前缀树
1.简介
字典树也称为前缀树、单词查找树。其基本性质如下:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符
- 从根节点到某一结点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同
其结构如下图所示:

通过其结构可以得知,其搜索一个单词的时间复杂度为 \(O(n)\),其中 n 表示串的长度。
应用场景:串的快速检索、串排序、前缀搜索等。
算法核心:利用字符串的公共前缀来减少查询时间,最大限度的减少无谓的字符串比较。
2.代码实现
2.1 节点设计
通常会在字典树中的每个节点上添加一个 isend 标志,用以表示从根节点到当前节点的所有字母组成的是否是一个完整的单词。但是如果需要查看该单词的频率,这个标志就无法查看。因此,可以在每个节点上添加一个变量 freqs ,一方面有着和 isend 同样的功效,另一方面还可以用以表示从根节点到当前节点所组成的单词出现的频率。
此外,由于字典树是一种多叉树的结构,因此可以通过 map 数据结构来存储节点字符和其子节点之间的映射关系,为了在遍历字典树时能够根据字母大小顺序进行遍历,所以这里采用了 map 结构,而非 unordered_map。
综上所述,节点的设计如下所示:
struct TrieNode { TrieNode(char ch, int freqs) : ch_(ch) , freqs_(freqs) { } char ch_; // 节点存储的字符 int freqs_; // 单词出现的频率 // 存储孩子节点字符数据和节点指针的映射关系 map<char, TrieNode*> nodeMap_; };
2.2 添加单词
当需要添加一个单词时,应该遍历该单词的所有字符,然后在字典树从根节点开始往下查找,如果某个字符不在字典树上,那么就创建新的节点插入到该字典树中,否则说明该单词已经存在于该字典树上,那么此时就应该将最后一个字符的 freqs_ 字段加一,用以表示该单词又出现了一次。
其代码实现如下:
void TrieTree::add(const string& word) { TrieNode* cur = root_; for (int i = 0; i < word.size(); i++) { auto childIter = cur->nodeMap_.find(word[i]); if (childIter == cur->nodeMap_.end()) { // 相应字符的节点不存在 创建之 TrieNode* child = new TrieNode(word[i], 0); cur->nodeMap_.emplace(word[i], child); cur = child; } else { // 相应节点已经存在 cur = childIter->second; } } // 此时cur指向该单词的最后一个节点 cur->freqs_++; }
2.3 查询单词
