
理解nodejs中的stream(流)
2019-05-06 20:09 龙恩0707 阅读(8295) 评论(0) 收藏 举报阅读目录
一:nodeJS中的stream(流)的概念及作用?
什么是流呢?日常生活中有水流,我们很容易想得到的就是水龙头,那么水龙头流出的水是有序且有方向的(从高处往低处流)。我们在nodejs中的流也是一样的,他们也是有序且有方向的。nodejs中的流是可读的、或可写的、或可读可写的。
并且流继承了EventEmitter。因此所有的流都是EventEmitter的实列。
Node.js中有四种基本的流类型,如下:
1. Readable--可读的流(比如 fs.createReadStream()).
2. Writable--可写的流(比如 fs.createWriteStream()).
3. Duplex--可读写的流
4. Transform---在读写过程中可以修改和变换数据的Duplex流。
nodeJS中的流最大的作用是:读取大文件的过程中,不会一次性的读入到内存中。每次只会读取数据源的一个数据块。
然后后续过程中可以立即处理该数据块(数据处理完成后会进入垃圾回收机制)。而不用等待所有的数据。
我们先来看一个简单的流的实列来理解下:
1. 首先我们来创建一个大文件,如下代码:
const fs = require('fs');
const file = fs.createWriteStream('./big.txt');
// 循环500万次
for (let i = 0; i <= 5000000; i++) {
file.write('我是空智,我来测试一个大文件, 你看看我会有多大?');
}
file.end();
