
揭秘大语言模型中线性表征的起源,卡内基梅隆大学新研究揭示AI学习的深层逻辑
揭秘大语言模型中线性表征的起源,卡内基梅隆大学新研究揭示AI学习的深层逻辑
引言:揭秘大型语言模型中的线性表征之谜
在人工智能领域,大型语言模型(LLMs)的内部工作机制一直是研究者们探索的重点。这些模型如何处理和理解语言,尤其是如何在其庞大的神经网络结构中编码和表达高层次的语义概念,是一个长久以来困扰科学家的谜题。近期的研究发现,这些高层次的语义概念往往以一种线性的方式在模型的表示空间中被编码。这一发现不仅令人惊讶,而且对于我们理解和解释LLMs的工作原理具有重要意义。然而,这种线性表征的出现是否具有普遍性,它背后的原理是什么,以及它是否真的能够反映出模型对语言的深层理解,都是亟待解答的问题。
本文将深入探讨大型语言模型中线性表征的起源,通过对一系列实验和理论分析的综合考察,揭示这一现象背后的数学和算法基础。我们将看到,线性表征的形成与模型的学习目标、梯度下降的隐式偏差以及数据的潜在结构密切相关。通过对这些因素的深入理解,我们不仅能够更好地解释LLMs的内部机制,还可能为设计更高效、更可解释的语言模型提供新的思路。
论文概览:标题、作者、链接和研究机构
标题: On the Origins of Linear Representations in Large Language Models
作者: Yibo Jiang, Goutham Rajendran, Pradeep Ravikumar, Bryon Aragam, and Victor Veitch
链接: https://arxiv.org/pdf/2403.03867.pdf
研究机构:
- Department of Computer Science, University of Chicago
- Machine Learning Department, Carnegie Mellon University
- Booth School of Business, University of Chicago
- Department of Statistics, University of Chicago
- Data Science Institute, University of Chicago
在这篇论文中,作者们提出了一个简单的潜变量模型来抽象和形式化下一个词预测的概念动态,并使用这个模型来证明这些潜在概念确实在学习的表示空间中线性表征。研究结果表明,线性表征结构不特定于模型架构的选择,而是模型学习不同上下文和相应输出的条件概率的副产品。此外,简单的潜变量模型产生的表示行为,如线性和正交性,与在LLMs中观察到的类似,这表明它可能是可解释性研究中进一步理论研究的有用工具。通过对模拟数据和LLaMA-2大型语言模型的实验验证,论文进一步证实了这一理论模型的预测。
线性表征的起源:从潜在变量模型到概念动态
在大型语言模型的表示空间中,高级语义概念通常被编码为线性结构。这一发现引发了对于如何在模型中编码对人类有意义的高级语义概念的探索。线性表征的起源是一个关键问题,本文通过引入一个简单的潜在变量模型来抽象和形式化下一个词预测的概念动态。通过这种形式化,我们证明了这些潜在概念确实在学习到的表示空间中线性地呈现。这一结果包括两个部分:首先,类似于早期关于词嵌入的发现,我们展示了对数几率匹配导致线性结构的形成;其次,我们展示了即使在对数几率匹配条件失败时,梯度下降的隐式偏差也会促使线性结构的出现。这些结果为线性表征假设提供了强有力的支持。
模型框架:潜在条件模型的构建与可视化
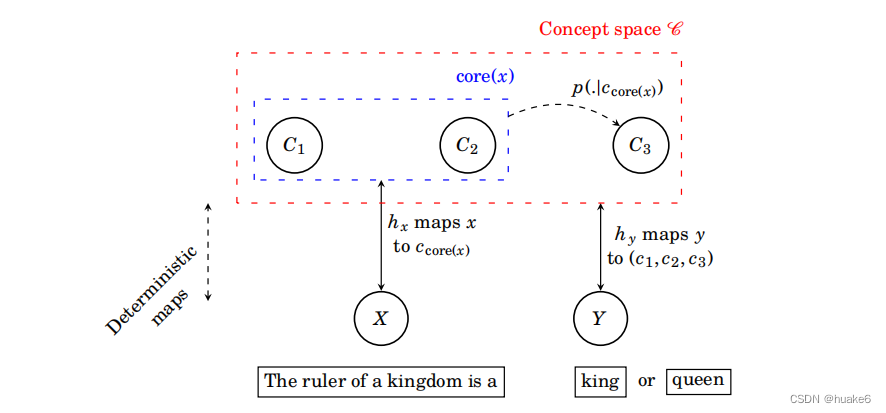
1. 概念空间与下一个词的映射
