
提升信用违约预测准确性,一套全新机器学习工作流诞生

开篇:金融科技中的信用违约预测的重要性
在金融科技(FinTech)领域,信用违约预测(Credit Default Prediction,CDP)是一个日益受到工业界和学术界关注的应用。信用违约预测在评估个人和企业的信用状况方面发挥着至关重要的作用,它使贷款机构能够就贷款批准和风险管理做出明智的决策。随着数据量的激增和信用预测任务中关系的复杂性,传统的统计模型往往难以捕捉复杂的金融模式,而深度学习(Deep Learning,DL)方法因其优越的性能而在金融领域获得了显著的关注。
信用评分是金融领域的一个关键任务,贷款机构必须评估潜在借款人的信用状况。为了确定信用风险,必须深入调查与借款人的收入、信用历史和其他相关方面的特征。银行和其他金融机构必须收集消费者信息,以区分可靠的借款人和无力偿还债务的借款人,这导致了信用违约预测问题的解决,换句话说,就是一个二元分类问题。
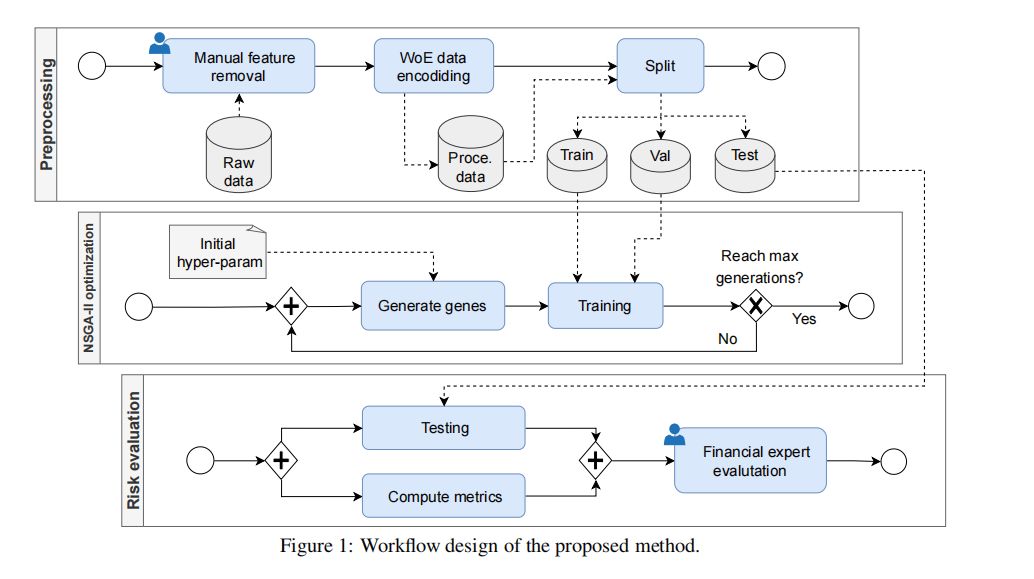
本文提出了一种基于工作流的方法来改进CDP,该方法包括多个步骤,每个步骤都旨在利用机器学习管道中不同技术的优势,从而最好地解决CDP任务。我们采用全面系统的方法,从使用证据权重(Weight of Evidence,WoE)编码的数据预处理开始,该技术确保了一次性数据缩放,通过去除异常值、处理缺失值和使模型能够处理不同数据类型的数据统一化。接下来,我们训练了几种学习模型,引入了集成技术来构建更健壮的模型,并通过多目标遗传算法进行超参数优化,以考虑预测准确性和金融方面的因素。我们的研究旨在为FinTech行业提供一个工具,以实现更准确、更可靠的信用风险评估,使贷款机构和借款人双方受益。
论文标题: A machine learning workflow to address credit default prediction
论文链接:https://arxiv.org/pdf/2403.03785.pdf
公众号【AI论文解读】后台回复“论文解读” 获取论文PDF!
