
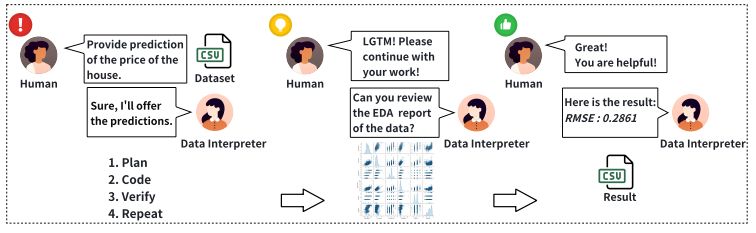
新型数据科学解决方案Data Interpreter助力实时数据调整与优化

数据科学中的实时数据调整与优化挑战
在数据科学领域,实时数据调整和优化是一个复杂而又充满挑战的任务。数据科学项目通常涉及到大量的数据处理步骤,这些步骤之间存在着复杂的依赖关系。随着数据的实时更新,这些依赖关系可能会发生变化,从而需要动态地调整数据处理流程。此外,数据科学中的问题往往要求精确的推理和彻底的数据验证,这对基于大型语言模型(LLM)的代理框架提出了额外的挑战。
论文标题:DATA INTERPRETER: AN LLM AGENT FOR DATA SCIENCE
项目地址:https://github.com/geekan/MetaGPT
公众号【AI论文解读】后台回复“论文解读” 获取论文PDF!
在这篇论文中,研究者们介绍了Data Interpreter,这是一个旨在解决数据科学问题的解决方案,它强调了三种关键技术来增强数据科学问题解决能力:1)动态规划与层次图结构,以实现实时数据适应性;2)动态集成工具以提高执行期间的代码熟练度,丰富所需的专业知识;3)在反馈中识别逻辑不一致性,并通过经验记录提高效率。Data Interpreter在各种数据科学和现实世界任务上进行了评估。与开源基线相比,它表现出了优越的性能,在机器学习任务中的表现从0.86提高到了0.95,在MATH数据集上提高了26%,在开放式任务中的表现提高了112%。这一解决方案将在项目地址发布。
Data Interpreter框架介绍
在数据科学领域,面对实时数据调整、优化复杂任务依赖关系以及精确推理识别逻辑错误的需求,即使是基于大型语言模型(LLM)的智能体也可能表现不佳。为了解决这些挑战,我们引入了Data Interpreter框架,它采用了三种关键技术来增强数据科学问题解决能力:动态规划与层级图结构、工具集成与动态生成以及逻辑一致性识别与经验增强。
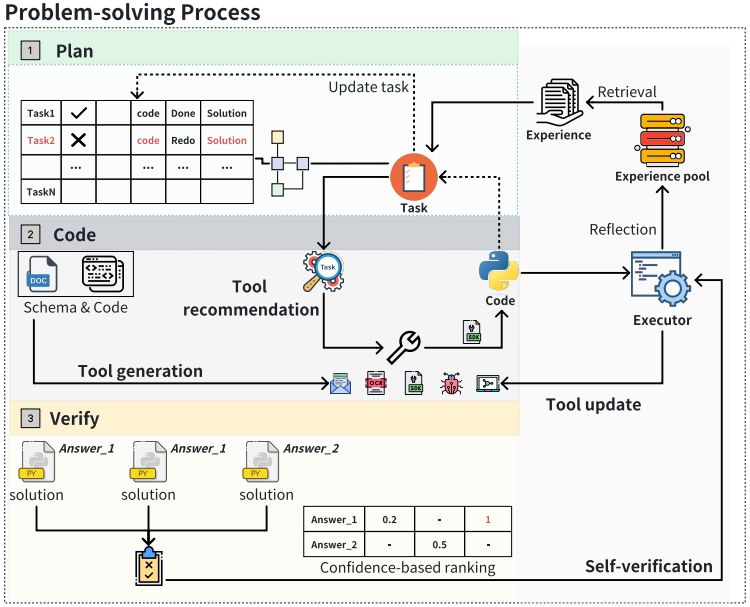
动态规划与层级图结构
Data Interpreter框架采用层级图结构来理解数据科学的内在复杂性,并通过动态规划方法提供对任务变化的适应性。这种结构特别有效于监控数据变化和管理数据科学问题中固有的复杂变量依赖关系。
工具集成与动态生成
为了提高编码效率,Data Interpreter集成了各种人工编写的代码片段,创建了针对特定任务的定制工具。这一过程涉及到与自生成代码的自动组合,使用任务级执行来独立构建和扩展工具库,简化工具使用,并根据需要进行代码重构。
