搭建yolov8模型训练的环境_制作docker镜像_模型训练
搭建一个能进行yolov8模型训练的环境,包括CUDA 11.x、cuDNN 8.x、Ubuntu 18.04、Python 3.8、Cython、NumPy、PyTorch、YOLOv8、Ultralytics等依赖(其实ultralytics 包会包含 YOLOv8 及其相关工具)。在 Docker 容器中,不需要创建虚拟环境,每个容器本身就像是一个隔离的环境,所以可以直接在 Dockerfile 中安装所需的依赖项。
一、主要步骤:
1.前提:宿主机安装了docker、nvidia-docker、显卡驱动
2.在docker的配置文件中配置镜像加速器
3.构建docker镜像
4.运行docker容器
5.验证容器内的环境
6.开始模型训练
7.模型推理验证
8.部署到Android端
二、详细内容:
1.验证宿主机安装了docker、nvidia-docker、显卡驱动
1.1宿主机为什么需要安装nvidia-docker
nvidia-docker 和 docker 都是用于容器化应用的工具,但它们的主要区别在于 nvidia-docker 支持 NVIDIA GPU 加速,可以让容器中的应用程序访问宿主机上的 GPU资源,从而提高应用程序的性能。而 docker 则是一个通用的容器化工具,不提供 GPU 加速功能。因此,如果需要在容器中运行需要 GPU 加速的应用程序,就需要使用nvidia-docker 来创建和管理容器。
nvidia-docker2.0对nvidia-docker1.0进行了很大的优化,不用再映射宿主机GPU驱动了,直接把宿主机的GPU运行时映射到容器即可,容器内无需安装gpu驱动和cuda了。
1.2查看服务器上是否安装了docker
docker -v
1.3查看服务器上是否安装了nvidia-docker
dpkg -l | grep nvidia-docker

服务器上显示的这条内容代表宿主机已经安装了 nvidia-docker2。dpkg -l 命令列出了所有已安装的.deb软件包,grep nvidia-docker 则是过滤出了含有 “nvidia-docker” 字段的条目。从输出中可以看到 nvidia-docker2 的版本为 2.14.0-1,这说明 nvidia-docker2 包已经安装且目前是最新版本。(nvidia-docker2 是 nvidia-docker 的新版本,提供了与NVIDIA容器工具集的集成。)