在潜在条件模型中,上下文句子和下一个词共享相同的潜在空间,其中发生概率推断。这允许我们将下一个词预测问题转化为学习潜在变量之间各种条件概率的问题。我们将潜在空间建模为一组二元随机变量:VC = {C1, …, Cm},其中每个潜在二元随机变量代表一个概念的存在,例如正面情绪与负面情绪。VC包含所有对语言建模感兴趣的相关概念。这些二元随机变量并不一定是独立的,为了模拟它们的依赖性,我们假设这些变量形成一个马尔可夫随机场。
2. 上下文句子与潜在空间的关系
上下文句子X包含了决定下一个词Y的潜在概念的部分信息。我们定义了一个映射hx,它将上下文句子映射到概念空间C,其中C x 是所有能够引发x的潜在概念向量c的集合。在这个子集中,core(x)指示了总是“开启”或“关闭”的概念。给定x,"核心概念"的值是固定的,而非核心概念的其余部分则有待确定。这代表了X和C之间关系的确定性。为了捕捉这种确定性关系,我们定义了映射hx : X → {⋄, 0, 1}m,其中⋄代表“未知”,ci是索引i的核心概念的已知量。我们假设p(c|x) = p(c|ccore(x)),这意味着只有上下文句子中出现的核心概念对下一个词的预测是相关的。
线性表征的形成机制
1. 对数优势匹配导致的线性结构
线性表征的形成机制首先可以从对数优势匹配(log-odds matching)的角度来理解。在特定的训练数据分布假设下,如果学习到的概率的对数优势是一个仅依赖于感兴趣概念的常数,那么该概念在子空间中的表征将呈现线性。这一结果与许多关于词嵌入的现有工作相一致。例如,当概念是独立的,真实分布是乘积分布时,左侧表达式必须与右侧上述假设相匹配,从而满足定理3中的假设。这表明,对数优势匹配在形式上意味着概念表征在子空间中的线性。
2. 梯度下降的隐式偏差与线性表征
除了对数优势匹配外,梯度下降的隐式偏差也促进了整个表征空间中线性结构的出现。尽管下一个词预测是一个高度复杂的非凸优化问题,我们的关注点在于识别优化过程中可能导致线性编码表征的子问题。关键观察是存在一个隐藏的二分类任务。例如,模型仅学习p(·|c1 = 1)和p(·|c1 = 0)的条件分布。已知在这种设置下,梯度下降会收敛到最大边际解,这使得v的方向唯一。定理4进一步明确了这一直觉,表明通过使用固定嵌入的梯度下降优化特定子问题时,潜在的非嵌入表征将被线性编码。
实验验证:模拟实验与大型语言模型的测试
1. 完整条件集合下的线性表征实验
在模拟实验中,我们首先创建了随机有向无环图(DAGs),其中变量/概念的条件概率由伯努利分布建模,参数从[0.3, 0.7]区间内均匀采样。通过这些随机图形模型,我们可以采样二进制向量作为数据集。在完整条件集合下进行训练时,模型学习到的表征确实是线性编码的。此外,实验结果表明,随着损失的减少,余弦相似度迅速增加。
2. 不完整条件集合的影响分析
在现实数据集中,并非每个概念或上下文向量都与一个标记或句子自然对应。因此,不总是有(cid:98)D = D或(cid:98)C = C。我们还进行了额外的实验来观察在这些情况下的模拟设置的行为,特别是在不完整的上下文集合((cid:98)D ⊂ D)和概念向量集合((cid:98)C ⊂ C)下的训练。这些实验表明,线性表征对这些变化是鲁棒的。此外,我们还观察到,即使在表示维度远小于所表示概念数量的情况下,也可以获得合理的线性表征。
独立概念的正交性:理论分析与实证观察
在探讨大型语言模型(LLMs)中的概念表征时,一个引人注目的现象是,这些概念往往以线性方式被表示。这一发现主要基于经验观察,但其背后的原因尚不明确。本文通过引入一个简单的潜变量模型来抽象和形式化下一个词预测的概念动态,从而对这些线性表征的起源进行了研究。我们证明了在学习表示空间中,这些潜在概念确实以线性方式被表示。这一结果分为两部分:首先,我们展示了对数几率匹配导致线性结构的形成;其次,我们证明了即使在对数几率匹配条件失败的情况下,梯度下降的隐式偏差也会促使线性结构的出现。这些结果为线性表征假设提供了有力的支持。