逻辑一致性识别与经验增强
基于执行结果和测试驱动验证获得的置信度评分,Data Interpreter能够检测代码解决方案与测试代码执行之间的不一致性,并通过比较多次尝试来减少逻辑错误。在执行和推理过程中,主要包括元数据和运行轨迹的任务级经验被记录下来,这些经验既包括成功也包括失败的案例。
动态规划与层级图结构详解
数据科学问题的层级图表示
在数据科学项目中,由于涉及到广泛的细节和长期的流程,直接规划所有详细任务和编码变得复杂。因此,我们借鉴了在自动化机器学习任务中应用层级规划的思想,通过层级结构组织数据科学流程,将复杂的数据科学问题分解为可管理的任务,并进一步将每个任务细化为通过代码执行的具体动作。这种层级图结构为我们的解释器提供了结构化的问题解决方法,并能够灵活捕捉数据科学流程中的顺序和并行任务关系。
动态计划管理策略
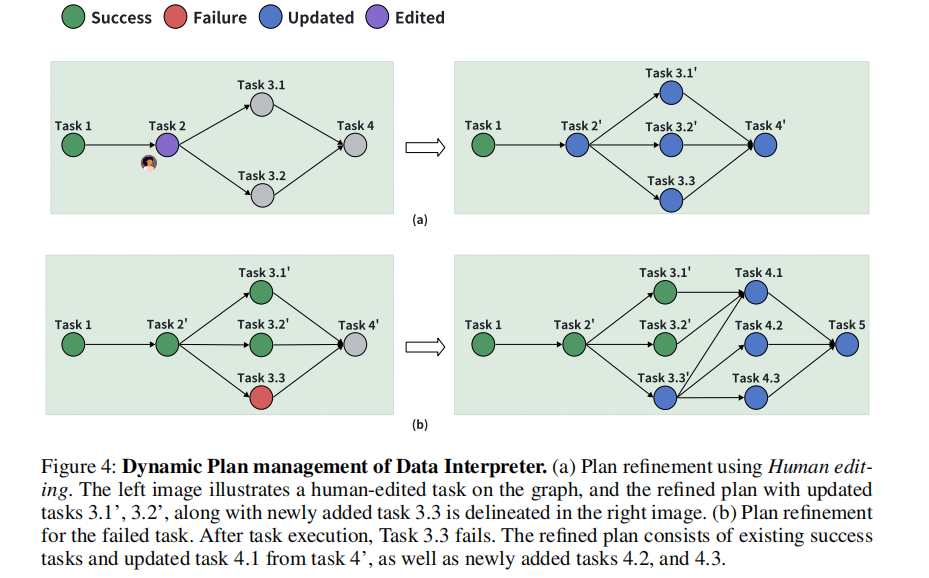
Data Interpreter框架利用层级图结构自动执行任务。与之前的方法不同,我们的框架在数据密集型场景中,考虑到任务执行过程中中间数据可能会因工具操作或工作流中的新信息而动态变化,这可能会导致数据与预定义计划不匹配而出现运行时错误。为了解决这个问题,我们引入了动态计划管理策略。
我们的解释器在每个任务执行后动态更新任务图中每个节点的对应代码、执行结果和状态。任务通过成功执行相应的代码被视为完成,并标记为“成功”,然后根据计划进行下一个任务。相反,如果任务失败,则标记为“失败”。
我们设计了两种策略:自我调试和人工编辑,旨在提高解释器的自主完成和正确性。在任务失败时,启用自我调试功能,利用LLM根据运行时错误调试代码,直到预定义的尝试次数。如果任务仍未解决,则标记为“失败”。由于数据科学问题的高逻辑要求,我们引入了人工编辑方法以确保代码的精确性。当启用人工编辑时,解释器将保留任务,直到人工修改后重新运行。
对于失败或手动编辑的任务,我们的解释器将根据当前的情景记忆和执行上下文重新生成计划。具体来说,重新生成的任务图按拓扑顺序排序,然后使用前缀匹配算法与原始任务图进行比较,以识别指令中的差异。通过这种比较,可以识别分叉点。这个过程的最终输出包括所有在分叉点之前未更改的任务和在分叉点之后添加或修改的新任务。
在执行过程中,我们的解释器监控动态任务图,及时移除失败的任务,生成精细化的任务,并更新图表。这避免了一次性生成细粒度规划任务的低效,并提高了需要多步执行的计划的成功率,使其更适合数据科学问题中数据流不断变化的场景。