我在我项目文件里面新建一个app.js文件,然后把上面的代码放入到 app.js 里面去,可以看到循环了500万次后,写入500万次数据到 big.txt中去,因此会在文件目录下生成一个 big.txt文件,如下: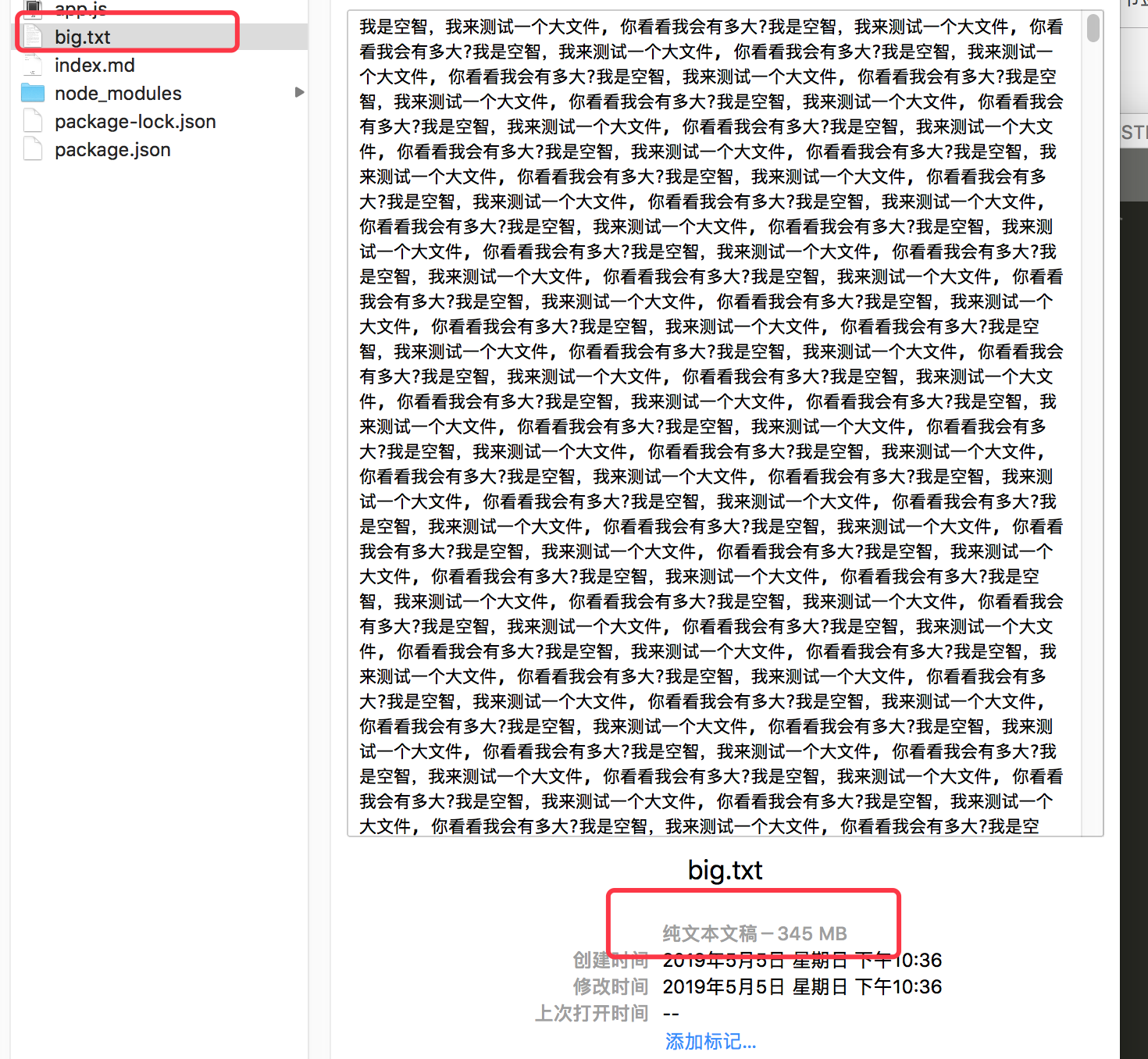
该文件在我磁盘中显示345兆。
readFile读取该文件:
下面我们使用 readFile 来读取该文件看看(readFile会一次性读入到内存中)。
我们把app.js代码改成如下:
const fs = require('fs');
const Koa = require('koa');
const app = new Koa();
app.use(async(ctx, next) => {
const res = ctx.res;
fs.readFile('./big.txt', (err, data) => {
if (err) {
throw err;
} else {
res.end(data);
}
})
});
app.listen(3001, () => {
console.log('listening on 3001');
});
当我们运行node app.js 后,我们查看下该代码占用的内存(12MB)如下:

但是当我们运行 http://localhost:3001/ 后,发现占用的内存(有338MB了)如下:
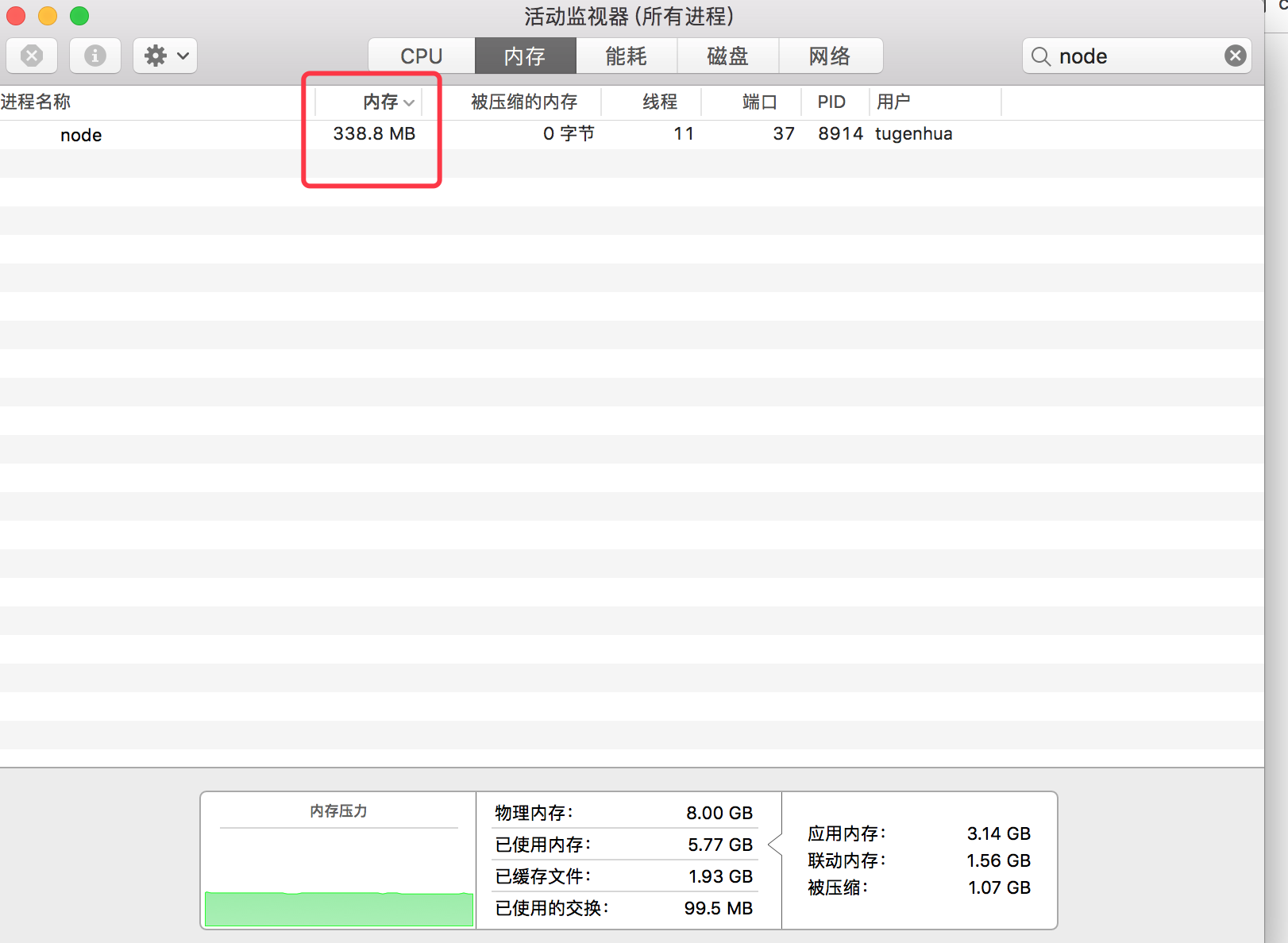
readFile 它会把 big.txt的文件内容整个的读进以Buffer格式存入到内存中,然后再写进返回对象,那么这样的效率非常低的,并且如果该文件如果是1G或2G以上的文件,那么内存会直接被卡死掉的。或者服务器直接会奔溃掉。
