
set学习笔记
1 Set的介绍
set: 存储无序,不可重复的数据
-
- Set接口是Collection的子接口,set接口没有提供额外的方法
- Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个Set 集合中,则添加操作失败。
- Set 判断两个对象是否相同不是使用
==运算符,而是根据equals()方
2 对与无序和不可重复的理解:
无序性:存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定的。但是不等于随机性。
不可重复性:保证添加的元素按照equals()判断时,不能返回true.即:相同的元素只能添加一个(TreeSet除外)。
TreeSet是根据compareTo是否为0进行比较
3 Set接口实现类的对比
---Collection接口:
----set接口:存储无序,不可重复的数据
----HashSet:Set的主要实现类;线程不安全但是效率高;可以储存null值
----LinkedHashSet:是HashSet的子类。可以按照添加的顺序遍历
底层有前后指针,故对于频繁的遍历操作,LinkedHashSet效率是高于 HashSet的
----TreeSet: 可以按照添加对象的指定属性(也就是说,属性的类型要相同),进行操作。
底层是红黑树和HashMap一样
4 HashSet的特点:
不能保证元素的排列顺序
HashSet不是线程安全的
集合元素可以是null
底层也是数组,初始容量为16,当如果使用率超过0.75,(16*0.75=12)就会扩大容量为原来的2倍。(16扩容为32,依次为64,128…等)
HashSet 集合判断两个元素相等的标准:两个对象通过hashCode() 方法比较相等,并且两个对象的equals()方法返回值也相等。
5 添加元素过程
我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,
* 此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),判断
* 数组此位置上是否已经有元素:
* 如果此位置上没有其他元素,则元素a添加成功。 --->情况1
* 如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值:
* 如果hash值不相同,则元素a添加成功。--->情况2
* 如果hash值相同,进而需要调用元素a所在类的equals()方法:
* equals()返回true,元素a添加失败
* equals()返回false,则元素a添加成功。--->情况2
*
* 对于添加成功的情况2和情况3而言:元素a 与已经存在指定索引位置上数据以链表的方式存储。
* jdk 7 :元素a放到数组中,指向原来的元素。
* jdk 8 :原来的元素在数组中,指向元素a
* 总结:七上八下
6 HashCode()和equals()的重写
为什么要重写HashCode和equals方法
由于在创建对象时,Object类会随机生成一个哈希值。所以,即使对象的属性元素相同,在HashSet输出时,仍然输出两个对象,不符合不可重复性。故要重写HashCode和equals方法。
具体操作idea有自动重写
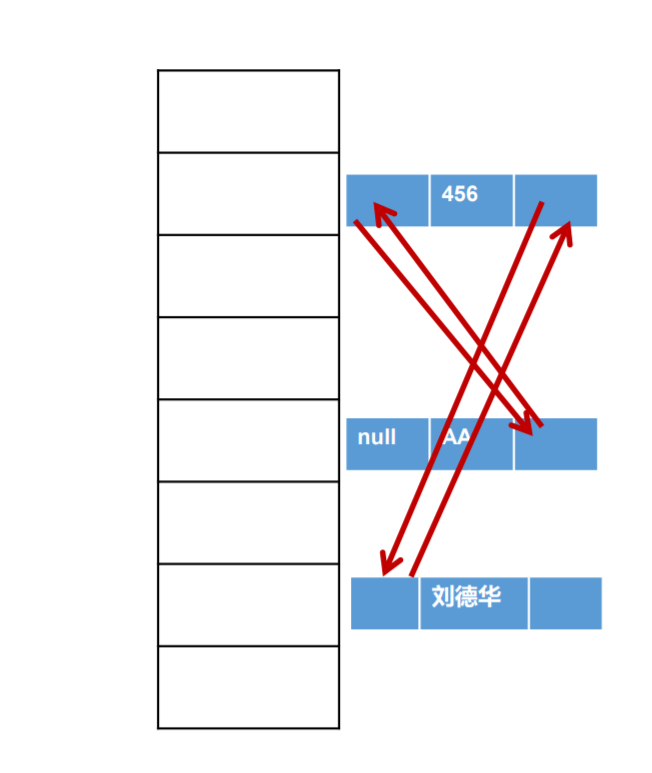
7 LinkedHashSet
LinkedHashSet 是 HashSet 的子类
LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置, 但它同时使用双向链表维护元素的次序,这使得元素看起来是以插入 顺序保存的。
LinkedHashSet插入性能略低于 HashSet,但在迭代访问 Set 里的全 部元素时有很好的性能。
LinkedHashSet 不允许集合元素重复。
内部原理图:
7 TreeSet
TreeSet底层使用红黑树结构存储数据TreeSet可以确保集合元素处于排序状态。TreeSet两种排序方法:自然排序和定制排序。默认情况下,TreeSet采用自然排序。定制排序是,在创建TreeSet的构造器是含参,并且使用Comparator方法。- 如果试图把一个对象添加到TreeSet时,则该对象的类必须实现Comparable 接口。
- 自然排序:
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列。 - 对于
TreeSet集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过compareTo(Object obj)方法比较返回值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号