工具集成与动态生成策略
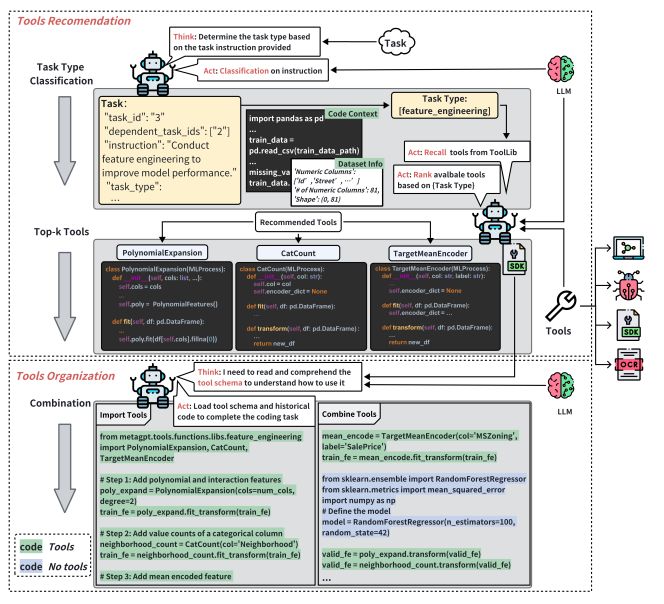
1. 工具推荐与组织
在数据科学问题解决的过程中,工具的选择和组织是至关重要的。我们的解决方案,Data Interpreter,通过对任务描述和类型的分类,有效地缩小了潜在工具的选择范围,从而提高了后续任务的选择效率。我们的解释器通过评估候选工具与任务的兼容性,来识别最适合任务的前k个工具。
此外,我们还引入了工具模式,帮助LLMs理解这些工具的功能和使用场景,并在执行阶段嵌入这些模式。这种模式引导的理解使得工具的选择和应用更加准确。在执行过程中,算法还会动态调整工具参数,以适应代码上下文和任务需求,从而提高工具的适应性。
在工具组织方面,我们的方法使用LLMs无缝集成工具到代码中,根据工具功能的深入分析来优化位置。这对于复杂任务如特征工程来说尤其有用,有助于实现工具集成的高效和适应性。我们通过考虑当前任务的上下文和可用工具来完善这一过程。LLM被指导编写不仅调用所需工具函数的代码,还与代码的其他方面无缝集成。这允许动态地协调各种工具,以满足编码过程的特定需求。
2. 持续工具演化
为了减少调试的频率并提高执行效率,我们的模型在任务执行过程中从经验中学习。每完成一个任务后,它通过提炼工具的核心功能,去除任何特定于样本的逻辑,从而创建通用的、通用的工具函数,并将其添加到库中以供将来使用。
此外,Data Interpreter通过进行严格的单元测试,并利用LLMs的自我调试能力,自动确保这些工具的可靠性。因此,Data Interpreter促进了将特定于样本的代码片段迅速转换为可重用的工具函数,从而不断提高其工具库和编码专业知识。
逻辑一致性识别与经验增强
1. 自动化基于信心的验证
我们设计的任务图、动态计划管理和工具使用可以提高任务规划和工具掌握能力。然而,仅依靠错误检测或捕获异常作为反馈是不足以完成任务的。对于复杂的推理问题,即使代码运行没有错误,它仍可能包含逻辑缺陷。因此,我们引入了自动化基于信心的验证(ACV),它在环境和解释器之间引入了一个解释层。这种方法允许LLMs评估代码执行结果,并确定代码解决方案是否在数学上严谨或逻辑上正确。
具体来说,一旦任务的代码解决方案开始执行,我们的解释器就需要生成验证代码,以确保输出结果符合任务要求。验证代码旨在根据任务描述模拟逻辑过程,并验证代码生成的结果的正确性。