宿主机上安装了 nvidia-docker2 包之后,就可以在运行 Docker 容器时使用 NVIDIA GPU 了。nvidia-docker2 包包括 nvidia-container-toolkit,这是一个允许 Docker 容器访问宿主机上的 NVIDIA GPU 的工具。
1.4查看服务器安装了显卡驱动
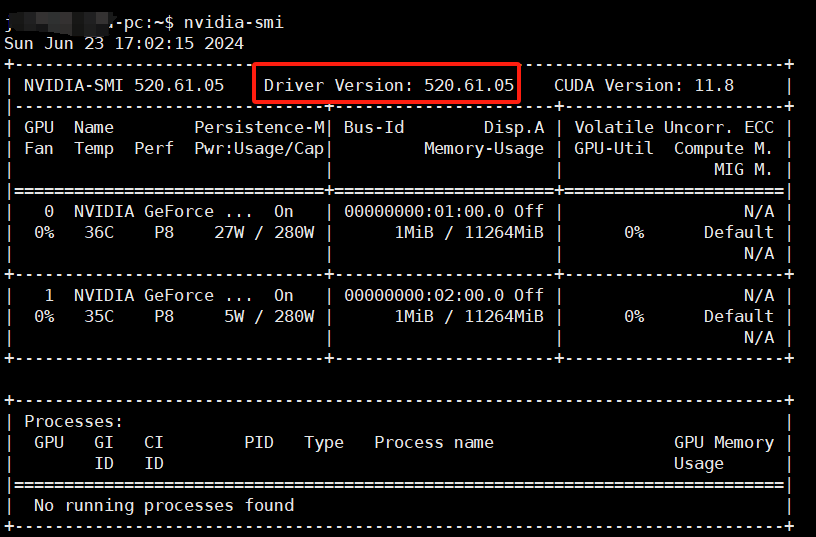
在终端中输入nvidia-smi命令来查看GPU驱动版本
nvidia-smi
2.在docker的配置文件中配置镜像加速器
使用Docker镜像加速器可以更加稳定地下载镜像。通常拉取镜像失败,提示“构建 Docker 镜像时由于网络超时问题无法从 Docker 注册表中拉取基础镜像”。这通常是由于网络连接问题,特别是在中国大陆访问国外 Docker 镜像仓库时容易出现这种情况。
配置镜像加速器:编辑daemon.json
在 Docker 守护进程配置文件中(通常是 /etc/docker/daemon.json)
cd /etc/docker
sudo vim daemon.json
添加或修改以下内容:
{ "registry-mirrors": [ "https://registry.docker-cn.com", "https://docker.mirrors.ustc.edu.cn", "https://hub-mirror.c.163.com", "https://mirror.baidubce.com", "https://docker.m.daocloud.io", "https://noohub.ru", "https://huecker.io", "https://dockerhub.timeweb.cloud" ], "runtimes": { "nvidia": { "args": [], "path": "/usr/bin/nvidia-container-runtime" } } }
然后重启 Docker 服务:
sudo systemctl daemon-reload sudo systemctl restart docker
3.构建docker镜像
(1)手动拉取镜像
有时候直接拉取镜像比通过 Dockerfile 构建更稳定。(我最开始没有手动拉取,而是直接通过dockerfile构建,但是失败了。所以还是选择先手动拉取基础镜像,然后再构建)
