
浅谈NodeJS多进程服务架构基本原理
2019-07-05 22:28 龙恩0707 阅读(6244) 评论(2) 编辑 收藏 举报阅读目录
一:nodejs进程进化及多进程架构原理
NodeJS是基于chrome浏览器的V8引擎构建的,它是单线程单进程模式,nodeJS的单线程指js的引擎只有一个实列。且是在主线程执行的,这样的
优点是:可以减少线程间切换的开销。并且不用考虑锁和线程池的问题。
那么nodejs是单线程吗?如果严格的来讲,node存在着多种线程。比如包括:js引擎执行的线程、定时器线程、异步http线程等等这样的。
nodejs是在主线程执行的,其他的异步IO和事件驱动相关的线程是通过libuv来实现内部的线程池和线程调度的。libuv存在着一个Event Loop,通过 Event Loop(事件循环)来切换实现类似多线程的效果。Event Loop 是维持一个执行栈和一个事件队列,在执行栈中,如果有异步IO及定时器等函数的话,就把这些异步回调函数放入到事件队列中。等执行栈执行完成后,会从事件队列中,按照一定的顺序执行事件队列中的异步回调函数。
nodeJS中的单线程是指js引擎只在唯一的主线程上运行的。其他的异步操作是有独立的线程去执行。通过libuv的Event Loop实现了类似多线程的上下文切换以及线程池的调度。线程是最小的进程,因此node也是单进程的。
理解服务器进程进化
1. 同步单进程服务器
该服务器是最早出现的,执行模型是同步的。它的服务模式是一次只能处理一个请求。其他的请求需要按照顺序依次等待处理执行。也就是说如果当前的请求正在处理的话,那么其他的请求都处于阻塞等待的状态。因此这样的服务器处理速度是不好的。
2. 同步多进程服务器
为了解决上面同步单进程服务器无法处理并发的问题,我们就出来一个同步多进程服务器,它的功能是一个请求需要一个进程来服务,也就是说如果有100个请求就需要100个进程来进行服务。那么这样就会有很大进程的开销问题了。并且相同的状态在内存中会有多种,这样就会造成资源浪费。
3. 同步多进程多线程服务器
为了解决上面多进程中资源浪费的问题,我们就引入了多进程多线程服务器模式,从我们之前一个进程处理一个请求,现在我们改成为一个线程来处理一个请求,线程相对于进程来说开销会少很多,并且线程之间还可以共享数据。并且我们还可以使用线程池来减少创建和销毁线程的开销。
