【Python爬虫学习-案例练习(3)】:requests+BeautifulSoup库爬取猫眼电影(深度爬取)
一、分析
1、爬取网址:https://maoyan.com/films
2、爬取按“经典影片”,“按评价排序”筛选后的电影数据
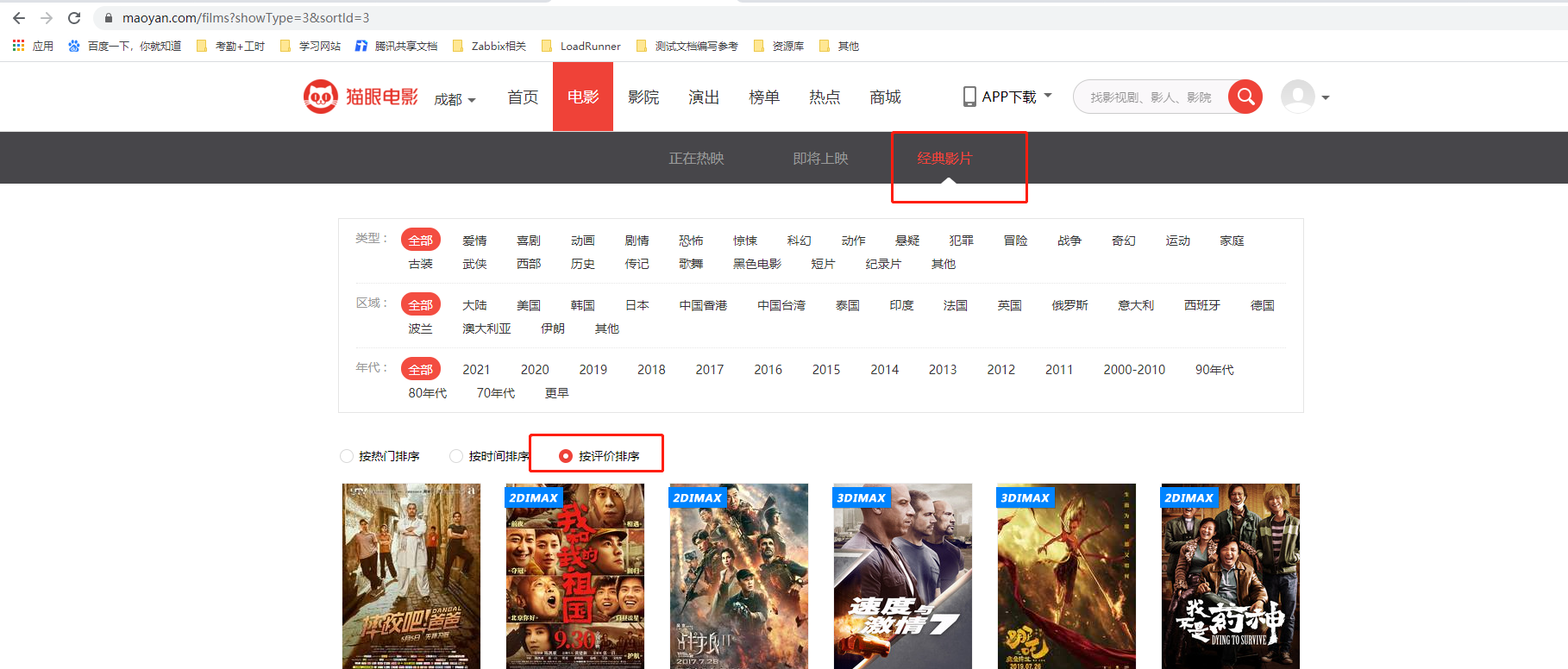
3、滑动到页面底部,多点击几次不同页面发现url地址的规律

提取url为:https://maoyan.com/films?showType=3&sortId=3&offset=0