sudo docker pull nvidia/cuda:11.6.2-cudnn8-devel-ubuntu18.04
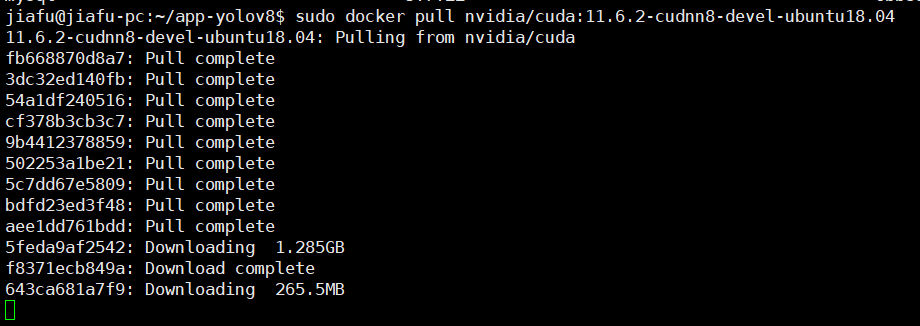
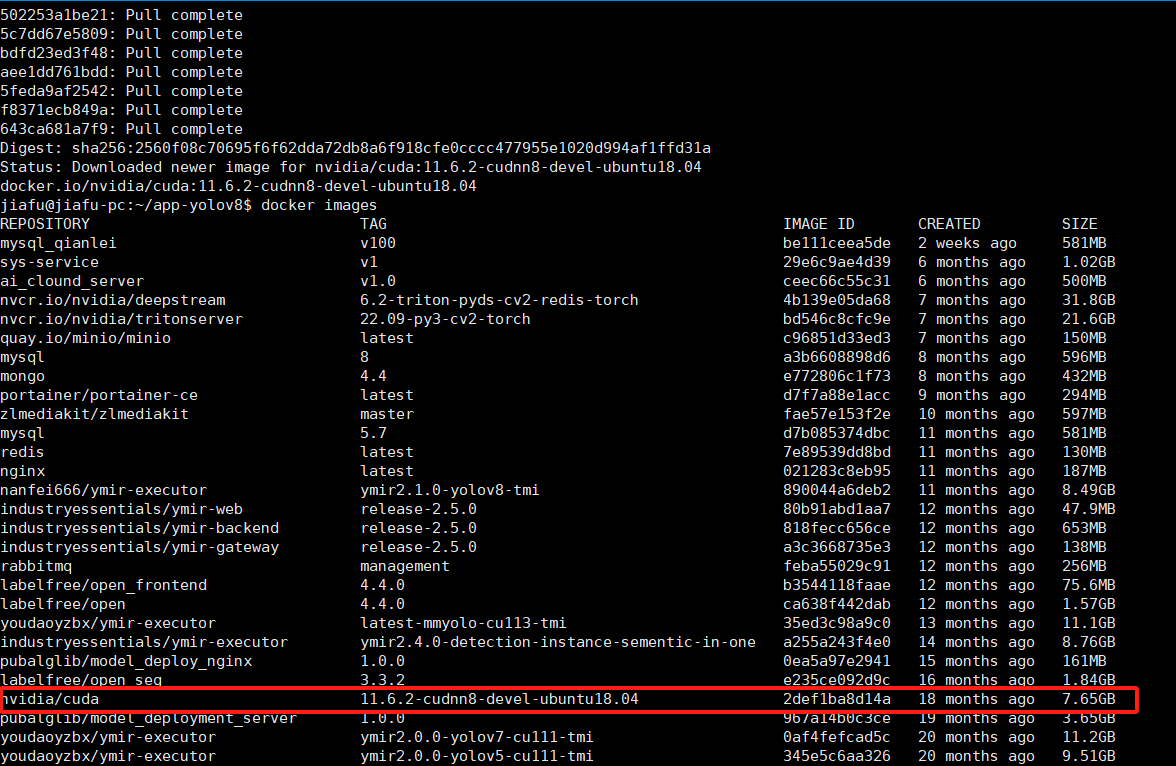
手动拉取镜像成功后,可以直接在 Dockerfile 中指定本地镜像,而无需再次从远程仓库拉取。(Dockerfile 中的命令保持不变。当构建 Docker 镜像时,如果本地已经存在指定的基础镜像,Docker 将自动使用本地镜像,而不会再次从远程仓库拉取。)
(2)创建一个app-yolov8文件夹
mkdia app-yolov8
(3)进入文件夹
cd app-yolov8
(4)创建Dockerfile文件
touch Dockerfile
(5)编辑Dockerfile
# 基础镜像,包含 CUDA 11.x 和 cuDNN 8.x FROM nvidia/cuda:11.6.2-cudnn8-devel-ubuntu18.04 # 设置环境变量 ENV DEBIAN_FRONTEND=noninteractive # 安装基本工具 RUN apt-get update && apt-get install -y \ software-properties-common \ curl \ wget \ git \ vim \ unzip \ build-essential \ && rm -rf /var/lib/apt/lists/* # 安装 Python 3.8 RUN add-apt-repository ppa:deadsnakes/ppa \ && apt-get update \ && apt-get install -y python3.8 python3.8-dev python3.8-distutils \ && rm -rf /var/lib/apt/lists/* # 设置 Python 3.8 为默认 RUN update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.8 1 \ && update-alternatives --install /usr/bin/python python /usr/bin/python3.8 