但是多线程也有缺点,比如多个请求需要使用多个线程来服务,但是每个线程需要一定的内存来存放自己的堆和栈的。这样就会导致占用太多的内存。第二就是:CPU核心只能处理一件事情,系统是通过将CPU切分为时间片的方法来让线程可以均匀地使用CPU的资源的。在系统切换线程的过程中也会进行线程上下文切换,当线程数量过多时进行上下文切换会非常耗费时间的。因此在很大的并发量下,多线程还是无法做到很好的伸缩性。Apache服务器就是这样架构的。
4. 单进程单线程基于事件驱动的服务器
为了解决上面的问题,我们出现了单进程单线程基于事件驱动的模式出现了,使用单线程的优点是:避免内存开销和上下文切换的开销。
所有的请求都在单线程上执行的,其他的异步IO和事件驱动相关的线程是通过libuv中的事件循环来实现内部的线程池和线程调度的。可伸缩性比之前的都好,但是影响事件驱动服务模型性能的只有CPU的计算能力,但是只能使用单核的CPU来处理事件驱动,但是我们的计算机目前都是多核的,我们要如何使用多核CPU呢?如果我们使用多核CPU的话,那么CPU的计算能力就会得到一个很大的提升。
5. NodeJS的实现多进程架构
如上第四点,面对单线程单进程对多核使用率不好的问题,因此我们使用多进程,每个进程使用一个cpu,因此我们就可以实现多核cpu的利用。
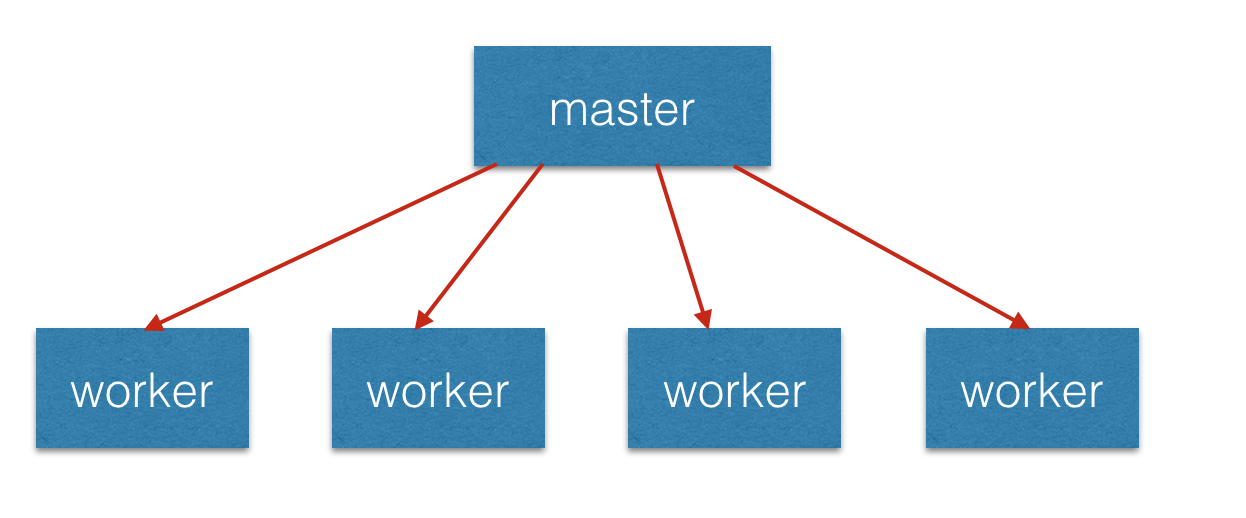
Node提供了child_process模块和cluster模块来实现多进程以及进程的管理。也就是我们常说的 Master-Worker模式。也就是说进程分为Master(主)进程 和 worker(工作)进程。master进程负责调度或管理worker进程,那么worker进程负责具体的业务处理。在服务器层面来讲,worker可以是一个服务进程,负责出来自于客户端的请求,多个worker就相当于多个服务器,因此就构成了一个服务器群。master进程则负责创建worker,接收客户端的请求,然后分配到各个服务器上去处理,并且监控worker进程的运行状态及进行管理操作。
如下图所示:
二:node中child_process模块实现多进程
nodejs 是单进程的,因此无法使用多核cpu,node提供了child_process模块来实现子进程。从而会实现一个广义上的多进程模式,通过child_process模块,可以实现一个主进程,多个子进程模式,主进程叫做master进程,子进程叫做worker(工作)进程,在子进程中不仅可以调用其他node程序,我们还可以调用非node程序及shell命令等。执行完子进程后,我们可以以流或回调形式返回给主进程。
child_process提供了4个方法,用于创建子进程,这四个方法分别为 spawn, execFile, exec 和 fork. 所有的方法都是异步的。
该如上4个方法的区别是什么?
