
SQL其他常用的语句
2019-04-23 20:49 龙恩0707 阅读(466) 评论(0) 编辑 收藏 举报阅读目录
-
一:汇总数据
-
二:分组数据
-
三:组合查询
-
四:创建表和操纵表
1. AVG函数
该函数的作用是通过对表中行数并计算其列值之和,然后求他们的平均值。
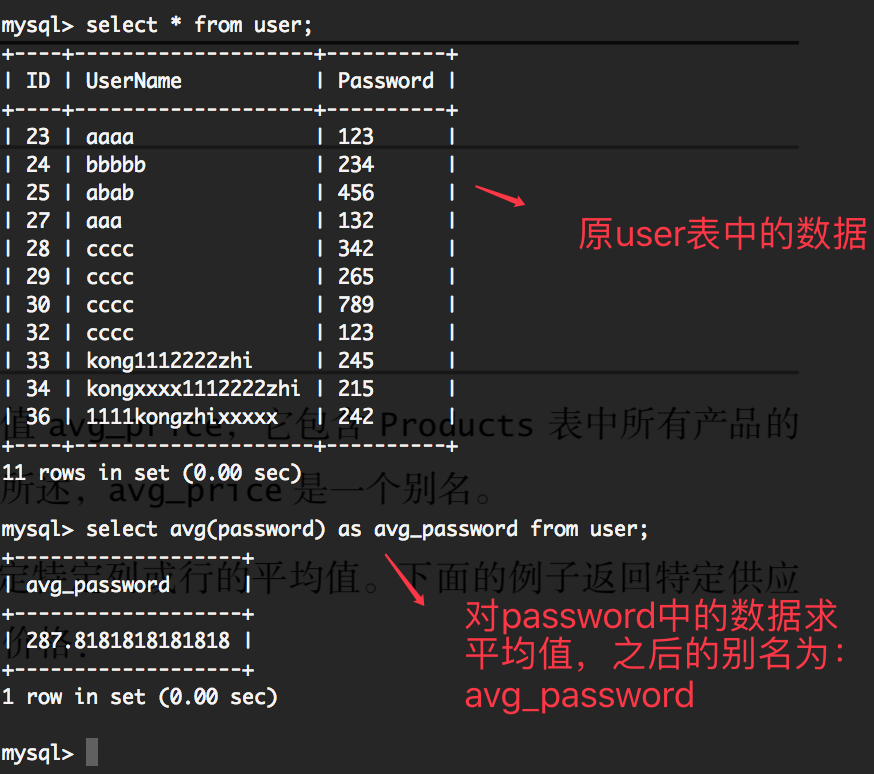
如下代码:select avg(password) as avg_password from user;
如上代码的含义是:从user表中查询password这个字段,求他们的平均值,然后该列的平均值别名叫 avg_password;
如下图所示:
当然我们可以对特定的列或行的平均值。如下是对特定的列的平均值。如下代码:
select avg(password) as avg_password from user where username = 'cccc';
如上代码的含义是:从user表中查找password这个字段平均值,然后根据username='cccc' 这个条件去查找。因此如下图所示: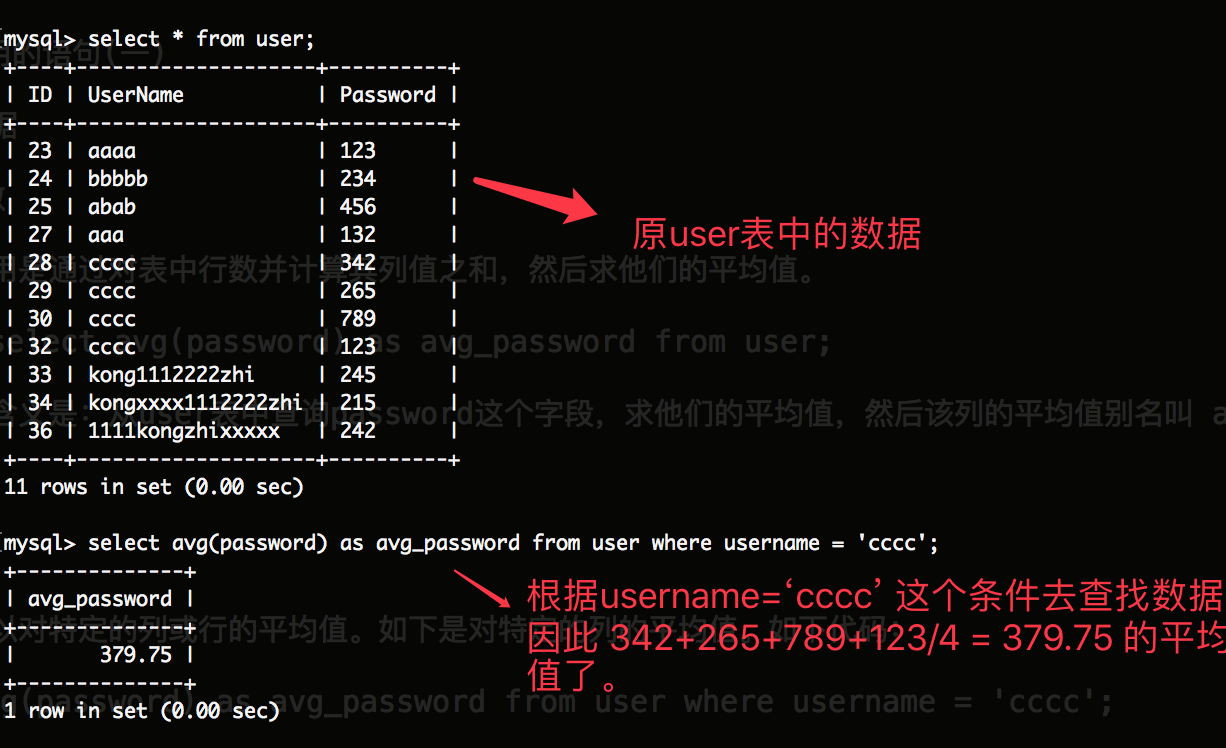
如上所示:如上代码包含了where子句这个条件去查找user表中的数据。
2.理解COUNT()函数
