

几种基础的排序算法:冒泡、插入、选择
排序
--为什么插入排序比冒泡排序更受欢迎?
一、排序算法
最经典最常用的:冒泡排序、插入排序、选择排序、归并排序、快速排序、计数排序、基数排序、桶排序。
| 排序算法 | 时间复杂度 | 是否基于比较 |
|---|---|---|
| 冒泡、插入、选择 | O(n^2) | 是 |
| 快排、归并 | 是 | |
| 桶、计数、基数 | O(n) | 否 |
二、如何分析一个排序算法
- 排序算法的执行效率
- 最好情况、最坏情况、平均情况时间复杂度
- 时间复杂度的系数、常数、低阶
- 比较次数和交换(移动)次数
- 排序算法的内存消耗
原地排序:特指空间复杂度是O(1)的排序算法。冒泡、插入、选择都是原地排序算法。
- 排序算法的稳定性
稳定排序算法: 一组数据经过排序后相同的数据的位置不发生改变。
三、冒泡排序(Bubble Sort)
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复 n 次,就完成了 n 个数据的排序工作。
我们要对一组数据 4,5,6,3,2,1,从小到到大进行排序。第一次冒泡操作的详细过程就是这样:
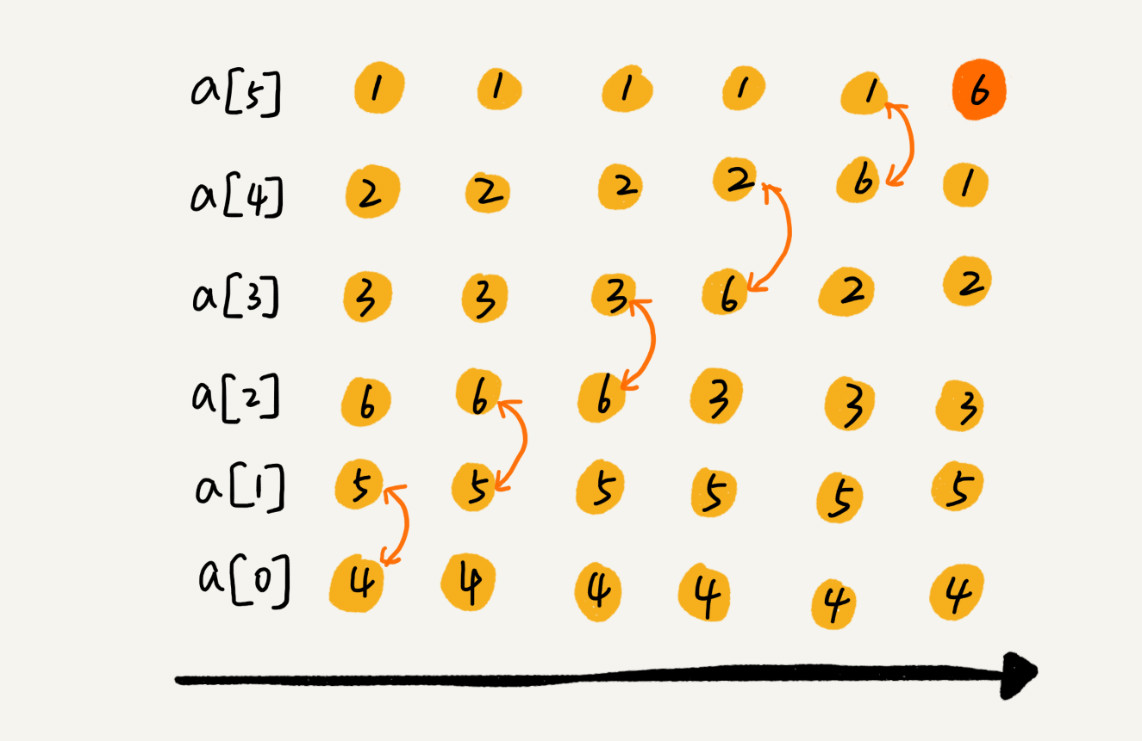
可以看出,经过一次冒泡操作之后,6 这个元素已经存储在正确的位置上。要想完成所有数据的排序,我们只要进行 6 次这样的冒泡操作就行了。

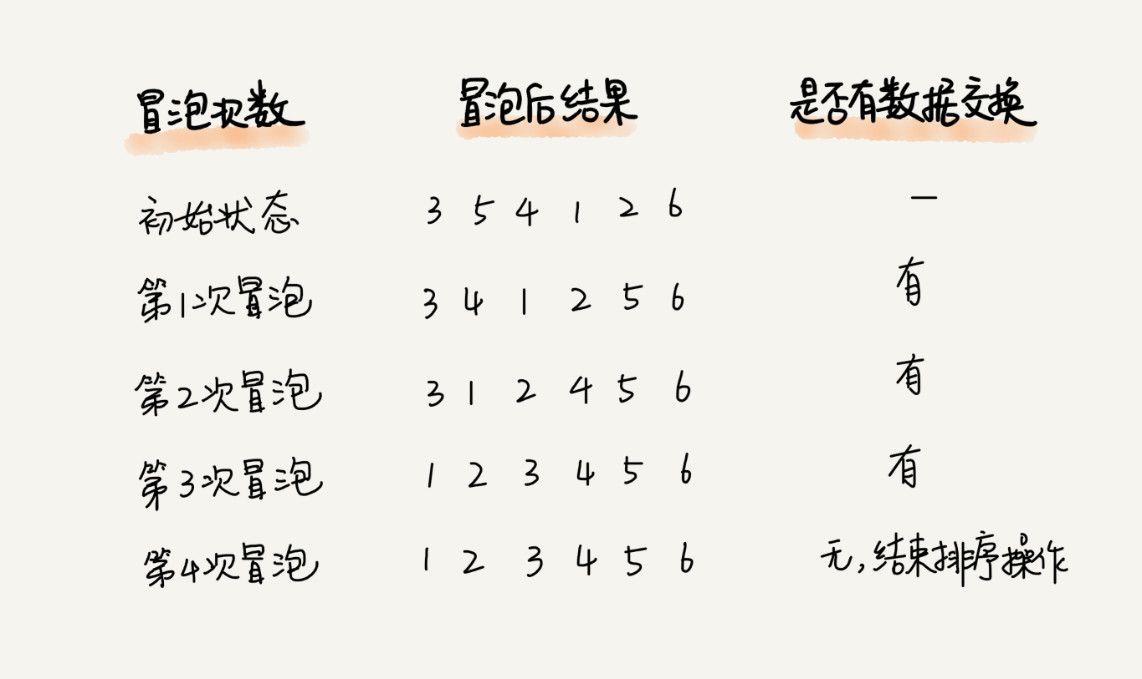
实际上,刚讲的冒泡过程还可以优化。当某次冒泡操作已经没有数据交换时,说明已经达到完全有序,不用再继续执行后续的冒泡操作。
排序的移动次数为逆序度。