spawn: 子进程中执行的是非node程序,提供一组参数后,执行的结果以流的形式返回。
execFile: 子进程中执行的是非node程序, 提供一组参数后,执行的结果以回调的形式返回。
exec: 子进程执行的是非node程序,提供一串shell命令,执行结果后以回调的形式返回,它与 execFile不同的是,exec可以直接执行一串
shell命令。
fork: 子进程执行的是node程序,提供一组参数后,执行的结果以流的形式返回,它与spawn不同的是,fork生成的子进程只能执行node应用。
2.1 execFile 和 exec
该两个方法的相同点和不同点如下:
相同点:执行的都是非node应用,且执行的结果以回调函数的形式返回。
不同点:execFile执行的是一个应用,exec执行的是一段shell命令。
比如来说:echo是Unix系统的一个自带命令,我们可以直接在命令行中执行如下命令:
echo hello world
如下所示:
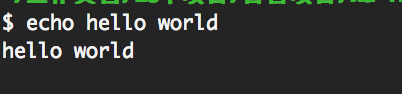
如上可以看到,我们在命令行中会打印 hello world. 因此这个我们可以使用 exec 来实现。
1)通过exec来实现:
exec执行shell命令代码如下:
const cp = require('child_process');
console.log(cp);
cp.exec('echo hello world', function(err, res) {
console.log(res);
});
执行如下图所示:
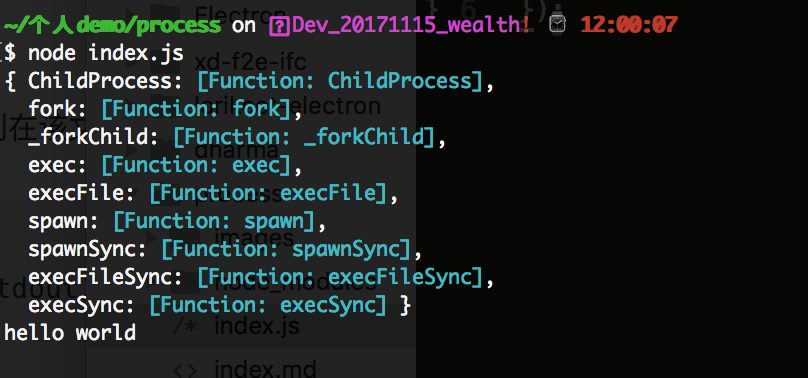
如上我们可以看到,我们的 child_process模块有如下属性:
{ ChildProcess: [Function: ChildProcess],
fork: [Function: fork],
_forkChild: [Function: _forkChild],
exec: [Function: exec],
execFile: [Function: execFile],
spawn: [Function: spawn],
spawnSync: [Function: spawnSync],
execFileSync: [Function: execFileSync],
execSync: [Function: execSync] }
执行如上exec命令后,结果输出为 hello world.
2) 通过execFile实现
const cp = require('child_process');
cp.execFile('echo', ['hello', 'world'], function(err, res) {
console.log(res);
});
如上结果也是为 "hello world".
2.2 spawn
spawn是用于执行非node应用的,并且是不能直接执行shell。spawn执行的结果是以流的形式输出的,通过流的方式可以节约内存的。
2.3 fork
在node中提供了fork方法,通过使用fork方法在单独的进程中执行node程序,通过使用fork新建worker进程,上下文都复制主进程。并且通过父子之间的通信,子进程接收父进程的信息,并执行子进程后结果信息返回给父进程。降低了大数据运行的压力。
现在我们来理解下使用fork()方法来创建子进程,fork()方法只需要指定要执行的javascript文件模块,即可创建Node的子进程。下面我们是简单的hello world的demo,master进程根据cpu的数量来创建出相应数量的worker进程,worker进程利用进程ID来标记。
|------ 项目 | |--- master.js | |--- worker.js | |--- package.json | |--- node_modules
如上是我们的简单项目结构,其中 worker.js 代码如下:
console.log('Worker-' + process.pid + ': Hello world.');
master.js 代码如下:
const childProcess = require('child_process');
const cpuNum = require('os').cpus().length;
for (let i = 0; i < cpuNum; ++i) {
childProcess.fork('./worker.js');
}
console.log('Master: xxxx');
然后我们进入项目中的根目录,执行 node master.js 命令即可看到打印信息如下:

如上图可以看到,我们的master创建了4个worker进程后输出 hello world信息。如上就是根据cpu的数量创建了4个工作进程。
三:父子进程间如何通信?