1 # 安装 pip 并更新到最新版本,同时配置使用清华源 RUN curl -sS https://bootstrap.pypa.io/get-pip.py | python3.8 \ && pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple # 安装 Cython 和 NumPy RUN pip install cython numpy # 安装 PyTorch 2.0,并指定使用 CUDA 11.8,使用清华源
RUN pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 -f https://download.pytorch.org/whl/torch_stable.html # 安装 Ultralytics 和 YOLOv8,使用清华源 RUN pip install ultralytics # 设置工作目录 WORKDIR /home/jiafu/app-yolov8 # 复制代码 COPY . . # 建立日志 RUN mkdir log # 暴露端口 EXPOSE 19090 # 复制训练脚本到容器中 # 运行训练脚本 # 进入交互模式 CMD ["bash"]
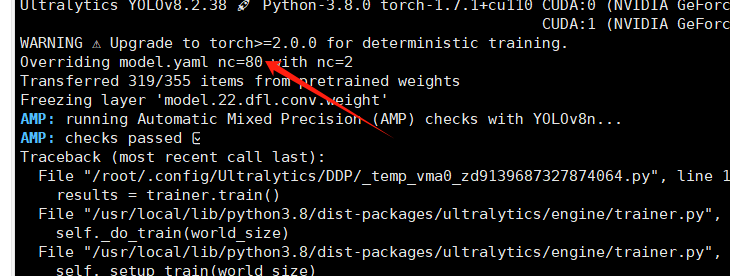
上面dockerfile里的pytorch其实一开始不是这个版本,也是后面运行脚本和模型训练时,遇到了很多次报错后,找到的一个适配的2.0版本。
(解决:升级pytorch版本,1.9以后的大概就可以,官方推荐torch>=2.0.0版本,pytorch升级命令可查看Previous PyTorch Versions PyTorch
(6)构建 Docker 镜像:
docker build -t yolov8-env .
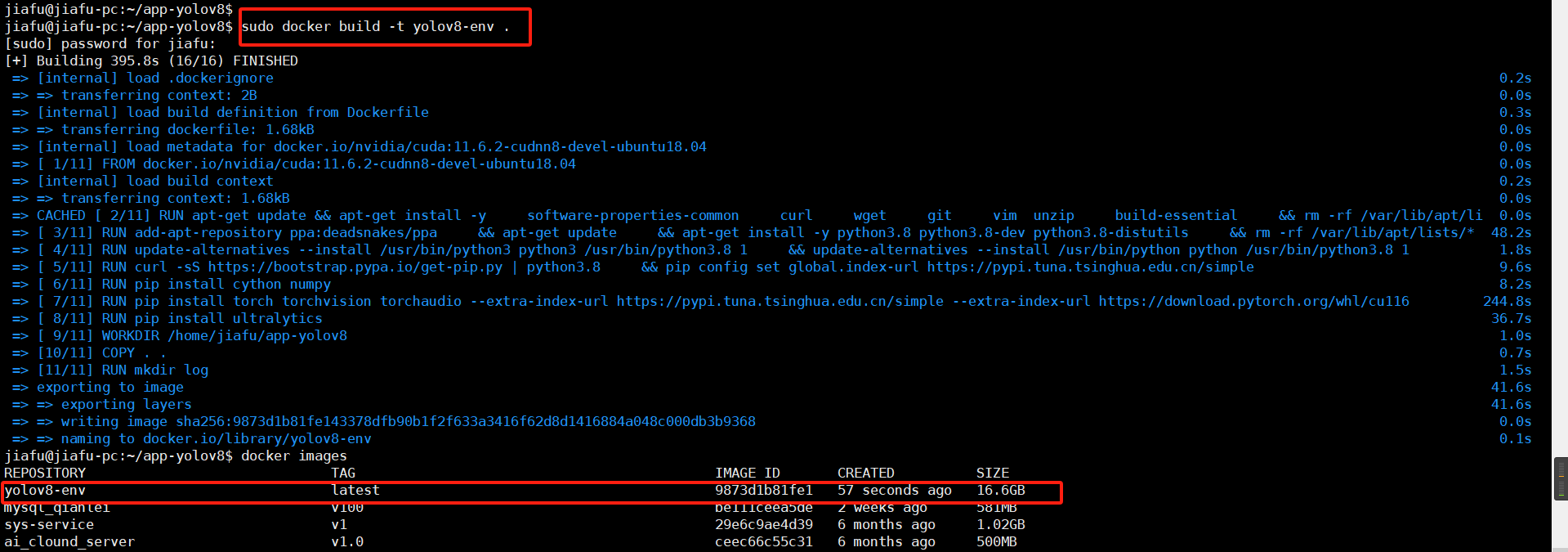
4.运行docker容器
先启动容器,确保容器在运行,再进入容器
# docker run --gpus all --privileged -dti --name yolov8-rq -p 29090:19090 yolov8-env:latest # 这句后来会报错,需要根据实际需求,增加共享内存大小 docker run --gpus all --privileged -dti --name yolov8-rq --shm-size=24g -p 29090:19090 yolov8-env:latest /bin/bash # 指定了共享内存大小为24g docker exec -it yolov8-rq bash #########注释 --gpus all:允许容器使用所有可用的 GPU。 --privileged:赋予容器扩展的权限。 -d:在后台运行容器(分离模式)。 -t:分配一个伪终端。 -i:保持标准输入打开。 --name yolov8-rq:为容器指定名称。 -p 29090:19090:端口映射。将主机的 29090 端口映射到容器的 19090 端口。 yolov8-env:latest:Docker 镜像及其标签。 bash:容器启动时调用可执行文件
启动容器:

进入容器:
接上面运行语句,当时模型训练中断,报错提示是:
Traceback (most recent call last): File "/usr/lib/python3.8/multiprocessing/popen_fork.py", line 27, in poll pid, sts = os.waitpid(self.pid, flag) File "/usr/local/lib/python3.8/dist-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler _error_if_any_worker_fails() RuntimeError: DataLoader worker (pid 4949) is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit.
使用free -h 系统将会以人类可读的格式显示当前的内存使用情况,包括总内存、已用内存、空闲内存等信息。
free -h

解决办法是把之前的容器停了,提交了新的镜像yolov8-env2,运行新的容器时增加共享内存大小。
5.验证容器内的环境
查看容器内的各种依赖和环境设置。按照下面的命令,一步一步的执行。
# 检查 Python 版本 python3 --version # 检查 pip 版本 pip --version # 列出所有已安装的 Python 包 pip list # 检查特定包是否已安装 pip list | grep numpy pip list | grep torch pip list | grep ultralytics # 检查 CUDA 版本 nvcc --version # 检查 GPU 可用性 nvidia-smi # 验证 ultralytics 库 python3 -c "import ultralytics; print(ultralytics.__version__)"
或者写个脚本,通过运行Python 代码来验证 CUDA 和 GPU 可用性:
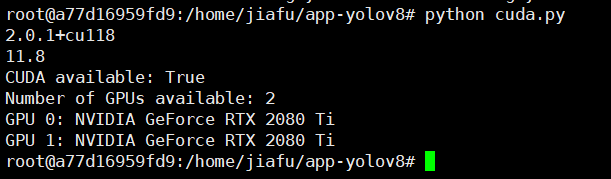
import torch print(torch.__version__) print(torch.version.cuda) # 检查CUDA是否可用 print("CUDA available:", torch.cuda.is_available()) # 打印可用的GPU设备数 print("Number of GPUs available:", torch.cuda.device_count()) # 打印每个GPU设备的信息 for i in range(torch.cuda.device_count()): print(f"GPU {i}: {torch.cuda.get_device_name(i)}")
执行情况:
6.开始模型训练
运行命令:
yolo task=detect mode=train model=yolov8n.pt data=config.yaml batch=16 epochs=400 imgsz=640 workers=16

一开始执行的batch为32,但是后来训练到中间时出现出错,所以将batch改为了16。
最后训练结束情况:
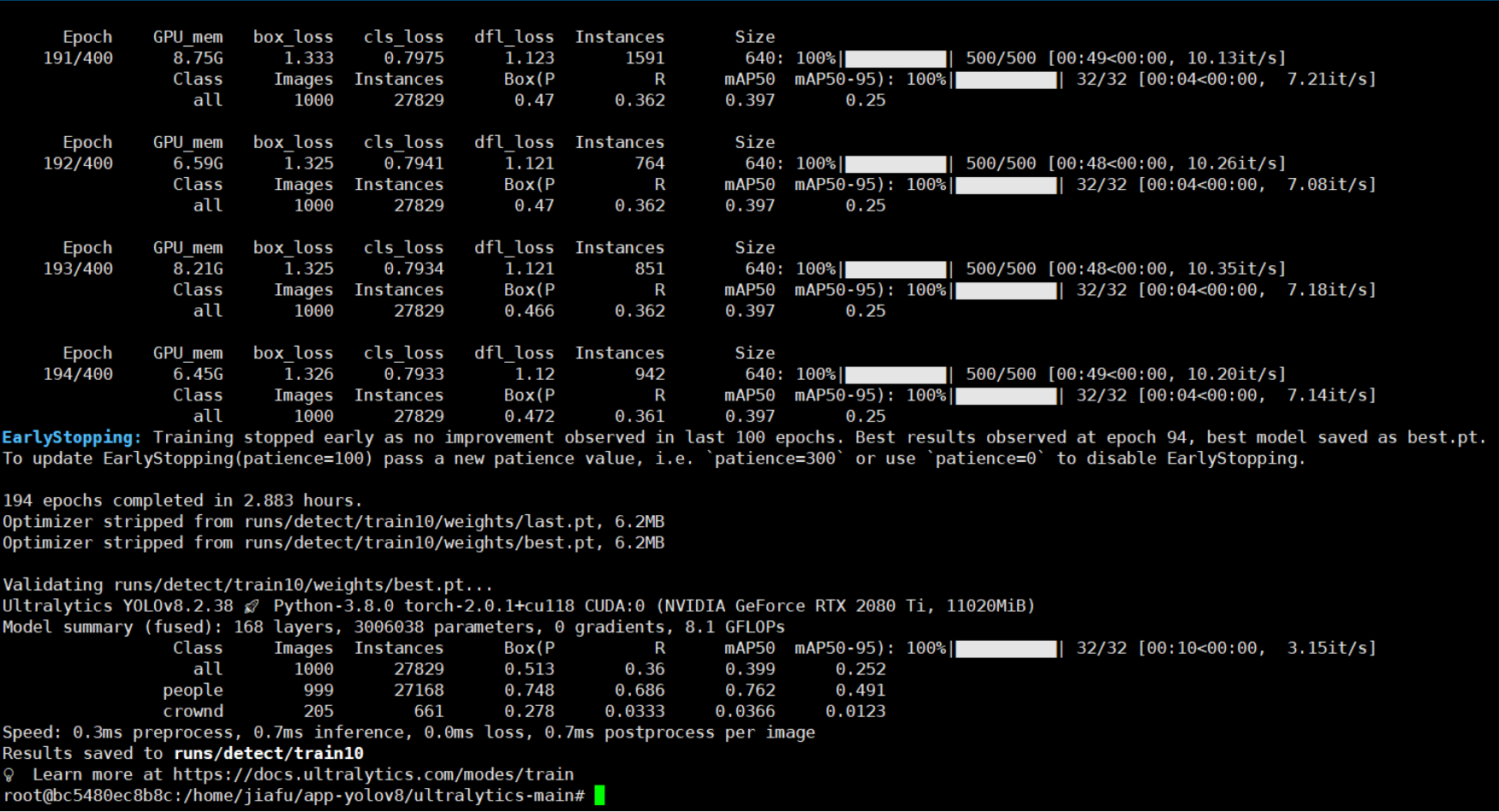
这里面有段话是这样的:EarlyStopping: Training stopped early as no improvement observed in last 100 epochs. Best results observed at epoch 94, best model saved as best.pt. To update EarlyStopping(patience=100) pass a new patience value, i.e. `patience=300` or use `patience=0` to disable EarlyStopping. 