下面我们使用 Node中的createReadStream方法就可以避免占用内存多的情况发生。我们把app.js 代码改成如下所示:
const fs = require('fs');
const Koa = require('koa');
const app = new Koa();
app.use(async(ctx, next) => {
const res = ctx.res;
const file = fs.createReadStream('./big.txt');
file.pipe(res);
});
app.listen(3001, () => {
console.log('listening on 3001');
});
然后我们继续查看内存的使用情况,如下所示:
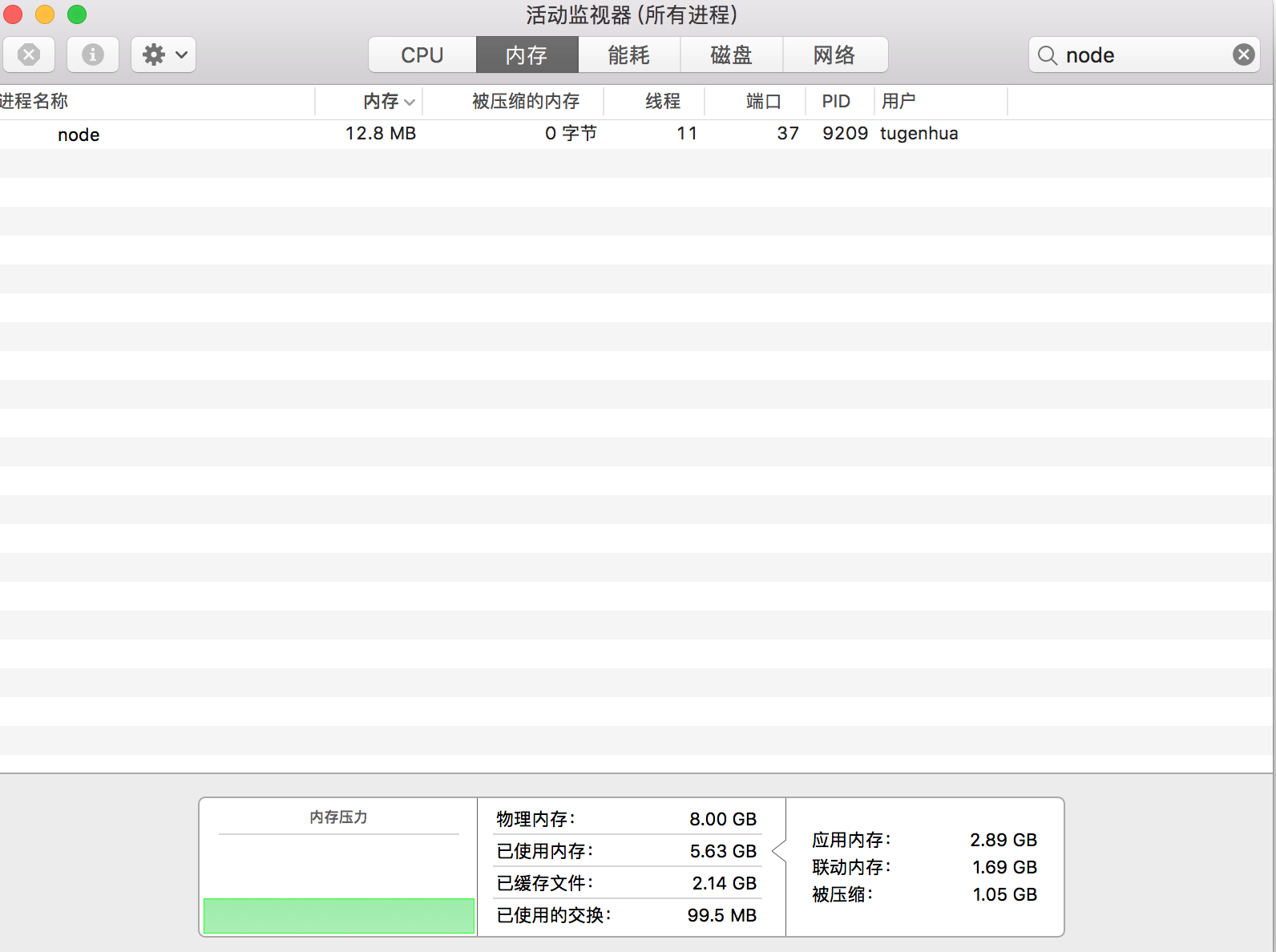
可以看到我们的占用的内存只有12.8兆。也就是说:createReadStream 在读取大文件的过程中,不会一次性的读入到内存中。
每次只会读取数据源的一个数据块。这就是流的优点。下面我们来分别看下流吧。
二:fs.createReadStream() 可读流
其基本使用方法如下:
const fs = require('fs');
const rs = fs.createReadStream('./big.txt', {
flags: 'r', // 文件的操作方式,同readFile中的配置一样,这里默认是可读的是 r
encoding: 'utf-8', // 编码格式
autoClose: true, // 是否关闭读取文件操作系统内部使用的文件描述符
start: 0, // 开始读取的位置
end: 5, // 结束读取的位置
highWaterMark: 1 // 每次读取的个数
});