如上创建了4个worker进程后,现在我们需要考虑的是如何实现 master进程与worker进程通信的问题。
在NodeJS中父子进程之间通信可以通过 on('message') 和 send()方法来实现通信,on('message') 是监听message事件的。
当该进程收到其他进程发送的消息时候,便会触发message事件。send()方法则是用于向其他进程发送消息的。
具体如何做呢?
master进程中可以调用 child_process的fork()方法后会得到一个子进程的实列,通过该实列我们可以监听到来自子进程的消息或向子进程发送消息。而worker进程则通过process对象接口来监听父进程的消息或向父进程发送消息。现在我们把master.js 代码改成如下:
const childProcess = require('child_process');
const worker = childProcess.fork('./worker.js');
// 主进程向子进程发送消息
worker.send('Hello World');
// 监听子进程发送过来的消息
worker.on('message', (msg) => {
console.log('Received message from worker:' + msg);
});
worker.js 代码如下:
// 接收主进程发来的消息 process.on('message', (msg) => { console.log('Received message from master:' + msg); // 子进程向主进程发送消息 process.send('Hi master.'); });
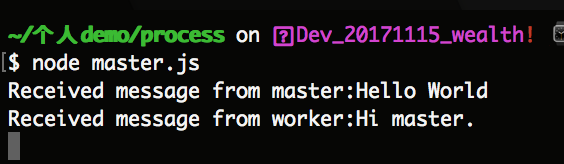
我们继续在命令中执行 node master.js 命令后,看到如下信息被打印了
3.2 Master实现对Worker的请求进行分发
如上只是简单的父进程和子进程进行通信的demo实列,现在我们继续来看一个更复杂一点的demo。我们知道master进程最主要是创建子进程,及对子进程进行管理和分配,而子进程最主要做的事情是处理具体的请求及业务。
进程通信除了使用到上面的send()方法,发送一些普通对象以外,我们还可以发送句柄,什么是句柄呢,句柄是一种引用,可以用来标识资源。
比如通过句柄可以标识一个socket对象等。我们可以利用该句柄实现请求的分发。
现在我们通过master进程来创建一个TCP服务器来监听一些特定的端口,master进程会收到客户端的请求,我们会得到一个socket对象,通过这个socket对象就可以和客户端进行通信,从而我们可以处理客户端的请求。
比如如下demo实列,master创建TCP服务器并且监听8989端口,收到该请求后会将请求分发给worker处理,worker收到master发来的socket以后,通过socket对客户端的响应。
|------ 项目 | |--- master.js | |--- worker.js | |--- tcp_client.js | |--- package.json | |--- node_modules
master.js 代码如下:
const childProcess = require('child_process');
const net = require('net');
// 获取cpu的数量
const cpuNum = require('os').cpus().length;
let workers = [];
let cur = 0;
for (let i = 0; i < cpuNum; ++i) {
workers.push(childProcess.fork('./worker.js'));