该函数的作用是确定表中行的数目或符合特定条件的行的数目。
该函数有2种使用方式:
1. 使用count(*) 对表中行的数目进行计数,不管表中包含的是空值(null) 还是非空值。
2. 使用count(column) 对特定列中具有值的行进行计数,忽略NULL值。
如下语法:select count(*) as num_count from user;
该代码的作用是:从user表中查询总行数,然后把该列的别名叫做 num_count; 如下图所示:
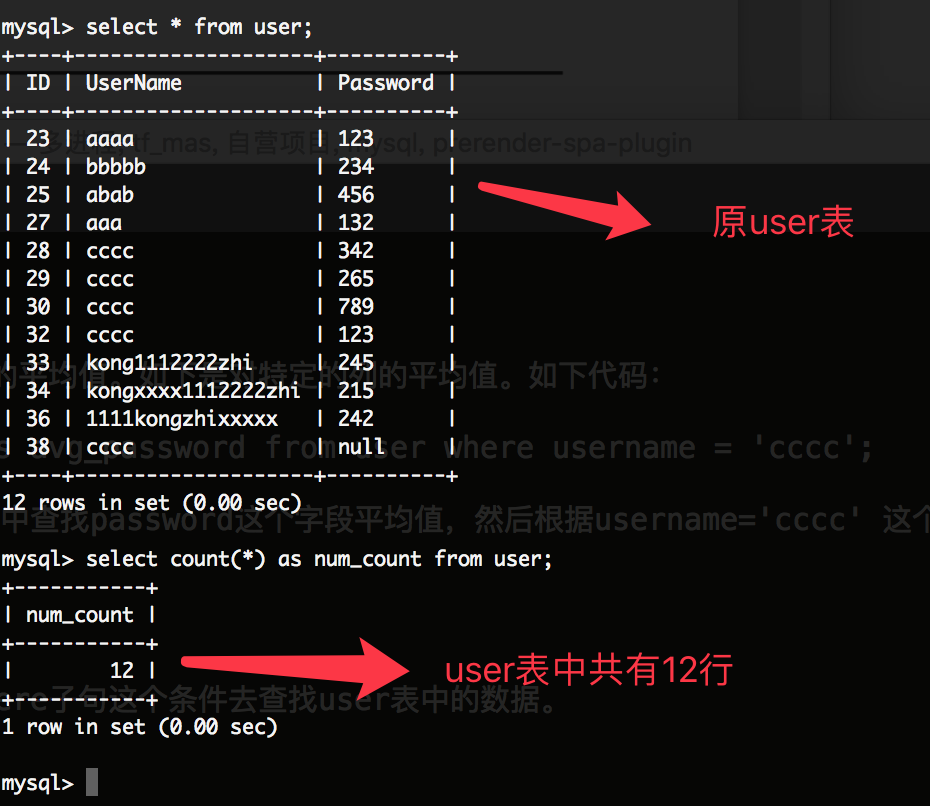
在如上代码中,使用了count(*) 对所有的行计数,不管行中各列有什么值。它都返回到总行数里面去。
3.理解max()函数
max()函数返回指定列中的最大值。max()要求指定列名,如下所示:
select max(password) as max_value from user;
如上代码的含义是:查询user表中password字段的最大值,取名该列的别名为 max_value. 如下图所示:
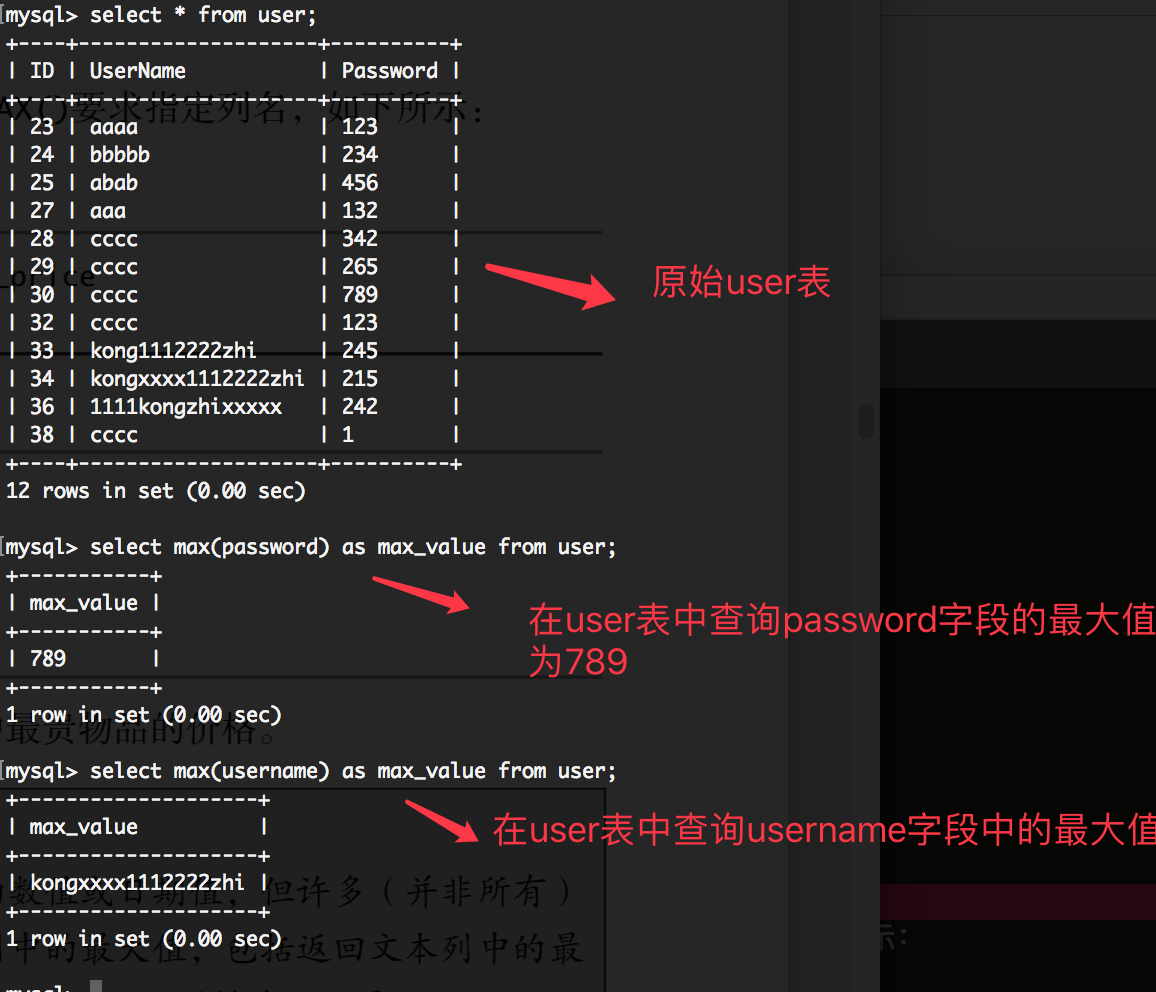
4.理解min()函数
min()函数的作用是返回指定列的最小值。该函数和max()方法一样需要指定列名。如下所示:
select min(password) as min_value from user;