4、分析元素
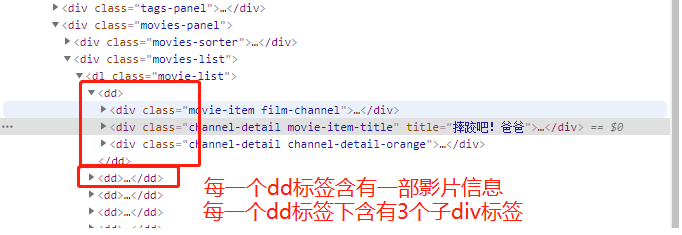
-------分割线--------

-------分割线--------
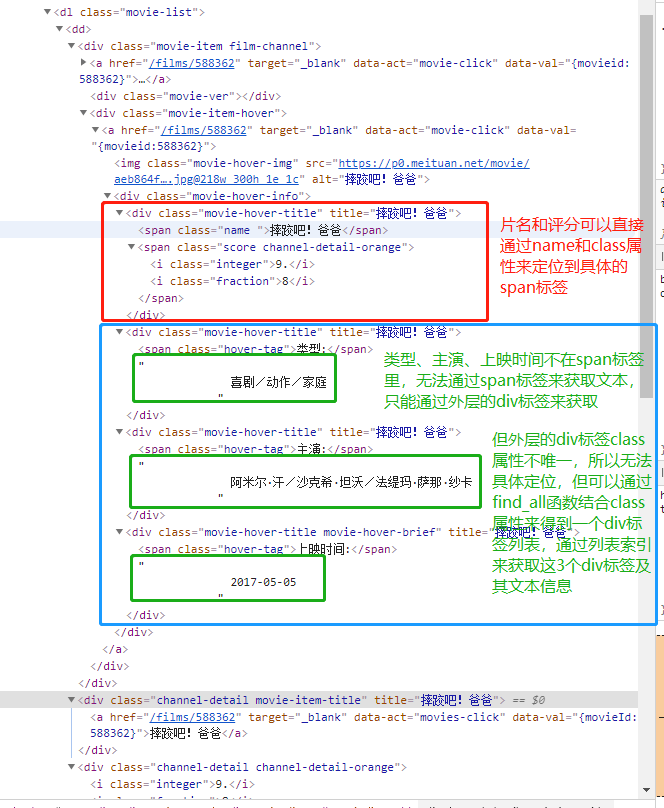
先将所有的dd标签找到,得到一个存放所有dd标签的列表:filmList = bs.find_all(name='dd')