信用违约预测(CDP)的工作流程介绍
信用违约预测(Credit Default Prediction, CDP)是金融科技领域的一个重要应用,它关系到个人和企业的信用评估,帮助贷款机构做出明智的贷款批准和风险管理决策。以下是CDP的工作流程介绍:
1. 数据预处理:权重证据编码
数据预处理是CDP工作流程的第一步,关键在于使用权重证据(Weight of Evidence, WoE)编码技术。WoE编码是一种目标编码方法,能够捕捉特征与目标变量之间的非线性关系。它通过分箱处理缺失值,并将特征(无论是数值型还是类别型)缩放为单一连续变量,从而降低数据维度。这种编码方式对于统计模型、机器学习模型和深度学习模型都非常有用,因为这些模型可能只能处理特定类型的数据。
2. 学习模型训练:集成技术与超参数优化
在数据预处理之后,接下来是模型训练和优化。这一步涉及多种学习模型的训练,并引入集成技术来构建更加健壮的模型。同时,通过多目标遗传算法进行超参数优化,以考虑预测准确性和金融方面的因素。
3. 模型评估:金融专家的参与
模型评估是工作流程的最后一步,不仅包括计算评估指标,还涉及金融专家的参与。专家们评估模型的性能,并提供宝贵的反馈,以确保模型的实用性和准确性。
学习模型的分类与优化
在信用违约预测中,我们采用了三类学习模型,并对它们进行了优化:
1. 统计模型:逻辑回归
逻辑回归是一种流行的统计模型,用于二元分类。它通过计算观测值被分类为好或坏借款人的概率来进行预测。模型参数训练完成后,可以使用决策规则将输入特征向量分类为输出值。
2. 机器学习模型:分类树
分类树是机器学习中常用的分类器之一。它类似于流程图,其中每个内部节点代表一个特征,每个分支代表一个决策规则,每个叶节点代表分类结果。算法通过基于每个节点最佳分割数据的特征递归地划分数据集,直到达到停止标准。
3. 深度学习模型:多层感知机
多层感知机是深度学习中的一种模型,它通过学习输入数据的层次化表示和复杂模式,相比传统模型有更好的表现。
4. 集成策略与模型权重
每个学习模型都可以通过集成技术进行增强。这种方法结合了多个模型的预测,以提高整体的分类性能。具体来说,实施了基于权重的投票策略来结合预测。集成模型的决策函数可以表示为各个单独模型预测的类概率的加权和。
数据编码:权重证据(WoE)编码的应用
在金融科技(FinTech)领域,信用违约预测(Credit Default Prediction, CDP)是一个重要的任务,它涉及评估借款人违约的可能性。为了提高CDP的准确性,数据预处理是一个关键步骤,而权重证据(Weight of Evidence, WoE)编码是一种常用的数据预处理技术。
1. WoE编码的优势
WoE编码作为一种目标编码方法,它能够捕捉特征与目标变量之间的非线性关系。这种编码方式在处理信用评分数据集时尤为有用,因为这些数据集经常受到缺失值的影响。WoE编码通过将缺失值单独分箱来处理这一问题。此外,WoE编码通过将特征(无论是数值型还是类别型)缩放为单一连续变量,降低了数据的维度,这对于统计模型、机器学习和深度学习模型来说特别有用,因为这些模型可能只能处理特定类型的数据。
2. WoE编码的应用
在我们的工作流程中,我们采用了WoE编码来预处理数据集。对于类别变量,WoE值的计算公式如下:WoEi = ln(Pi,1 / Pi,0),其中Pi,1是类别i中借款人违约的概率,Pi,0是类别i中借款人未违约的概率。
对于数值变量,我们首先通过分箱过程将其离散化,然后应用WoE编码。值得注意的是,WoE编码本身不包含分箱策略,因此必须明确定义并集成到数据编码中。我们采用了Palencia提出的最优分箱方法,该方法通过混合整数编程解决数学优化问题,确保了分箱的最优性。
超参数优化:NSGA-II算法的应用
在构建信用评分模型时,超参数优化是提高模型性能的重要步骤。我们在工作流程中引入了非支配排序遗传算法II(Non-dominated Sorting Genetic Algorithm II, NSGA-II)来执行模型的超参数优化。
1. NSGA-II算法的特点
NSGA-II是一种著名的多目标优化算法,广泛应用于各个领域。在我们的工作流程中,我们使用NSGA-II来优化模型的超参数,同时考虑两个不同的目标函数:接收者操作特征曲线下面积(Area Under the Receiver Operating Characteristic curve, AUC)作为分类度量,以及预期最大利润(Expected Maximum Profit, EMP)作为财务度量。通过纳入EMP,我们的目标是优化信用评分模型,不仅仅是为了分类准确性,还为了它们的财务影响。
