
python基--re模块的使用
正则表达式:
正则表达式本身是一种小型的、高度专业化的编程语言,然而在python中,通过内嵌集成re模块让调用者们可以直接调用来实现正则匹配。正则表达模式被变异成一系列的字节码,然后由C语言编写的
匹配引擎执行。
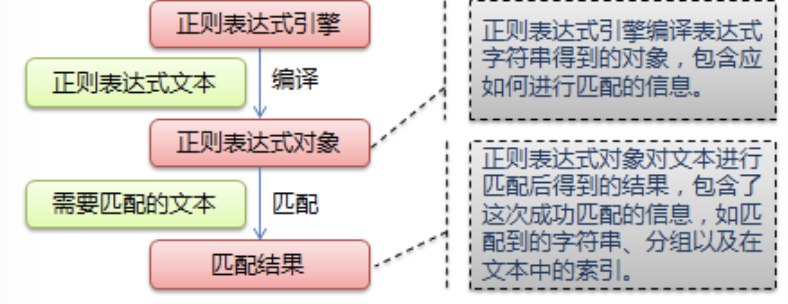
正则表达式是用来匹配处理字符串的,在python中使用正则表达式时需要引入re模块


# 纯python代码校验 while True: phone_number = input('please input your phone number : ') if len(phone_number) == 11 \ and phone_number.isdigit()\ and (phone_number.startswith('13') \ or phone_number.startswith('14') \ or phone_number.startswith('15') \ or phone_number.startswith('18')): print('是合法的手机号码') else: print('不是合法的手机号码') # 正则表达式校验 import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|18)[0-9]{9}$',phone_number): print('是合法的手机号码') else: print('不是合法的手机号码') # 正则在所有语言中都可以使用 不是python独有的 # 匹配大段文本中特定的字符
正则表达式在线测试:
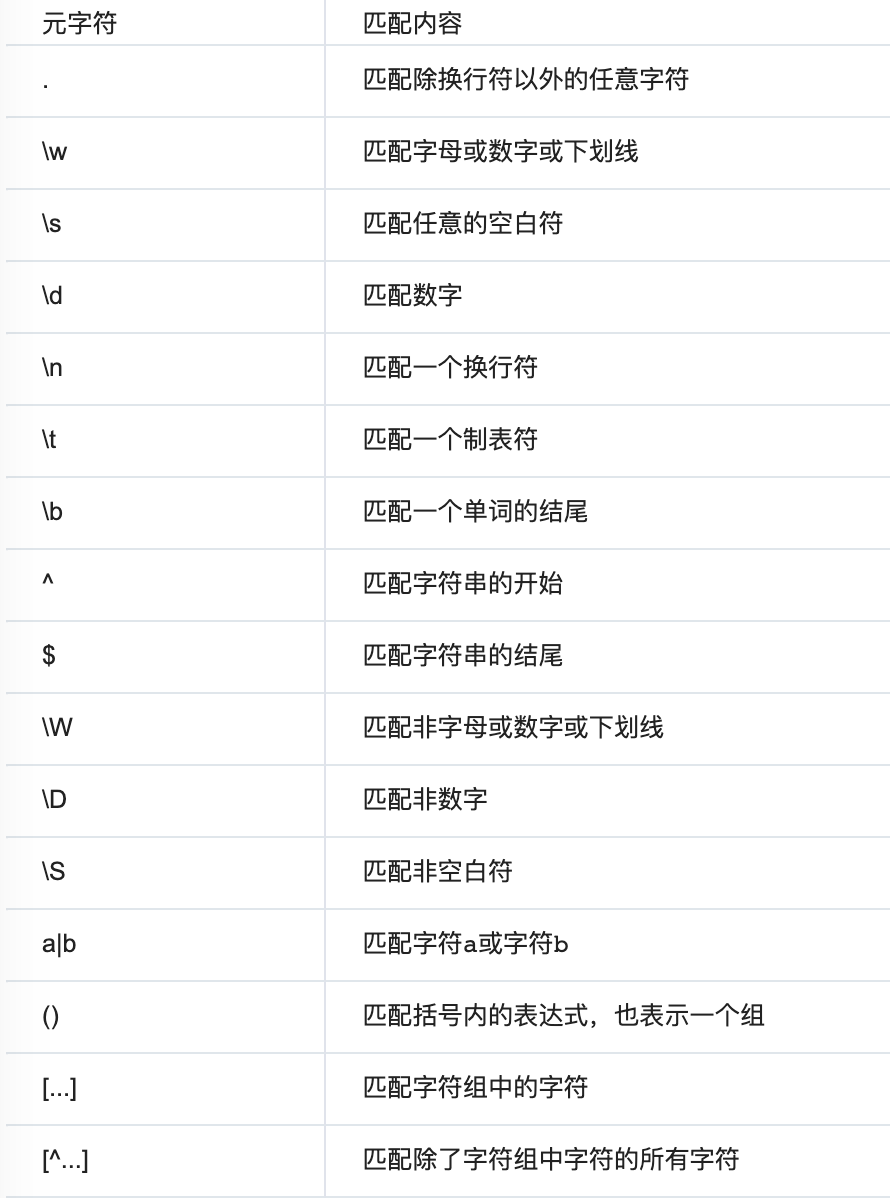
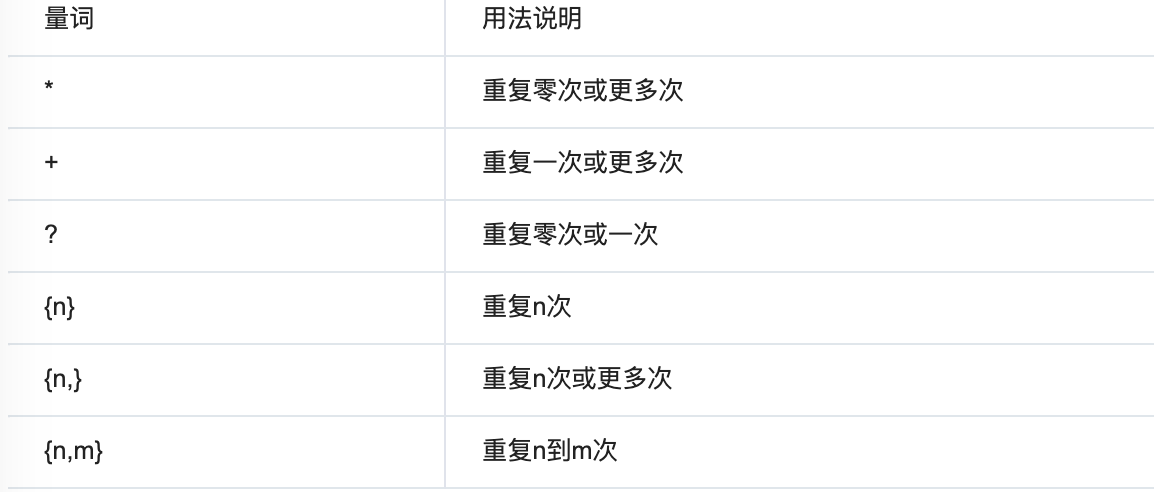
贪婪匹配:
再满足匹配条件时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配。
常用的非贪婪匹配pattern:
*?:重复任意次,但尽可能少重复
+?:重复1次或更多次,但尽可能少重复
??:重复0次或1次,但尽可能少重复
{n,m}?:重复n到m次,但尽可能少重复
{n,}?:重复n次以上,但尽可能少重复
.*?的用法:
. 是任意字符
* 是取0至无限长度
?:是非贪婪模式
合在一起就是,取尽量少的任意字符,一般都不会这么单独写。
re模块中常用的方法:
import re ret = re.findall('a', 'william john lisa') # 返回所有满足匹配条件的结果,放在列表里 print(ret) #结果 : ['a', 'a'] ret = re.search('a', 'william john lisa').group() print(ret) #结果 : 'a' # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配 print(ret) #结果 : 'a' # --------------------------------------------------------------------------------- ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] ret = re.sub('\d', 'H', 'william1john2lisa3', 1)#将数字替换成'H',参数1表示只替换1个 print(ret) #evaHegon4yuan4 ret = re.subn('\d', 'H', 'william1john2lisa3')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 import re ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果
注意:
1、findall的优先级查询:
import re ret = re.findall('www.(baidu|taobao).com', 'www.taobao.com') print(ret) # ['taobao'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|taobao).com', 'www.taobao.com') print(ret) # ['www.taobao.com']
ret=re.split("\d+","william1john2lisa3") print(ret) #结果 : ['william', 'john', 'lisa'] ret=re.split("(\d+)","william1john2lisa3") print(ret) #结果 : ['william', '3', 'john', '4', 'lisa'] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
爬虫练习:
import requests import re # 获取网页源代码 def get_html_content(url): return requests.get(url).text # 解析获取的源代码,提取有用的内容 def parse_html(html_con): # 正则进行解析 r = re.compile(r'<p class="name"><.*?>(?P<title>.*?)</a></p>' + '.*?<p.*?>(?P<actor>.*?)</p>' + '.*?<a href="(?P<url>.*?)" title=".*?>', re.S) obj = r.finditer(html_con) for i in obj: info = { 'title': i.group('title'), 'actor': i.group('actor').strip(), 'movie_url': 'https://maoyan.com' + i.group('url') } yield info def main(nums): url = 'https://maoyan.com/board/4?offset=%s' % nums get_html = get_html_content(url) for i in parse_html(get_html): print(i) if __name__ == '__main__': for i in range(0, 101, 10): main(i)