逆序度 = 满有序度 - 有序度
4,5,6,3,2,1
上例 有序度为3,{(4, 5), (4, 6), (5, 6)}
则需要移动次数为 n*(n-1)/2 - 初始有序度,即6*(6-1)/2 - 3 = 12 次。
Go实现:
func bubblesort (nums []int) {
var (
n int // length of []int
flag bool // the flag of data exchange
temp int
)
n = len(nums)
for i:=0; i<n; i++ {
flag = false
for j := 0; j < n-i-1; j++ {
if nums[j+1] < value {
temp = nums[j]
nums[j] = nums[j+1]
nums[j+1] = temp
flag = true
}
}
if !flag break
}
}
四、插入排序(Insertion Sort)
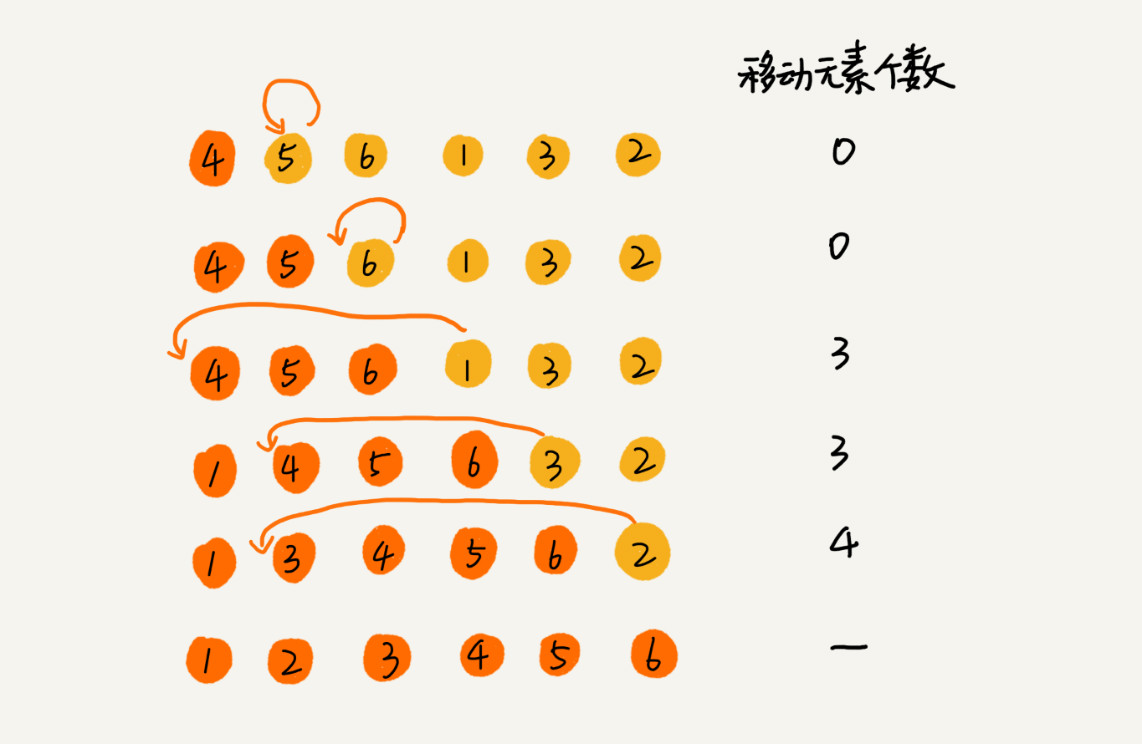
我们将数组中的数据分为两个区间,已排序区间和未排序区间。初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束。

插入排序移动元素的次数跟冒泡的计算方法一致。
上例 有序度为5, 移动次数为10次。
Go实现:
func InsertionSort(n []int) {
for i:=1; i<len(n); i++ {
value := n[i]
j := i-1
for ; j>=0; j++ {
if n[j] > value {
n[j+1] = n[j]
} else {
break
}