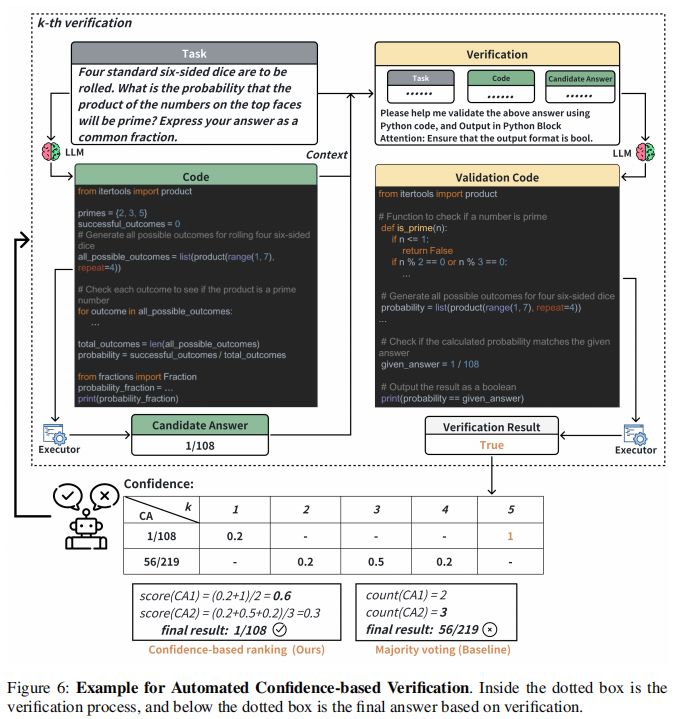
2. 经验驱动的推理
随着自动化基于信心的验证使任务解决过程更加透明和可靠,验证中生成的数据可以作为其他任务的经验重用。因此,我们通过反思性分析改进了解释器的适应性,允许任务被审查、更新和确认。这个过程被称为经验驱动的推理。
具体来说,我们的解释器集成了一个外部存储库,称为“经验池”,用于存档每个任务的关键元素,包括任务描述、最终版本代码和最终答案。在池中,所有存档的数据都被重新组织为基于反思机制的可重用经验。这些经验,包括失败和成功的尝试,可以为任务提供全面的上下文。
这个池作为一个宝贵的资源,使得过去的经验可以被检索出来,以通知和优化新任务的执行。如果发现经验是新任务的最近邻之一,就可以重用这些经验,这可以提高其推理的准确性和效率。这种方法反映了人类认知的基本原则,即个体利用过去的经验来增强决策和问题解决能力。
实验设置与评估指标
1. 数据集介绍:MATH、ML-Benchmark 和开放式任务基准
在本研究中,我们使用了三个数据集来评估Data Interpreter的性能。首先,MATH数据集包含12,500个数学问题,其中5,000个被指定为测试集,涵盖了从预代数到微积分等不同的数学科目和难度级别。其次,ML-Benchmark是为了评估机器学习领域的能力而特别开发的基准数据集和相应的评估方法,它包含了八个代表性的机器学习任务,这些任务被分为三个难度级别,从简单(级别1)到最复杂(级别3)。最后,开放式任务基准包含了20个任务,每个任务都要求框架理解用户需求、分解复杂任务并执行代码。
2. 评估指标:准确率、完成率、综合得分
在评估指标方面,MATH基准数据集使用准确率作为评估指标。对于ML-Benchmark,我们使用了三个评估指标:完成率(CR)、标准化性能得分(NPS)和综合得分(CS)。完成率(CR)是根据任务要求描述中的步骤数来衡量的,每个步骤的完成状态由一个得分st表示,最高得分smax为2,最低得分smin为0。标准化性能得分(NPS)是根据每个任务的评估指标来计算的,这些指标可能在不同任务之间有所不同,包括准确性、F1、AUC和RMSLE等。综合得分(CS)是CR和NPS的加权和,用于同时评估任务要求的完成率和生成的机器学习模型的性能。对于开放式任务,由于缺乏统一的性能标准,我们默认将NPS设置为0,并直接将CS等同于CR。


主要结果与分析
1. 数学问题解决的性能