如下图所示:

5.理解sum()函数
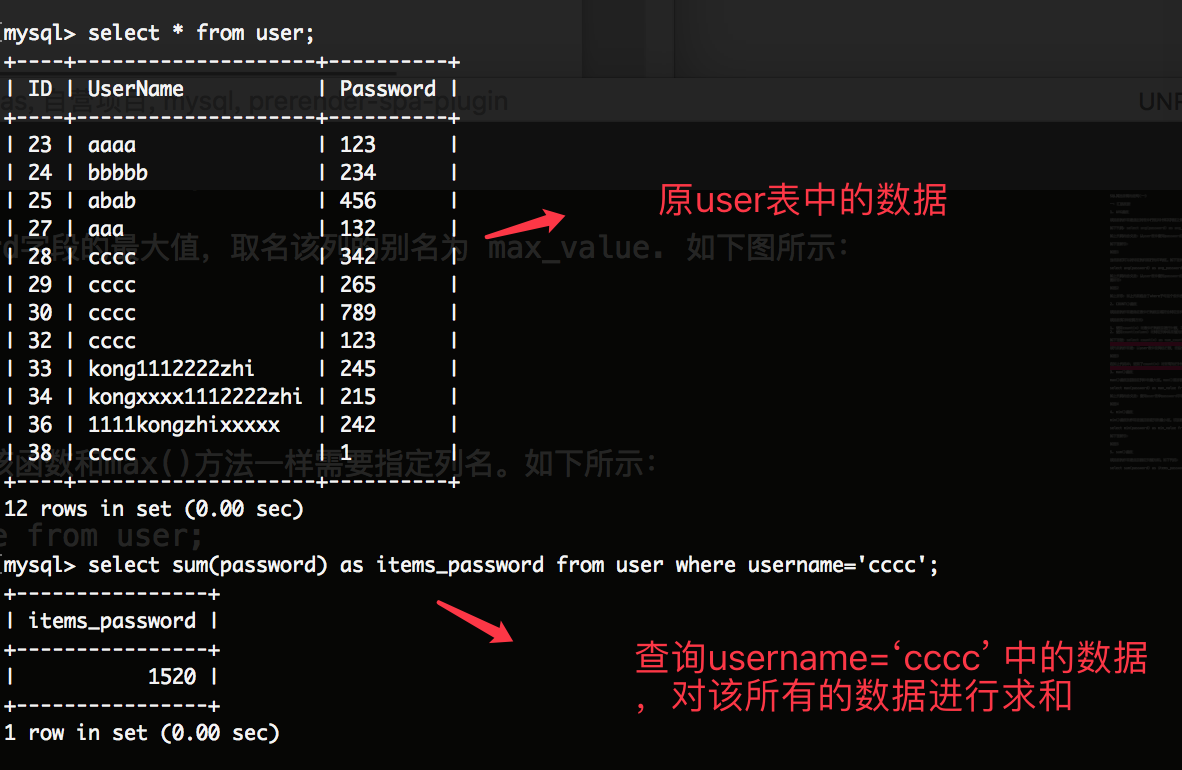
该函数的作用是返回指定列值的和。如下代码:
select sum(password) as items_password from user where username='cccc';
如下图所示:
6 创建分组(group by)
比如说我想知道user表中的某个数据的总数有多少,我们一般会使用我们前面介绍的count这个函数来计算,比如如下代码:
select count(*) as num_count from user where username='cccc';
如上语法的含义是 我们查询user这张表中的所有数据,然后根据字段 username ='cccc' 这个条件去查找的。如下所示:

但是如果我现在想知道每个表中的username对应的各个字段的总数是多少,我们该怎么办呢?我们总不可能每个都去执行一遍吧?那么这个时候分组就非常有用了。
分组是使用select语句的group by子句建立的。比如如下代码:
select username, count(*) as num_count from user group by username;