194 epochs completed in 2.883 hours. Optimizer stripped from runs/detect/train10/weights/last.pt, 6.2MB Optimizer stripped from runs/detect/train10/weights/best.pt, 6.2MB
这段信息是关于使用了早停法(EarlyStopping)的深度学习训练过程中的一些关键事件的描述。早停法是一种常用的技术,用于防止模型过拟合,通过在验证集上的性能不再提升时停止训练。表明训练提前结束了,在第 94 轮训练时观察到了最佳性能,并且该轮的最佳模型已被保存为 best.pt 文件。
查看模型文件:因为在过去的 100 轮中没有观察到性能的提升,最佳模型在第 94 轮被保存。
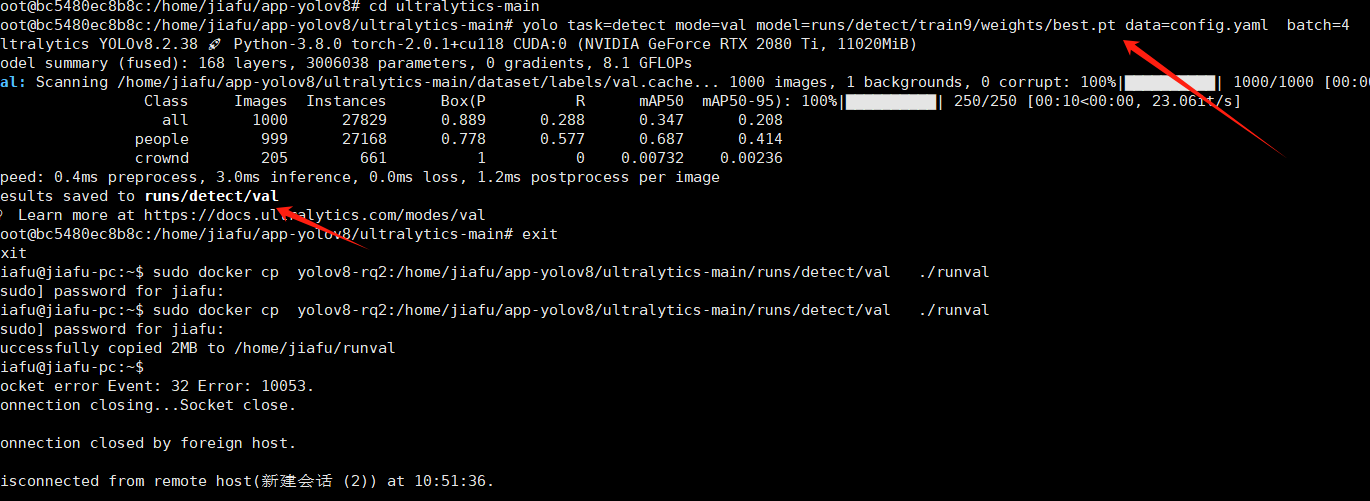
7.模型推理验证
yolo task=detect mode=val model=runs/detect/train9/weights/best.pt data=config.yaml batch=4
8.部署到Android端
yolov8模型训练之后,默认得到的文件格式为pt后缀,先将pt文件转换为onnx格式,再onnx文件再转换为ncnn文件。可查看下面博客的操作流程:
参考:
1.docker中使用gpu https://blog.csdn.net/qq_42152032/article/details/131342043
2.GPU驱动、CUDA和cuDNN之间的版本匹配与下载 https://blog.csdn.net/eastking0530/article/details/126571601
3.确定与GPU驱动匹配的CUDA版本 https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
4.docker凉了,国内镜像站全军覆没!https://mp.weixin.qq.com/s/YBoxpp6XPZhw-adaZBBUGA
5.模型导出Ultralytics YOLO https://docs.ultralytics.com/zh/modes/export/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号