在数学问题解决方面,Data Interpreter在所有测试类别中均取得了最佳结果,其中在数论(N.Theory)类别中达到了0.81的准确率,比AutoGen提高了0.15。在最具挑战性的类别,即微积分(Precalc),Data Interpreter获得了0.28的准确率,比AutoGen提高了0.16。值得注意的是,自动置信度验证(ACV)的引入在所有任务类别中都带来了显著的改进,与没有ACV的版本相比平均提高了17.29%。平均而言,ACV策略比AutoGen提高了26%的相对改进。
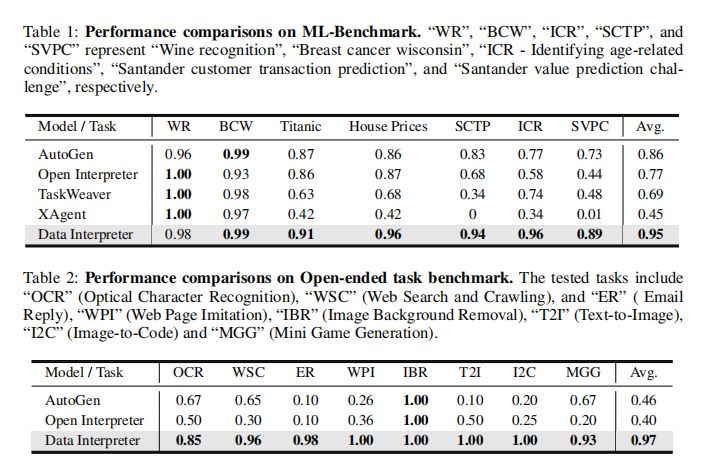
2. 机器学习任务的性能
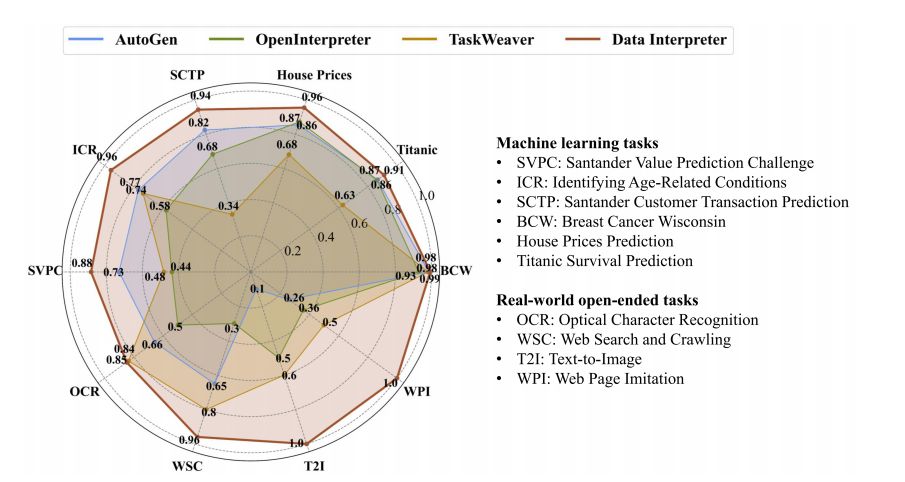
在机器学习任务方面,Data Interpreter在七个任务中取得了0.95的综合得分,而AutoGen的平均得分为0.86,标志着显著的10.3%提升。它是唯一在Titanic、House Prices、SCTP和ICR等任务上综合得分超过0.9的框架。Data Interpreter在相应的数据集上超越了其他框架,并在ICR和SVPC上分别比AutoGen提高了24.7%和21.2%。Data Interpreter完成了每个数据集上的所有必要流程,并始终保持了卓越的性能。
3. 开放式任务的性能
在开放式任务方面,Data Interpreter实现了0.97的完成率,与AutoGen相比有112%的显著提升。在IBR任务中,所有三个框架都实现了1.0的完成得分。在OCR相关任务中,Data Interpreter的平均完成率为0.85,比AutoGen和OpenInterpreter分别高出26.8%和70.0%。在需要多步骤和使用多模态工具/接口的任务中,如WPI、I2C和T2I,Data Interpreter是唯一能够执行所有步骤的方法。AutoGen和OpenInterpreter未能登录并获取ER任务的状态,导致完成率较低。Data Interpreter能够动态调整任务并实现0.98的完成率得分。

模块实验
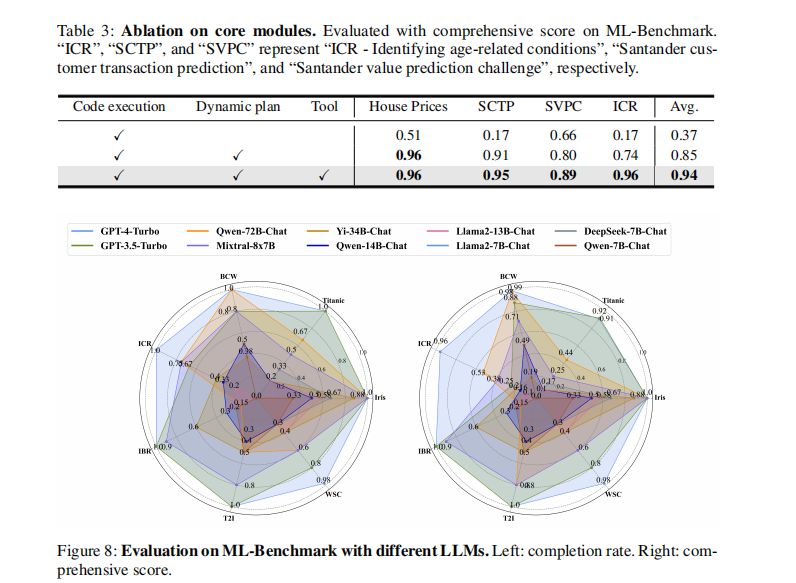
核心模块的影响
在ML-Benchmark上进行的核心模块剥离实验显示,动态规划的引入显著提升了性能,平均综合得分提高了0.48。这表明动态规划在实时跟踪数据变化方面的重要性,尤其是在完成率方面。此外,工具的使用和生成功能带来了额外的9.84%的性能提升,将综合得分提升至0.94。这些结果强调了动态规划和工具使用在提高数据科学任务效率方面的重要性。