如上代码的含义是: 从user这张表中查询username这个字段,通过username这个字段去获取该总数。然后把该username的别名叫 num_count; 如下所示: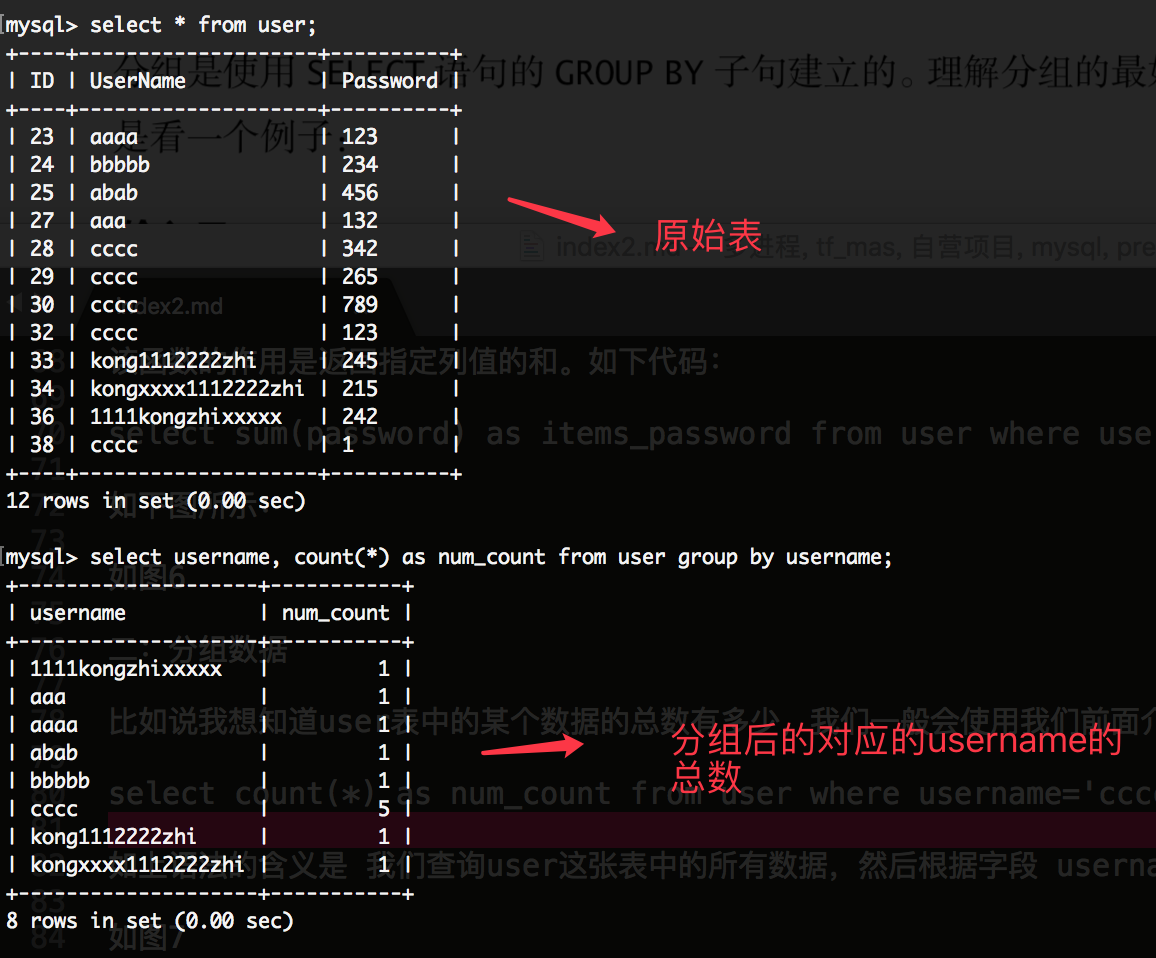
group by 注意事项:
group by子句可以包含任意数目的列,因此可以对分组进行嵌套。更细致地进行数据分组。
7 HAVING过滤分组
除了能用group by分组数据外,我们还可以使用过滤分组,规定包括哪些分组,排除哪些分组。我们之前也说过 where语句也可以进行过滤条件,但是where只能过滤的是行,而不是分组,因此我们这边不能使用where来过滤分组。因此 HAVING子句就出现了。
注意:HAVING支持所有的where操作符。
如下代码:
select username,count(*) as num_count from user group by username having count(*) >=2;
如上代码的含义是:查询user这张表,根据username这个字段进行分组,并且根据username这个字段查询到对应的总数,并且过滤的条件是总数大于2的数量。因此会把username这个字段总数小于2的数据会全部过滤掉,如下图所示:
having和where的差别:
where在数据分组前进行过滤的,having在数据分组后进行过滤的。这是这两个用法的最主要的区别。
