python 多线程、线程池及队列的基础使用(Thread ThreadPoolExecutor Queue)
本文链接:https://www.cnblogs.com/tujia/p/13565799.html
背景:单线程处理任务是阻塞式,一个一个任务处理的,在处理大量任务的时候,消耗时间长;同时如果服务器配置还不错的话,光跑一个单线程的话,也有点浪费了配置了
多线程:多线程是异步、并发的,可以大大提高程序的IO处理速度,更好的利用系统资源,更快完成任务
Talk is cheap. Show me the code。下面就直接上代码了~
一、简单多线程
# 简单多线程 # 解释: # 1)一个工人只做一个任务,做完就撤了; # 2)有多少个任务就得有多少个工人; # 3)这个方式处理任务需要快,但人员成本开销高。 # @see https://docs.python.org/zh-cn/3/library/threading.html?highlight=threading#threading.Thread import threading # 任务 def task(taskId): thread_name = threading.current_thread().getName() print('工人【%s】正在处理任务【%d】:do something...' % (thread_name, taskId)) def main(): threads = [] # 这里弄5个线程(一个线程相当于一个工人) for i in range(5): # target 参数指定线程要处理的任务函数,args 参数传递参数到任务函数去 t = threading.Thread(target=task, args=(i+1,)) # 启动线程 t.start() threads.append(t) # 阻塞线程 for t in threads: t.join() if __name__ == '__main__': main()
执行结果:
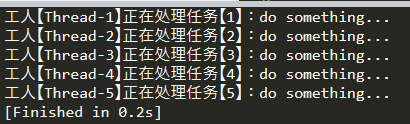
二、线程池
正如上面注释里说的,线程虽好,但太多线程的话,资源(cpu、内存等)的消耗也挺大的;而且线程都是处理完一个任务就“死”掉了,不能复用,有点浪费
于是,这个“线程池”这个东西出现了。线程池就是管理线程的池子,池子如果设置容量,控制好线程的数量,也就控制好了资源的消耗~
# 线程池 # 解释: # 1)一个工人同一时间只做一个任务,但做完一个任务可以接着做下一个任务; # 2)可以分配多个任务给少量工人,减少人员成本开销。 # @see https://docs.python.org/zh-cn/3/library/concurrent.futures.html import threading from concurrent.futures import ThreadPoolExecutor # 任务 def task(taskId): thread_name = threading.current_thread().getName() print('工人【%s】正在处理任务【%d】:do something...' % (thread_name, taskId)) def main(): # 初始化线程池(商会),定义好池里最多有几个工人 pool = ThreadPoolExecutor(max_workers=5, thread_name_prefix='Thread') # 准备10个任务 for i in range(10): # 提交任务到池子(商会)里(它会自动分配给工人) pool.submit(task, i+1) if __name__ == '__main__': main()
注:这里把线程池比喻成了“商会”,线程比喻成“工人”,方便大家理解。
执行结果:
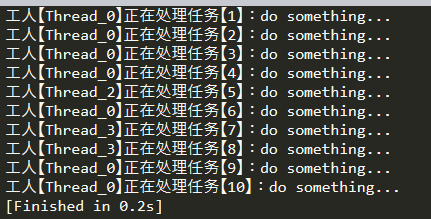
注:从上图可以看到线程被复用了,而且 Thread_0 被复用了最多次,而 Thread_4 毫无用武之地,没有使用到(你可以把任务数量调大,看看结果又会是怎么样?)