当查询某个单词是否位于字典树上时,同样的,从根节点开始往下搜索目标单词的每个字符,如果某个字符不存在,则说明该单词不在字典树上,否则,说明该单词存在,当搜索到该单词最后一个字符时,返回该节点的 freqs_ 字段即可,用以表示该单词出现的频次。
其代码实现如下:
int TrieTree::query(const string& word) { TrieNode* cur = root_; for (int i = 0; i < word.size(); ++i) { auto iter = cur->nodeMap_.find(word[i]); if (iter == cur->nodeMap_.end()) { return 0; } cur = iter->second; } return cur->freqs_; }
2.4 获取所有单词
当需要获取字典树上的所有单词时,可以通过【前序遍历】的方式来遍历整颗字典树。首先应该访问当前节点的值,如果其 freqs_ 字段大于 0,则表示目前所记录的所有字符已经组成了一个完整的单词,将其存储下来。然后,就需要从左往右不断递归访问其所有的子节点即可,由于存储映射关系时采用的是 map 类型的结构,因此访问时也会按照 ASCII 的顺序从小到大进行访问。
其代码实现如下:
vector<string> TrieTree::allWords() { vector<string> res; preOrder(root_, res, ""); return res; } void TrieTree::preOrder(TrieNode* node, vector<string>& vec, string word) { if (node != root_) { word.push_back(node->ch_); if (node->freqs_ > 0) { // 已经遍历到一个有效的单词 vec.emplace_back(word); } } // 递归处理孩子节点 for (auto pair : node->nodeMap_) { preOrder(pair.second, vec, word); } }
2.4 前缀搜索
当需要进行前缀搜索时,首先应该遍历前缀单词的每一个字符,如果某个字符不存在,则表示没有以该单词为前缀的单词存在于字典树上,否则则会找到最后一个字符为止,此时以该节点为根节点,以【前序遍历】的方式遍历其所有的子节点,就可以得到最终的搜索结果,其过程如下图所示:
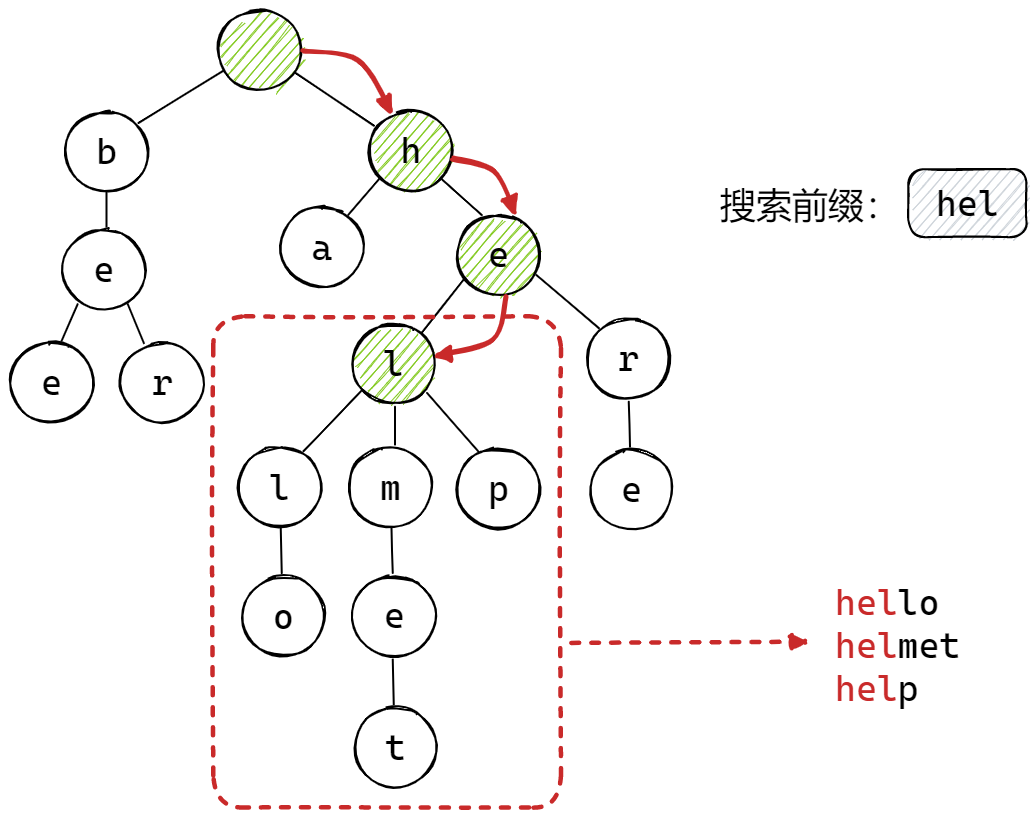
其代码实现如下:
vector<string> TrieTree::queryPrefix(const string& prefix) { TrieNode* cur = root_; for (int i = 0; i < prefix.size(); ++i) { auto iter = cur->nodeMap_.find(prefix[i]); if (iter == cur->nodeMap_.end()) { return {}; } cur = iter->second; } // 此时cur指向前缀的最后一个字符 vector<string> res; preOrder(cur, res, prefix.substr(0, prefix.size() - 1)); return res; }