那么我们也可以把这两者一起使用,如下语法:
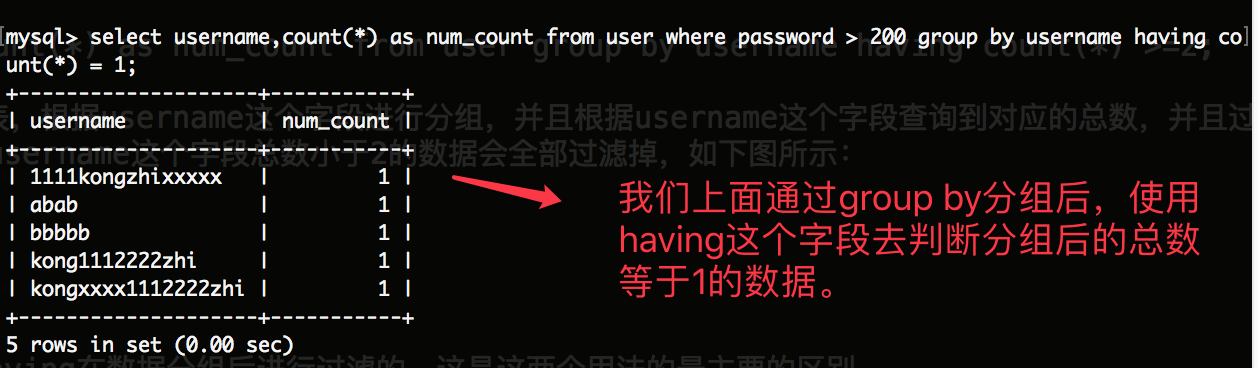
select username,count(*) as num_count from user where password > 200 group by username having count(*) = 1;
如上代码的含义是:查询user这张表中所有的数据,根据username这个字段去获取该user表中的总数,然后使用where语句去根据password这个字段进行判断,该值大于200的数据。并且使用username进行分组,并且分组后的数据总数等于1的数据。如下所示:

8 分组和排序(order by)
group by是对数据进行分组,那么order by就是对分组后的数据进行排序。比如如下语法:
select username,count(*) as items from user group by username having count(*) >= 2 order by items, username;
如上代码含义是:查询user这张表中的字段username,通过username这个字段获取总数,并且通过having这个关键字过滤掉总数小于2的数据,最后我们通过 order by通过别名items进行排序。如下图所示: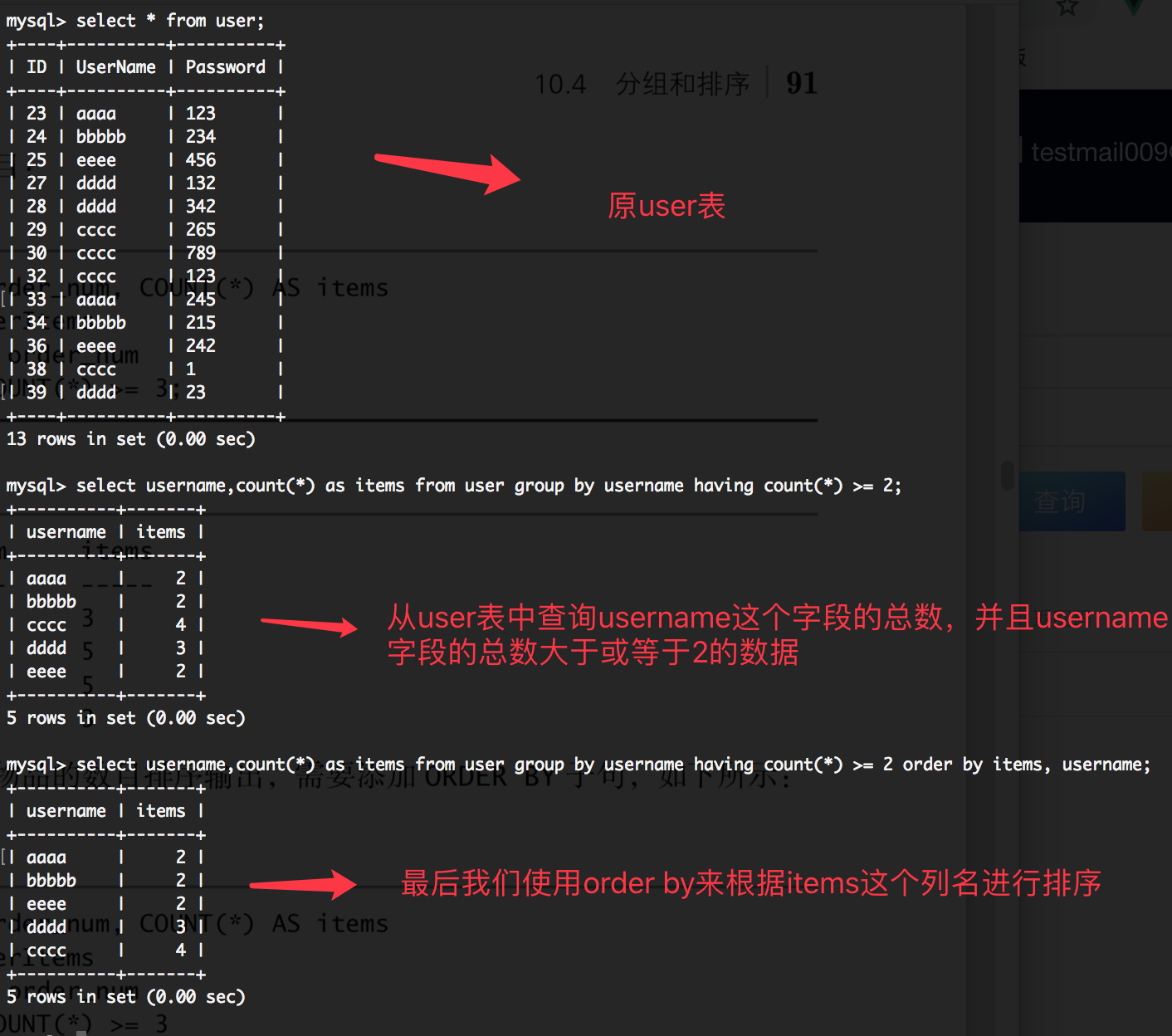
