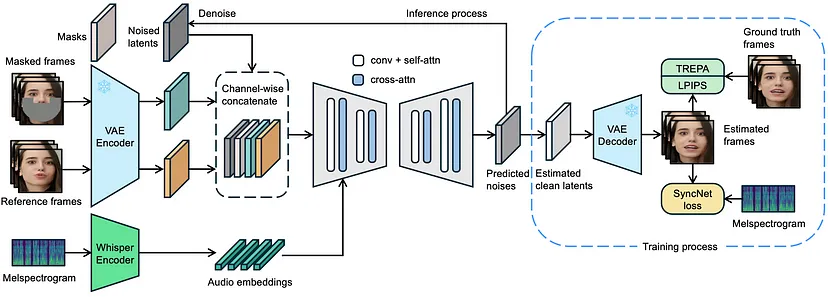
为了解决这个问题,研究人员引入了时间表示对齐(Temporal REPresentation Alignment,TREPA)技术,该技术在保持唇形同步准确性的同时,提高了时间一致性。TREPA利用大规模自监督视频模型的时间表示,将生成的帧与真实帧对齐。
LatentSync使用Whisper将梅尔频谱图转换为音频嵌入,并通过交叉注意力层将其添加到U-Net中。参考帧和掩码帧与噪声潜在变量相结合,作为U-Net的输入。
在训练过程中,研究人员一步从预测的噪声中估计出干净的潜在变量,并对其进行解码以获得干净的帧。在像素空间中应用TREPA、LPIPS和SyncNet损失函数。
本文由mdnice多平台发布
欢迎关注个人公众号 柏企阅文 个人网站 https://www.chenbaiqi.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号