fs.createReadStream有以下监听事件:
具体有哪些事件可以查看官网(http://nodejs.cn/api/stream.html#stream_class_stream_readable) 这边先截图出来简单看看,如下所示:
有了上面这些监听方法,我们可以先看一个完整的实列,如下代码:
const fs = require('fs');
const file = fs.createReadStream('./msg.txt', {
flags: 'r', // 文件的操作方式,同readFile中的配置一样,这里默认是可读的是 r
encoding: 'utf-8', // 编码格式
autoClose: true, // 是否关闭读取文件操作系统内部使用的文件描述符
start: 0, // 开始读取的位置
end: 5, // 结束读取的位置
highWaterMark: 1 // 每次读取的个数
});
file.on('open', () => {
console.log('开始读取文件');
});
file.on('data', (data) => {
console.log('读取到的数据:');
console.log(data);
});
file.on('end', () => {
console.log('文件全部读取完毕');
});
file.on('close', () => {
console.log('文件被关闭');
});
file.on('error', (err) => {
console.log('读取文件失败');
});
执行如下图所示:
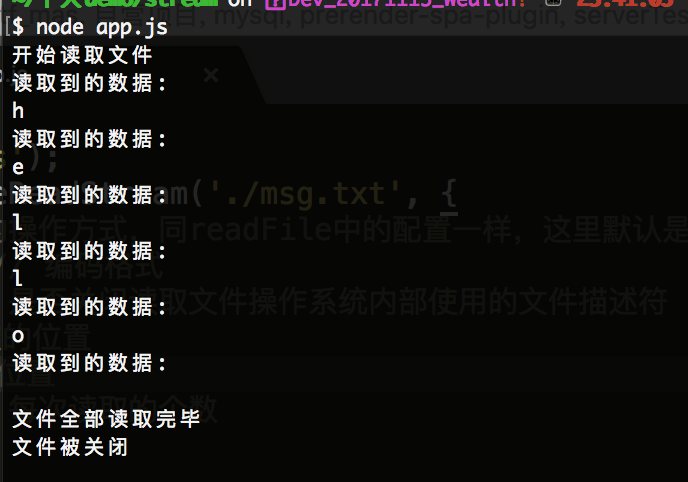