2.5 删除单词
如果要删除的单词已经存在于该字典树上,那么此时删除该单词时会存在如下两种情况:
- 所删除单词的最后一个字符还有子节点,说明该条路径还有其他单词;
- 所删除单词中的某个字符还有其它子节点,说明某个前缀还有其他单词;
第一种情况如下图所示,当删除单词 "he" 时,该路径下还存在其它单词:"hello"、"helmet"、"help"、"here",此时不能直接删除单词 "he",而是将该单词的最后一个字符,即字符 "e" 的 freq_ 字段置为 0 即可。
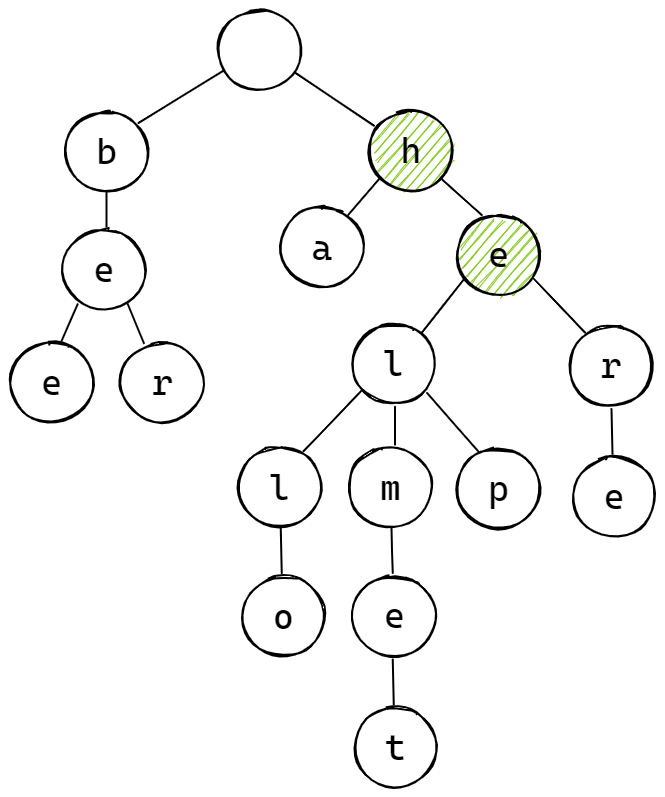
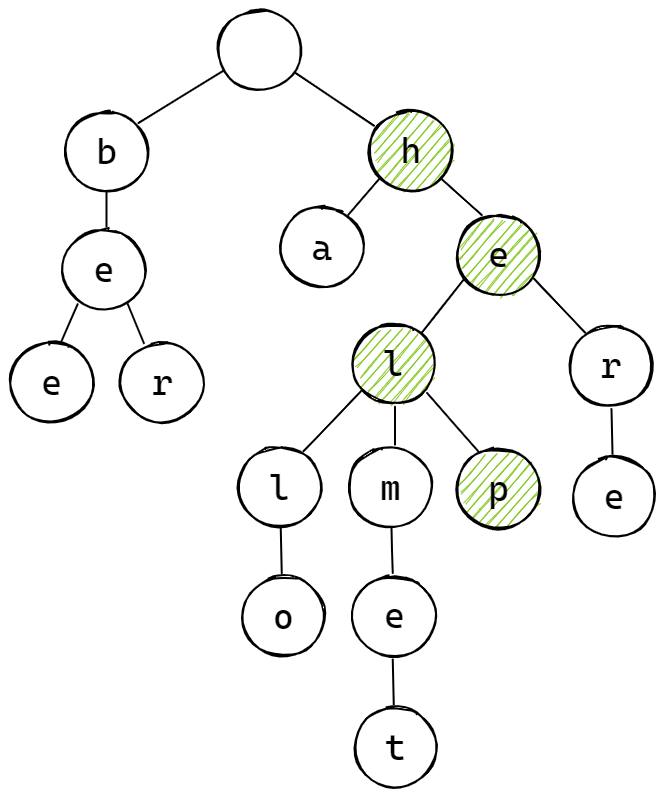
第二种情况如下图所示,当删除单词 "help" 时,以 "hel" 为前缀的单词还有 "hello"、"helmet",以 "he" 为前缀的单词还有 "here"、"he",此时,应该在找寻目标单词的过程中不断判断当前字符的 freqs_ 字段,此时会有如下两种情况:
- 某个单词的最后一个字符的
freqs_字段大于 0,例如图中的 "he"; - 某个单词的最后一个字符的
nodeMap_字段不为空,例如图中的 "l" 节点;
此时,应该不断记录此种类型的节点,当所要删除的目标单词遍历到最后一个字符时,将该节点的子节点进行删除。
其代码实现如下:
void TrieTree::remove(const string& word) { TrieNode *cur = root_, *del = root_; char delch = word[0]; for (int i = 0; i < word.size(); ++i) { auto iter = cur->nodeMap_.find(word[i]); if (iter == cur->nodeMap_.end()) { return; } // 遇到了另一个比较短的单词 if (cur->freqs_ > 0 || cur->nodeMap_.size() > 1) { del = cur; delch = word[i]; } cur = iter->second; } // word单词存在 if (cur->nodeMap_.empty()) { TrieNode* child = del->nodeMap_[delch]; del->nodeMap_.erase(delch); destory(child); } else { // 当前删除节点之后还存在其它字符 不能直接删除 cur->freqs_ = 0; } }
本文作者:Leaos
本文链接:https://www.cnblogs.com/tuilk/p/17121083.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步