三、线程池2
这里的示例和上面是一样的,只是加了一点代码来模拟任务耗时,方便大家观察线程池是怎么分配任务的
# 线程池 # 解释: # 1)一个工人同一时间只做一个任务,但做完一个任务可以接着做下一个任务; # 2)可以分配多个任务给少量工人,减少人员成本开销。 # 3)任务按顺序分配给空闲工人,但每个任务的耗时不一样,任务不是按顺序被完成的,后提交的任务可能会先被完成 import time import random import threading from concurrent.futures import ThreadPoolExecutor # 任务 def task(taskId, consuming): thread_name = threading.current_thread().getName() print('工人【%s】正在处理任务【%d】:do something...' % (thread_name, taskId)) # 模拟任务耗时(秒) time.sleep(consuming) print('任务【%d】:done' % taskId) def main(): # 5个工人 pool = ThreadPoolExecutor(max_workers=5, thread_name_prefix='Thread') # 准备10个任务 for i in range(10): # 模拟任务耗时(秒) consuming = random.randint(1, 5) pool.submit(task, i+1, consuming) if __name__ == '__main__': main()
执行结果:
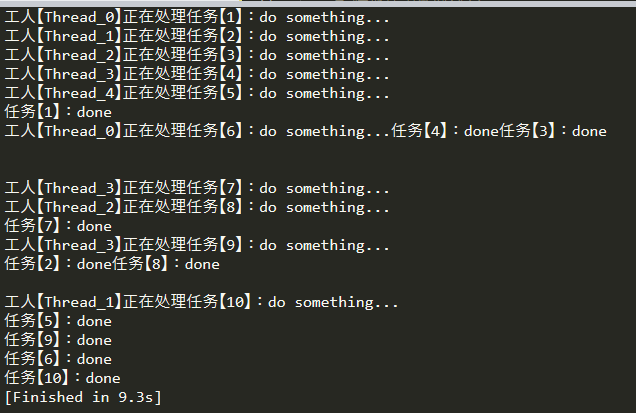
注:看执行结果来看,不难发现:多线程是异步的,且会并发
三、队列
除了使用线程池,我们还可以使用队列来处理任务。任务排好队,工人(线程)按顺序不断从队列里取任务,处理任务~
# 线程队列 # 解释: # 1)一个队列有N个工人在排队,按队列排序给他们分配任务; # 2)做得再快,也要按排队排序来接任务,不能插队抢任务。 # @see https://docs.python.org/zh-cn/3/library/queue.html#queue-objects import time import random import threading from queue import Queue # 自定义线程 class CustomThread(threading.Thread): def __init__(self, queue, **kwargs): super(CustomThread, self).__init__(**kwargs) self.__queue = queue def run(self): while True: # (工人)获取任务 item = self.__queue.get() # 执行任务 item[0](*item[1:]) # 告诉队列,任务已完成 self.__queue.task_done() # 任务 def task(taskId, consuming): thread_name = threading.current_thread().getName() print('工人【%s】正在处理任务【%d】:do something...' % (thread_name, taskId)) # 模拟任务耗时(秒) time.sleep(consuming) print('任务【%d】:done' % taskId) def main(): q = Queue() # 招工,这里招了5个工人(启动5个线程)
for i in range(5): t = CustomThread(q, daemon=True) # 工人已经准备好接活了 t.start() # 来活了(往队列里塞任务) for i in range(10): taskId = i + 1 # 模拟任务耗时(秒) consuming = random.randint(1, 5) q.put((task, taskId, consuming)) # 阻塞队列 q.join() if __name__ == '__main__': main()
执行结果:
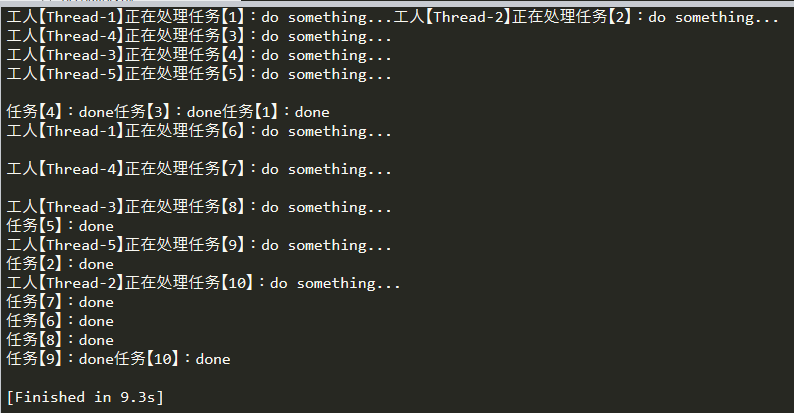
注1:这里用了一个自定义线程类,具体可以看这里:https://docs.python.org/zh-cn/3/library/queue.html#queue-objects
注2:简单来说,就是先招固定的N个工人(创建N个线程),让它们盯着任务队列;然后往队列里塞任务;事先盯着队列的工人们发现有任务,就开始接任务、处理任务了
注3:while True 的意思是循环(不断)地从任务队列里取任务,如果不用 while True的话,线程处理完一个任务就会结束,无法复用,任务也无法全部处理完
注4:这里的线程不能使用 Tread.join 方法,join(阻塞线程)方法会和 while True 冲突,使线程无法结束,一直阻塞着
注5:while True 最后是如何自动结束掉的,目前我还不太了解。希望知道原理的大大能告诉我一下~
本文链接:https://www.cnblogs.com/tujia/p/13565799.html
完。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号