从上图我们可以看到,先打开文件,执行open事件,然后就是不断的触发data事件,等data事情读取结束后会触发end事件,然后会将文件关闭,触发close事件。
注意:msg.txt文件内容如下:hello world; 但是上面为什么只读了 hello了,那是因为我们上面限制了从开始读取位置读取,然后到结束位置结束(5). 并且限定了 highWaterMark: 1,每次读取的个数为1。当然如果我们改成每次读取的个数为2的话,那么每次会读2个字符。
pause() 方法:
如果我们在读取的过程中,想暂停事件的读取,我们可以使用 ReadStream对象的pause方法暂停data事件的触发。 如下代码:
file.on('data', (data) => {
console.log('读取到的数据:');
console.log(data);
file.pause();
});
然后如下图所示:
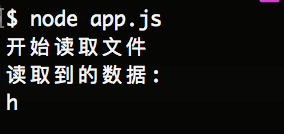
上面暂停了使用 pause()方法,如果我们现在想重新读取,需要使用 resume()方法,如下所示:
setTimeout(() => {
file.resume();
}, 100);
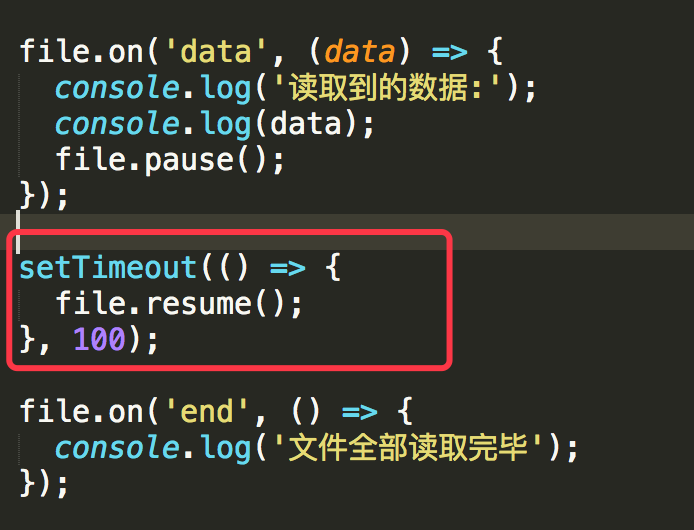
执行结果如下:

其他的一些事件,比如 readable事件等,可以看官方文档 (http://nodejs.cn/api/stream.html#stream_event_readable). 这里就不多分析了。
三:fs.createWriteStream() 可写流
如下代码演示:
const fs = require('fs');
const file = fs.createWriteStream('./1.txt', {