console.log('worker process-' + workers[i].pid);
}
// 创建TCP服务器
const tcpServer = net.createServer();
/*
服务器收到请求后分发给工作进程去处理
*/
tcpServer.on('connection', (socket) => {
workers[cur].send('socket', socket);
cur = Number.parseInt((cur + 1) % cpuNum);
});
tcpServer.listen(8989, () => {
console.log('Tcp Server: 127.0.0.8989');
});
worker.js 代码如下:
// 接收主进程发来的消息 process.on('message', (msg, socket) => { if (msg === 'socket' && socket) { // 利用setTimeout 模拟异步请求 setTimeout(() => { socket.end('Request handled by worker-' + process.pid); },100); } });
tcp.client.js 代码如下:
const net = require('net');
const maxConnectCount = 10;
for (let i = 0; i < maxConnectCount; ++i) {
net.createConnection({
port: 8989,
host: '127.0.0.1'
}).on('data', (d) => {
console.log(d.toString());
})
}
如上代码,tcp_client.js 负责创建10个本地请求,master.js 首先根据cpu的数量,创建多个worker进程,然后创建一个tcp服务器,使用connection来监听net中 createConnection 方法创建事件,当有事件来的时候,就使用worker子进程依次进行分发事件,最后我们通过worker.js 来使用 process中message事件对事件进行监听。如果收到消息的话,就打印消息出来,比如如下代码:
// 接收主进程发来的消息 process.on('message', (msg, socket) => { if (msg === 'socket' && socket) { // 利用setTimeout 模拟异步请求 setTimeout(() => { socket.end('Request handled by worker-' + process.pid); },100); } });
为了查看效果,我们可以在项目的根目录下 运行 命令 node master.js 启动服务器,然后我们打开另一个命令行,执行 node tcp_client.js 启动客户端,然后我们会看到我们的10个请求被分发到不同的服务器上进行处理,如下所示:
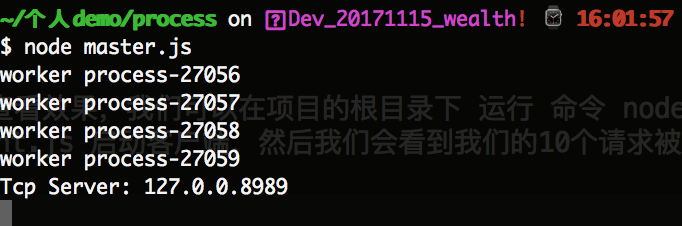

3.3 Worker监听同一个端口
我们之前已经实现了句柄可以发送普通对象及socket对象外,我们还可以通过句柄的方式发送一个server对象。我们在master进程中创建一个TCP服务器,将服务器对象直接发送给worker进程,让worker进程去监听端口并处理请求。因此master进程和worker进程就会监听了相同的端口了。当我们的客户端发送请求时候,我们的master进程和worker进程都可以监听到,我们知道我们的master进程它是不会处理具体的业务的。
因此需要使用worker进程去处理具体的事情了。因此请求都会被worker进程处理了。