不同LLM后端的性能比较
在机器学习任务中,更大的LLM后端如Qwen-72B-Chat和Mixtral-8x7B表现与GPT-3.5-Turbo相当,而较小的LLM后端则表现下降。例如,Yi-34B-Chat和Llama2-13B-Chat在执行需要高级编码能力的任务时遇到了限制。在开放式任务中,Mixtral-8x7B在三个任务中实现了高完成率,但在WSC任务中由于无法准确输出完整结果到CSV文件而遇到挑战。这些结果表明,LLM的大小对于执行复杂任务的能力有显著影响。
经验池大小对任务效率的影响
经验池大小的变化对任务效率有显著影响。经验池从0增加到200时,每个任务所需的调试尝试次数从1.48减少到0.32,成本从$0.80减少到$0.24。即使在经验池大小为80时,调试尝试次数也显著减少,尤其是在ER、Titanic和House Prices任务中分别减少了1.25、1和1次。这些结果突显了即使在经验池较小的情况下,通过经验学习也能显著提高效率。
结论与未来展望
Data Interpreter的优势与贡献
Data Interpreter在机器学习任务、数学问题解决和实际任务性能方面均优于各种开源框架,标志着LLM代理在数据科学领域能力的重大进步。通过动态规划、工具集成和演化以及自动化基于信心的验证,Data Interpreter精心设计以提高在管理复杂数据科学任务中的可靠性、自动化和推理能力。通过广泛的评估,Data Interpreter在机器学习任务、数学问题和现实世界任务表现方面均优于各种开源框架,这标志着LLM代理在数据科学领域能力的重大进步。
数据科学任务中LLM代理的未来发展
LLM代理在处理静态和简单任务方面已经证明了其有效性,但在面对复杂的多步骤挑战时,尤其是在机器学习任务中,它们的能力受到限制。未来的发展将需要更好地理解和利用编码工具,超越当前以API为中心的能力。此外,通过代码执行反馈,LLM代理可以增强其解决问题的能力。然而,它们在解释错误反馈以评估任务完成情况时的能力有限。在数据科学场景中,LLM代理必须区分逻辑错误和无错误反馈,从而验证其代码解决方案的可靠性,并提供更准确的结果。未来的研究将需要解决这些挑战,以进一步提高LLM代理在数据科学任务中的性能和可靠性。
关注公众号 AI论文解读

获取最新AI论文解读


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人