2. NSGA-II算法的应用
通过NSGA-II算法,我们能够找到一组非支配解,这些解在AUC和EMP之间提供了最佳的权衡,并允许我们根据特定金融机构的具体要求选择最佳模型。这种方法使我们能够在考虑预测准确性和财务方面的同时,最大化模型的性能。
焦点损失函数:处理类别不平衡问题
在机器学习中,特别是在处理信用违约预测(CDP)这类二元分类问题时,类别不平衡是一个常见且棘手的问题。类别不平衡意味着数据集中的一个类别的样本数量远多于另一个类别,这可能导致模型在预测时偏向于多数类,从而忽视少数类的重要性。在信用评分领域,这种不平衡尤为明显,因为违约的借款人通常远少于守约的借款人。
为了解决这一问题,我们采用了一种名为焦点损失函数(focal loss)的方法。焦点损失函数是交叉熵损失函数的一种改进,它通过增加一个调整参数(focusing parameter γ)和一个类别权重(αt),来增加模型对难以正确分类样本的关注。其公式为:
FL(pt) = −αt (1 − pt)γln(pt)
其中,pt是模型预测为真实类别的概率,αt是类别t的权重因子,γ是聚焦参数。通过这种方式,模型在训练过程中对那些难以分类的样本(即模型预测错误的样本)给予更多的关注,从而提高模型对少数类的识别能力。
实验验证:数据集和实验设置
数据集概览:GER、HEL、HECL和PBD
在我们的实验中,我们使用了四个公开可用的基准数据集:GER、HEL、HECL和PBD。这些数据集在信用评分研究中广为人知,并提供了一个共同的参考点,使不同模型之间的比较变得有意义。
- GER(GermanCreditData)数据集和PBD(PolishBankruptcyData)数据集可以通过UCI机器学习存储库获取。
- HEL(HomeEquityLoans)数据集于2020年公开发布。
- HECL(HomeEquityCreditLine)数据集由Fair Isaac Corporation(FICO)作为可解释机器学习挑战的一部分提供。
这些数据集包含了从1000到43405不等的样本量,覆盖了不同的信用评分场景。
实验结果:深度学习模型的优越性
实验结果表明,深度学习(DL)模型在所有数据集上的性能均优于传统的统计模型和机器学习(ML)模型。具体来说,多层感知机(MLP)和集成多层感知机(EMLP)模型在性能表现上一致位于表格的最后几行,显示出它们的优越性。此外,集成模型相比于非集成模型展现出了性能的提升。
通过这些实验,我们验证了焦点损失函数在处理类别不平衡问题时的有效性,以及深度学习模型在信用评分任务中的潜力。
结论与未来研究方向
1. 本研究的贡献与实际应用潜力
本研究提出了一种基于工作流的方法来改进信用违约预测(CDP),这是评估借款人信用风险的关键任务。通过采用机器学习(ML)技术,我们的方法在数据预处理、模型训练、超参数优化和评估指标计算等多个步骤中各取所长,以最佳方式解决CDP任务。特别是,我们采用了证据权重(WoE)编码进行数据预处理,引入了集成学习策略以构建更鲁棒的模型,并通过多目标遗传算法进行超参数优化,同时考虑预测准确性和金融方面的因素。
我们的研究为金融科技行业提供了一种工具,旨在实现更准确、更可靠的信用风险评估,从而使贷款机构和借款人双方受益。通过在公开可用的基准数据集上展示的结果,我们证明了所提出方法的有效性,并为信用评分和风险评估提供了有力的支持。
2. 未来研究的可能方向
未来的研究可以探索将我们的方法应用于真实世界场景,通过将分类模型集成到企业软件系统中,从而提高银行员工和金融顾问的可用性。这种集成有潜力简化和优化金融流程,为银行和金融咨询领域面临的挑战提供实际解决方案。此外,这种方法的适用性可以扩展到客户信用评分之外的公司信用评分。
未来的工作还可以包括进一步研究和改进数据预处理技术,如WoE编码,以及探索其他集成学习策略和超参数优化方法,以进一步提高模型的性能和财务影响。此外,考虑到类别不平衡问题,未来的研究可以探索新的损失函数,如焦点损失(focal loss),以及其他技术来提高模型对困难分类样本的关注度。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人