select 子句顺序一些含义:
select: 要返回的列或表达式。
where: 行级过滤。
group by: 分组说明
having: 分组过滤
order by: 对分组进行排序。
9. 创建组合查询(UNION 和 UNION ALL)
sql查询只包含从一个或多个表中返回数据的单条select语句。但是sql也允许执行多个查询(多条select语句)。并将结果作为一个查询结果集返回。这些组合查询一般叫复合查询。
有下面两种情况需要组合查询:
1. 在一个查询中从不同的表返回结构数据。
2. 对一个表执行多个查询,按一个查询返回数据。
可以使用UNION操作符来组合多条sql查询。利用UNION, 可给出多条select语句,将他们的结果组合成一个结果集。
使用UNION很简单,在各条select语句之间放上关键字 UNION。
举个列子,比如 我使用 select * from user where username in ('aaaa','eeee'); 这个sql语句查询出数据出来后,我再使用如下这个:select * from user where id=27; 语句也能查询出数据,那么我现在想结合这两种查询,查询出数据,那么需要sql语句如下:
select * from user where username in ('aaaa','eeee') UNION select * from user where id=27;
如下图所示:

但是我们使用or关键字更简单,如:select * from user where username in ('aaaa','eeee') or id=27;
如下所示:
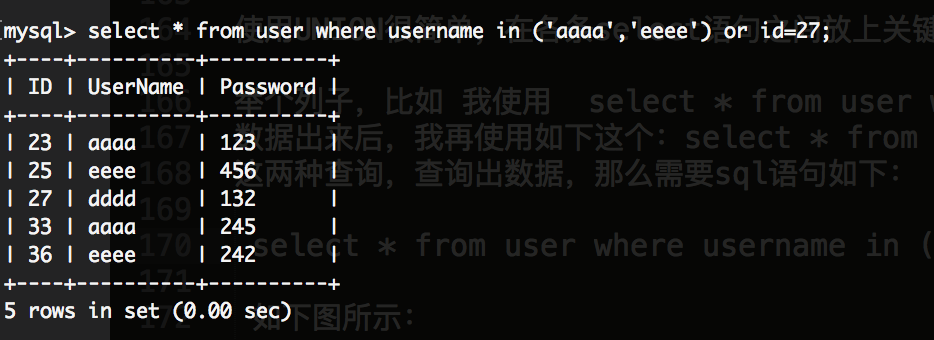
注意:对于在多个表中检索数据的情形,使用UNION可能处理更简单,但是对于一个表中使用多条语句查询建议使用or关键字可能会简单。
10. 对组合查询结果排序
在使用UNION组合查询时,只能使用一条ORDER BY 子句进行排序,并且它必须位于最后一条select语句之后。
如下语句:
select * from user where username in ('aaaa','cccc') UNION ALL select * from user where id=27 order by username;
如下图所示:

11. 创建表的语句使用 create table 语句。
1. 创建表的语句使用 create table 语句。