}
n[j+1] = value
}
}
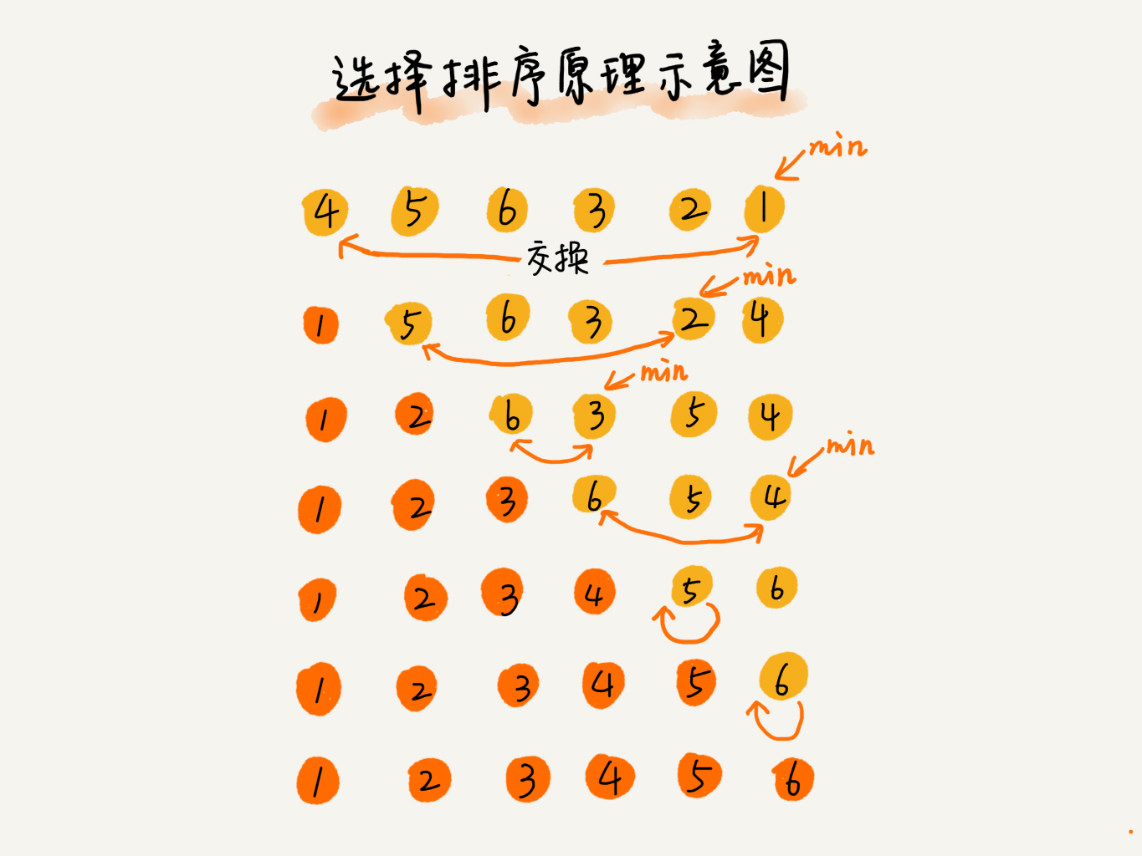
五、选择排序(Selection Sort)
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
Go 实现:
func SelectSort(n []int) {
for i := 0; i < len(n); i++ {
j := len(n) - 1
min := n[j]
x := j
for ; j >= i; j-- {
if n[j] < min {
min = n[j]
x = j
}
}
temp := n[i]
n[i] = n[x]
n[x] = temp
}
}
六、 冒泡 VS 插入
冒泡排序和插入排序的时间复杂度都是 O(n^2),都是原地排序算法,为什么插入排序要比冒泡排序更受欢迎呢?
冒泡排序不管怎么优化,元素交换的次数是一个固定值,是原始数据的逆序度。插入排序是同样的,不管怎么优化,元素移动的次数也等于原始数据的逆序度。
从代码实现上来看:
// 冒泡排序中数据的交换操作:
if (a[j] > a[j+1]) { // 交换
int tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
flag = true;
}
// 插入排序中数据的移动操作:
if (a[j] > value) {
a[j+1] = a[j]; // 数据移动
} else {
break;
}
冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要 3 个赋值操作,而插入排序只需要 1 个。