那么在这种模式下,主进程和worker进程都可以监听到相同的端口,当网络请求到来的时候,会进行抢占式调度,只有一个worker进程会抢到链接然后进行服务,由于是抢占式调度,可以理解为谁先来谁先处理的模式,因此就不能保证每个worker进程都能负载均衡的问题。下面是一个demo如下:
master.js 代码如下:
const childProcess = require('child_process');
const net = require('net');
// 获取cpu的数量
const cpuNum = require('os').cpus().length;
let workers = [];
let cur = 0;
for (let i = 0; i < cpuNum; ++i) {
workers.push(childProcess.fork('./worker.js'));
console.log('worker process-' + workers[i].pid);
}
// 创建TCP服务器
const tcpServer = net.createServer();
tcpServer.listen(8989, () => {
console.log('Tcp Server: 127.0.0.8989');
// 监听端口后将服务器句柄发送给worker进程
for (let i = 0; i < cpuNum; ++i) {
workers[i].send('tcpServer', tcpServer);
}
// 关闭master线程的端口监听
tcpServer.close();
});
worker.js 代码如下:
// 接收主进程发来的消息 process.on('message', (msg, tcpServer) => { if (msg === 'tcpServer' && tcpServer) { tcpServer.on('connection', (socket) => { setTimeout(() => { socket.end('Request handled by worker-' + process.pid); }, 100); }) } });
tcp_client.js 代码如下:
const net = require('net');
const maxConnectCount = 10;
for (let i = 0; i < maxConnectCount; ++i) {
net.createConnection({
port: 8989,
host: '127.0.0.1'
}).on('data', (d) => {
console.log(d.toString());
})
}
如上代码,我们运行 node master.js 代码后,运行结果如下所示:
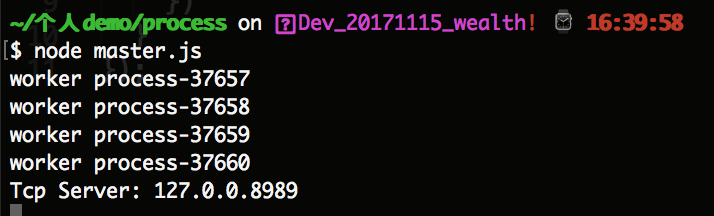
然后我们进行 运行 node tcp_client.js 命令后,运行结果如下所示:
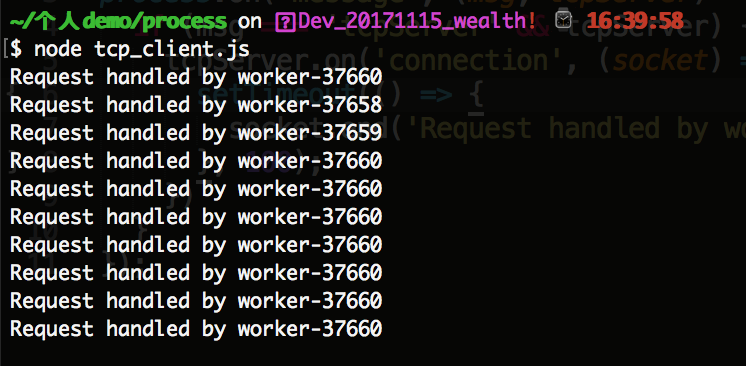
如上我们可以看到 进程id为 37660 调度的比较多。
3.4 实现进程重启
worker进程可能会因为其他的原因导致异常而退出,为了提高集群的稳定性,我们的master进程需要监听每个worker进程的存活状态,当我们的任何一个worker进程退出之后,master进程能监听到并且能够重启新的子进程。在我们的Node中,子进程退出时候,我们可以在父进程中使用exit事件就能监听到。如果触发了该事件,就可以断定为子进程已经退出了,因此我们就可以在该事件内部做出对应的处理,比如说重启子进程等操作。