CREATE TABLE User ( ID int NOT NULL AUTO_INCREMENT, UserName varchar(255) NOT NULL, Password varchar(255) NOT NULL, PRIMARY KEY (ID) );
12. 更新表使用 alter table 语句
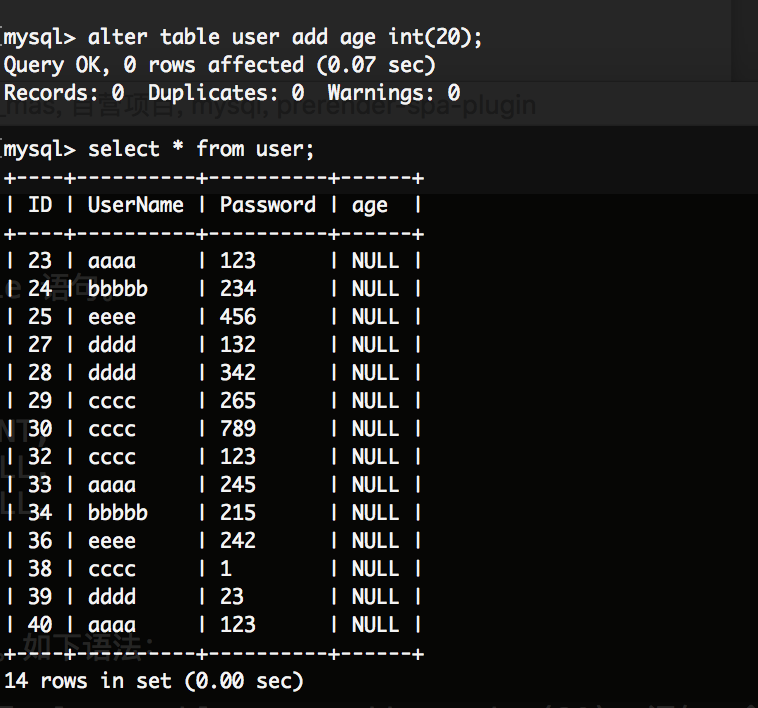
比如我们想给user表添加一列,就使用 alter table user add age int(20); 语句,会增加一列age。如下所示:
13. 删除表中的列
删除表中的列,使用 alter table user drop column age; 语句,如下所示:

如上是使用drop column 关键字删除age这个列。
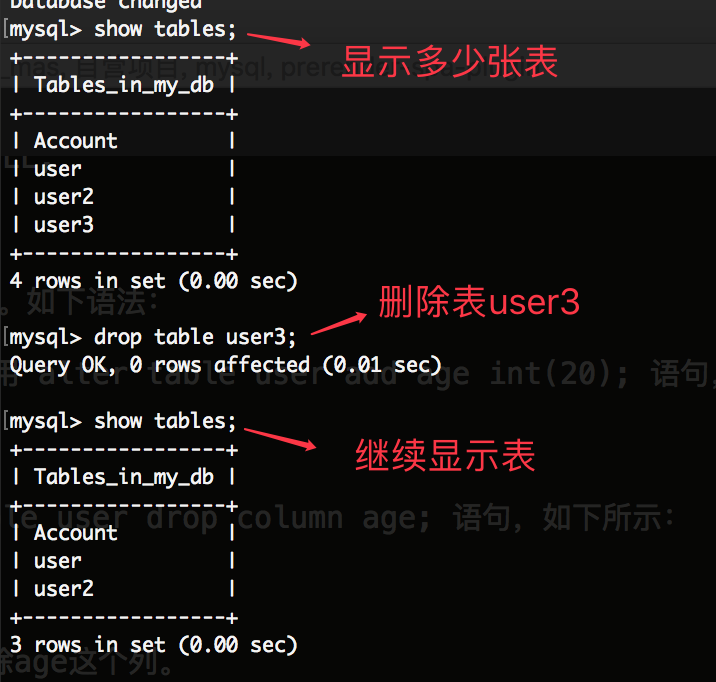
14. 删除表 drop table 表名;
删除表 drop table 表名; 语法:drop table user3; 如下所示:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
· 使用C#创建一个MCP客户端
2018-04-23 socket实现聊天功能(二)
2017-04-23 ES6新语法
2017-04-23 ES5与ES6对比
2014-04-23 简单的表格json控件