1. 线性表征的起源
线性表征结构并不特定于模型架构的选择,而是模型学习不同上下文和相应输出的条件概率的副产品。简单的潜变量模型产生了类似于LLMs中观察到的线性和正交性等表征行为。这表明它可能是可解释性研究中进一步理论研究的有用工具。
2. 线性表征的实证验证
通过在符合潜变量模型的数据上进行实验,我们证实了这种结构确实会产生线性表征。此外,我们使用LLaMA-2大型语言模型评估了理论的预测,表明简单模型产生了可推广的预测。
讨论:大型语言模型中的表征几何学与因果表示学习
1. 表征几何学的研究
在LLMs中,有时欧几里得几何学可以合理地编码语义,尽管欧几里得内积并未被标准LLM目标识别。我们展示了梯度下降的隐式偏差可能导致欧几里得结构具有特权地位,使得独立概念被表示为几乎正交的向量。
2. 因果表示学习的联系
我们的工作与因果表示学习领域有着微妙的联系。因果表示学习是一个新兴领域,它利用潜变量建模理论与因果性理论的思想,构建各个领域的生成模型。主要目标是构建真实的生成模型,以反映数据集的创建过程。然而,为了研究大型基础模型,仅仅从统计角度构建真实模型可能无法反映全部情况,因为还应该考虑优化的隐式偏差(第3.2节)。此外,识别整个潜在分布可能并非出于某些实际目的而必要,而仅仅表示几何表征中的某些结构信息,例如线性编码的表征,可能就足够了。
结论:简化潜在变量模型对大型语言模型的启示
在深入研究大型语言模型(LLMs)的语义概念编码方式时,一个引人注目的现象是这些概念往往以线性方式呈现。本文通过引入一个简化的潜在变量模型来抽象和形式化下一个词预测的概念动态,揭示了线性表示的起源。我们的研究表明,下一个词预测目标(softmax与交叉熵)以及梯度下降的隐式偏差共同促进了概念的线性表示。实验结果证实,当从与潜在变量模型匹配的数据中学习时,线性表示确实会出现,这证明了这种简单结构已足以产生线性表示。此外,我们使用大型语言模型LLaMA-2对理论进行了验证,证明了简化模型可以产生具有普遍性的洞察。
1. 线性表示结构的普遍性
首先,线性表示结构并不特定于模型架构的选择,而是模型学习不同上下文和相应输出的条件概率的副产品。这意味着,即使在不同的模型架构中,只要学习过程相似,线性表示结构也可能出现。
2. 简化潜在变量模型的启示
简化的潜在变量模型产生了与LLMs中观察到的类似线性和正交性的表示行为。这表明它可能是可解释性研究中进一步理论研究的有用工具。例如,我们的模型预测,即使在训练数据分布的图形结构或真实条件概率未知的情况下,也会出现线性表示。
3. 欧几里得几何在表示中的特殊地位
我们的研究还表明,由于梯度下降的隐式偏差,欧几里得结构在表示中具有特殊地位,使得独立概念几乎正交地表示。这与LLMs中观察到的现象相符,即语义上无关的概念往往以几乎正交的向量表示。
4. 实验验证
通过在潜在变量模型上进行的模拟实验以及对LLaMA-2的评估,我们验证了理论预测的准确性。这些实验表明,简化模型不仅能够产生线性表示,而且在实际的大型语言模型中也观察到了嵌入和解嵌表示之间的一致性。
综上所述,简化潜在变量模型为我们提供了理解大型语言模型中概念如何被编码的新视角。这些发现强调了优化过程中隐式偏差的作用,并为未来的可解释性研究提供了理论基础。通过这些洞察,我们可以更好地理解和预测LLMs的行为,这对于提高它们的透明度和可信度至关重要。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人