下面是我们上面监听同一个端口模式下的代码demo,但是我们增加了进程重启的功能。进程重启时,我们的master进程需要重新传递tcpServer对象给新的worker进程。但是master进程是不能被关闭的。否则的话,句柄将为空,无法正常传递。
master.js 代码如下:
const childProcess = require('child_process');
const net = require('net');
// 获取cpu的数量
const cpuNum = require('os').cpus().length;
let workers = [];
let cur = 0;
for (let i = 0; i < cpuNum; ++i) {
workers.push(childProcess.fork('./worker.js'));
console.log('worker process-' + workers[i].pid);
}
// 创建TCP服务器
const tcpServer = net.createServer();
/*
服务器收到请求后分发给工作进程去处理
*/
tcpServer.on('connection', (socket) => {
workers[cur].send('socket', socket);
cur = Number.parseInt((cur + 1) % cpuNum);
});
tcpServer.listen(8989, () => {
console.log('Tcp Server: 127.0.0.8989');
// 监听端口后将服务器句柄发送给worker进程
for (let i = 0; i < cpuNum; ++i) {
workers[i].send('tcpServer', tcpServer);
// 监听工作进程退出事件
workers[i].on('exit', ((i) => {
return () => {
console.log('worker-' + workers[i].pid + ' exited');
workers[i] = childProcess.fork('./worker.js');
console.log('Create worker-' + workers[i].pid);
workers[i].send('tcpServer', tcpServer);
}
})(i));
}
// 不能关闭master线程的,否则的话,句柄将为空,无法正常传递。
// tcpServer.close();
});
worker.js 代码如下:
// 接收主进程发来的消息 process.on('message', (msg, tcpServer) => { if (msg === 'tcpServer' && tcpServer) { tcpServer.on('connection', (socket) => { setTimeout(() => { socket.end('Request handled by worker-' + process.pid); }, 100); }) } });
tcp_client.js 代码如下:
const net = require('net');
const maxConnectCount = 10;
for (let i = 0; i < maxConnectCount; ++i) {
net.createConnection({
port: 8989,
host: '127.0.0.1'
}).on('data', (d) => {
console.log(d.toString());
})
}
当我们在命令中 运行 node master.js 和 node tcp_client.js 执行后,如下图所示:
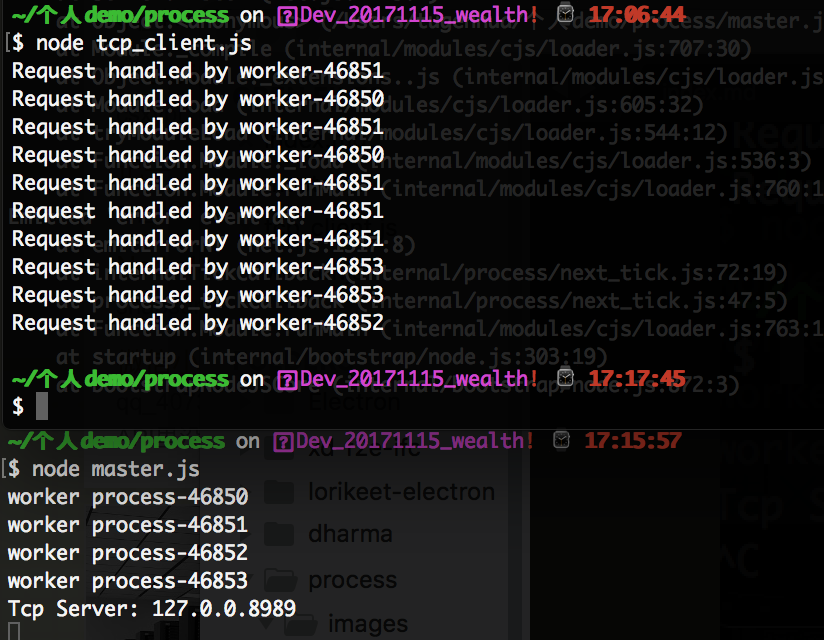
然后我们进入我们的电脑后台(我这边是mac电脑),进入活动监视器页面,结束某一个进程,如下图所示:

结束完成后,我们再来看下我们的 node master.js 命令可以看到,先打印 某某工作进程被退出了,然后某某工作进程被创建了,如下图所示
:
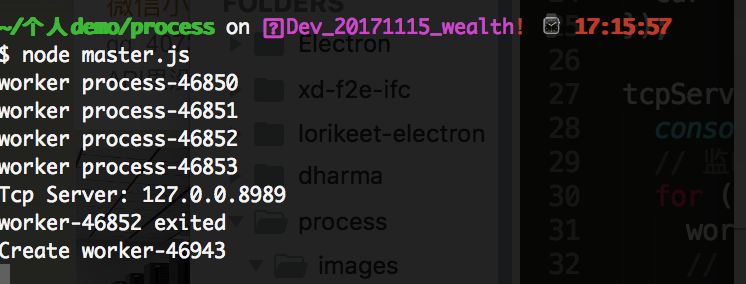
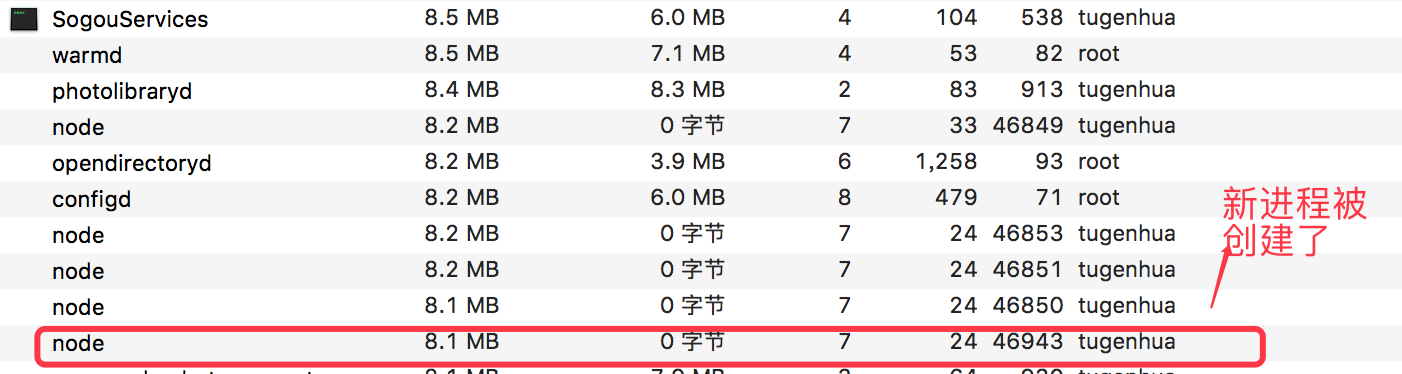
然后我们再到我们的 活动监视器可以看到新的 进程号被加进来了,如下图所示:
四:理解cluster集群
如上我们了解了使用 child_process实现node集群操作,现在我们来学习使用cluster模块实现多进程服务充分利用我们的cpu资源以外,还能够帮我们更好地进行进程管理。我们使用cluster模块来实现我们上面同样的功能,代码如下:
master.js 代码如下:
const cluster = require('cluster');
if (cluster.isMaster) {
const cpuNum = require('os').cpus().length;
for (let i = 0; i < cpuNum; ++i) {
cluster.fork();
}
// 创建进程完成后输出信息
cluster.on('online', (worker) => {
console.log('Create worker-' + worker.process.pid);
});
// 监听子进程退出后重启事件
cluster.on('exit', (worker, code, signal) => {
console.log('[Master] worker ' + worker.process.pid + ' died with code:' + code + ', and' + signal);
cluster.fork(); // 重启子进程
});
} else {
const net = require('net');
net.createServer().on('connection', (socket) => {
setTimeout(() => {
socket.end('Request handled by worker-' + process.pid);
}, 10)
}).listen(8989)
}
如上代码,我们可以使用 cluster.isMaster 来判断是主进程还是子进程,如果是主进程的话,我们使用cluster创建了和cpu数量相同的worker进程,并且通过监听 cluster中的online事件来判断worker是否创建成功。并且使用了 cluster监听了 exit事件,当worker进程退出后,会触发master进程中cluster的online事件来判断worker是否创建成功。如下图我们在命令行中运行命令:
如下所示:
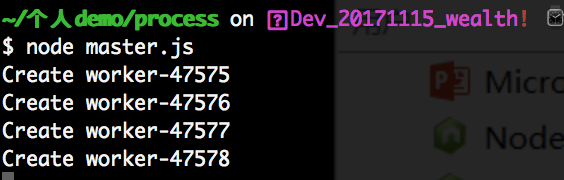
我们现在同样的道理,我们去 活动监视器去吧 47575这个端口号结束掉。在看看我们的命令行如下所示:

从上图我们也可以看到 47575 进程结束掉,并且47898进程重启了。如上代码使用 cluster模块实现了child_process集群的操作。
有关更多的cluster中的API可以看这篇文章(http://wiki.jikexueyuan.com/project/nodejs/cluster.html)
我们在下一篇文章会深入学习使用cluster的应用场景demo。 基本原理先到这里。
注:我也是在看资料学习的。