flags: 'w', // 文件的操作方式,同writeFile中的配置一样,这里默认是可读的是 w
encoding: 'utf-8', // 编码格式
autoClose: true, // 是否关闭读取文件操作系统内部使用的文件描述符
start: 0, // 开始读取的位置
highWaterMark: 1 // 每次写入的个数
});
let f1 = file.write('1', 'utf-8', () => {
console.log('写入成功1111');
});
f1 = file.write('2', 'utf-8', () => {
console.log('写入成功2222');
});
f1 = file.write('3', 'utf-8', () => {
console.log('写入成功3333');
});
// 标记文件末尾
file.end();
// 处理事件
file.on('finish', () => {
console.log('写入完成');
});
file.on('error', (err) => {
console.log(err);
});
在我项目的根目录下会生成一个 1.txt文件,里面有123内容。
详细请看官网(http://nodejs.cn/api/fs.html#fs_fs_writefile_file_data_options_callback)
管道流(pipe)
我们需要把我们上面可读流读到的数据需要放到可写流中去写入到文件里面去。我们可以如下操作代码:
const fs = require('fs');
// 读取msg.txt中的字符串 hello world
const msg = fs.createReadStream('./msg.txt', {
highWaterMark: 5
});
// 写入到1.txt中
const f1 = fs.createWriteStream('./1.txt', {
encoding: 'utf-8',
highWaterMark: 1
});
// 监听读取的数据过程,把读取的数据写入到我们的1.txt文件里面去
msg.on('data', (chunk) => {
f1.write(chunk, 'utf-8', () => {
console.log('写入成功');
});
});
但是实现如上的机制,我们可以使用管道机制,管道提供了一个输出流到输入流的机制。通常我们用于从一个流中获取数据并将数据传递到另外一个流中。如下图所示:
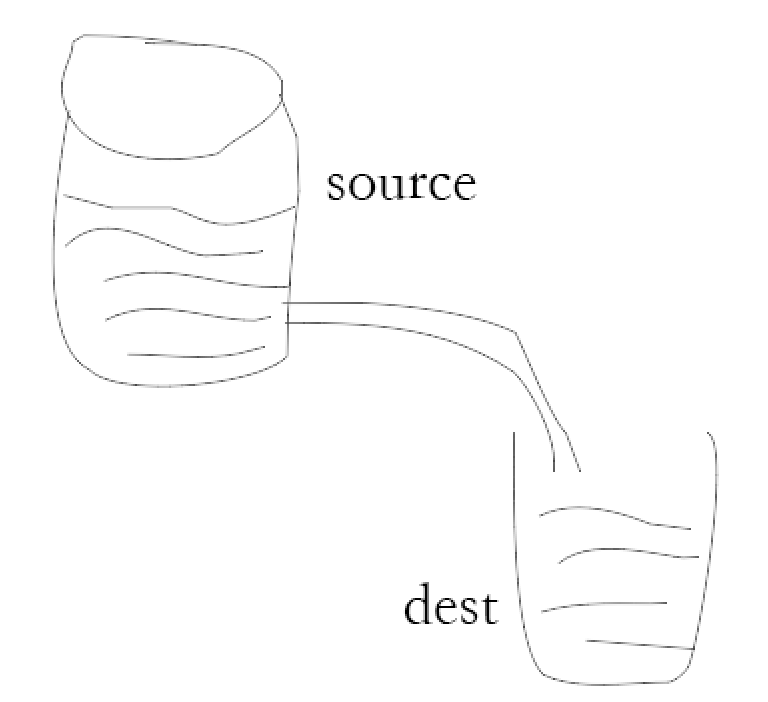
如上代码,我们可以改成如下代码:
const fs = require('fs');
// 读取msg.txt中的字符串 hello world
const msg = fs.createReadStream('./msg.txt', {
highWaterMark: 5
});
// 写入到1.txt中
const f1 = fs.createWriteStream('./1.txt', {
encoding: 'utf-8',
highWaterMark: 1
});
const res = msg.pipe(f1);
console.log(res);
如上打印 res后,我们在命令行中查看下基本信息如下:
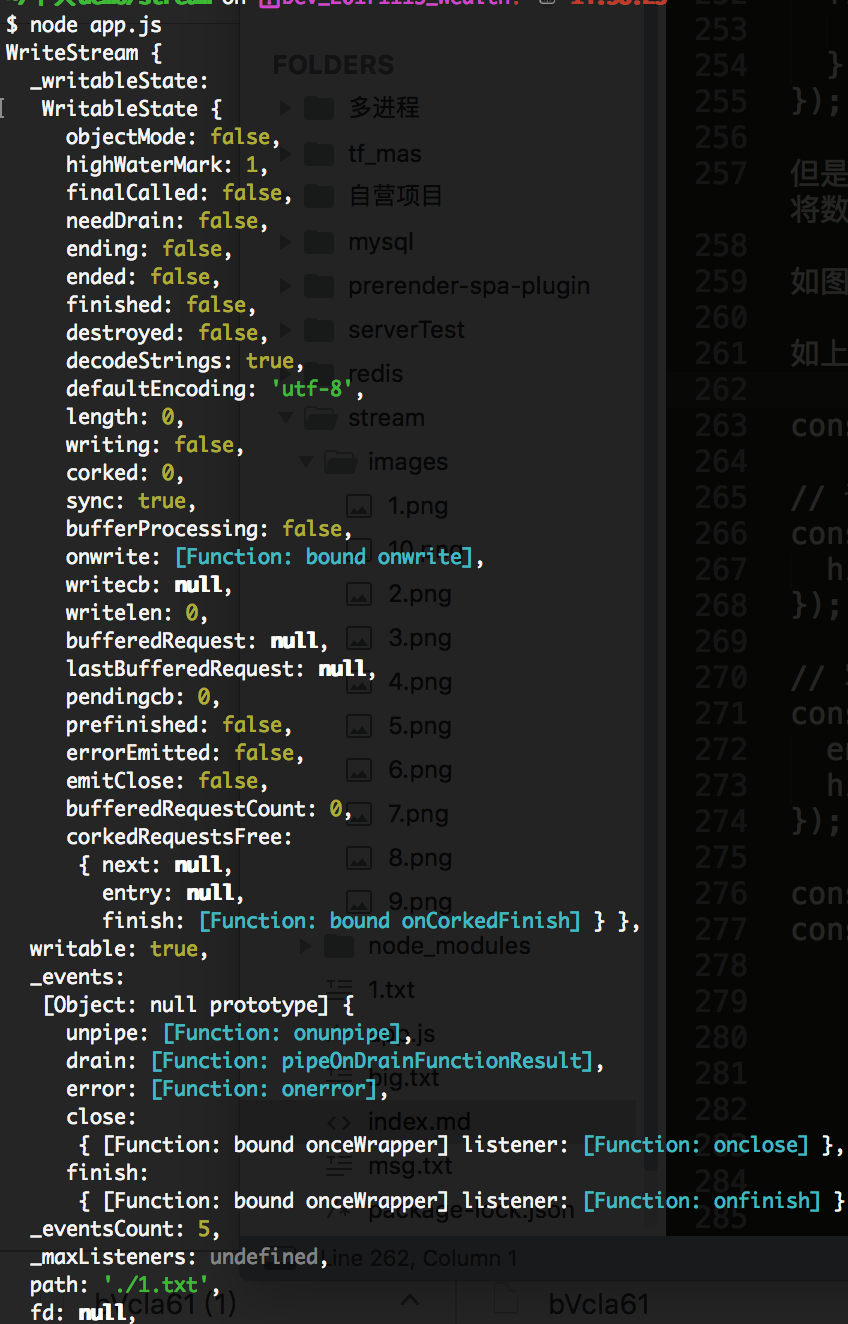

 浙公网安备 33010602011771号
浙公网安备 33010602011771号