再遍历dd标签列表,每一个dd标签通过属性值的方式来找到其内部的对应属性的div标签或者span标签,获取其文本信息
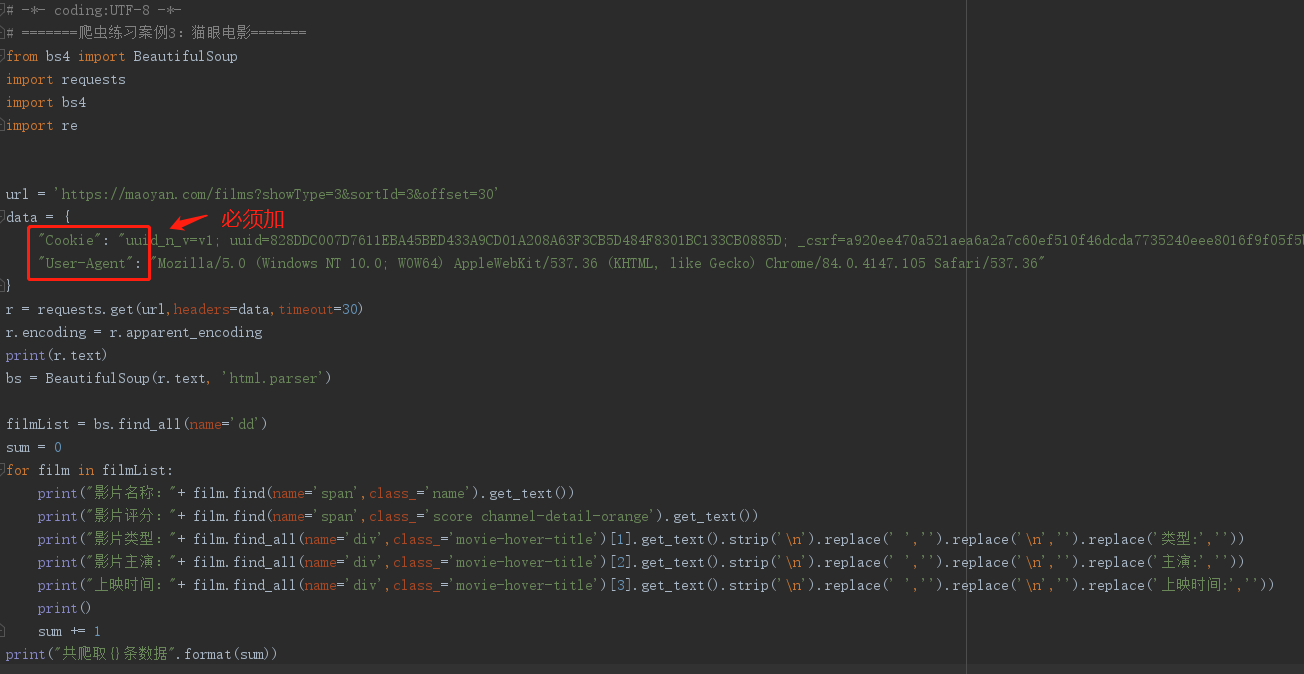
二、先写一个demo代码
注意:该网站访问必须加上Cookie和User-Agent(试了多次发现的,不加上访问不到数据)
爬取第3页的数据:
运行结果:
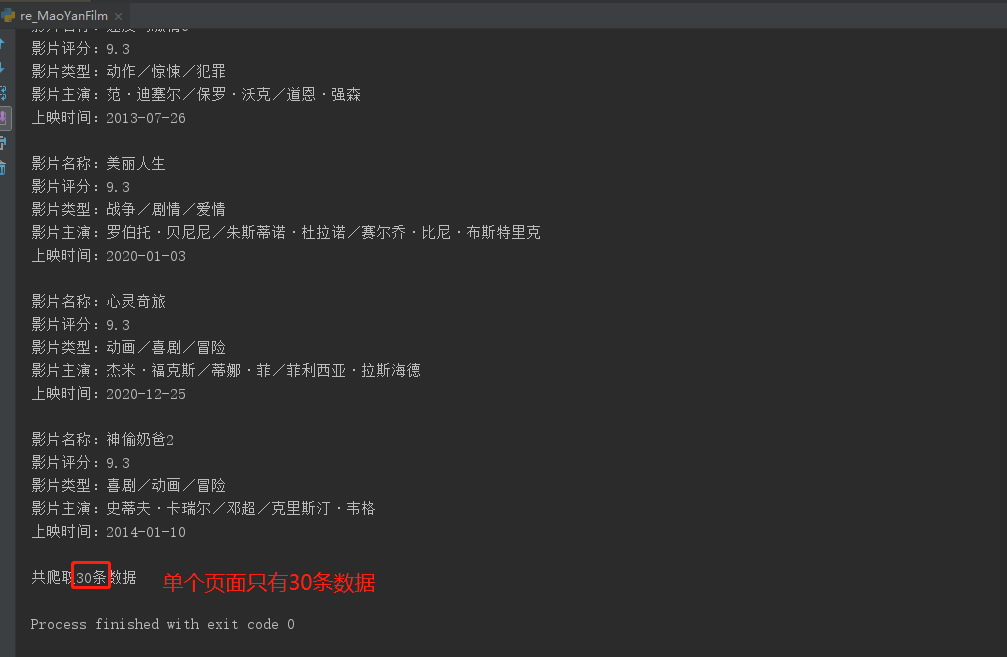
三、加上深度爬取(如爬取前3页的数据)
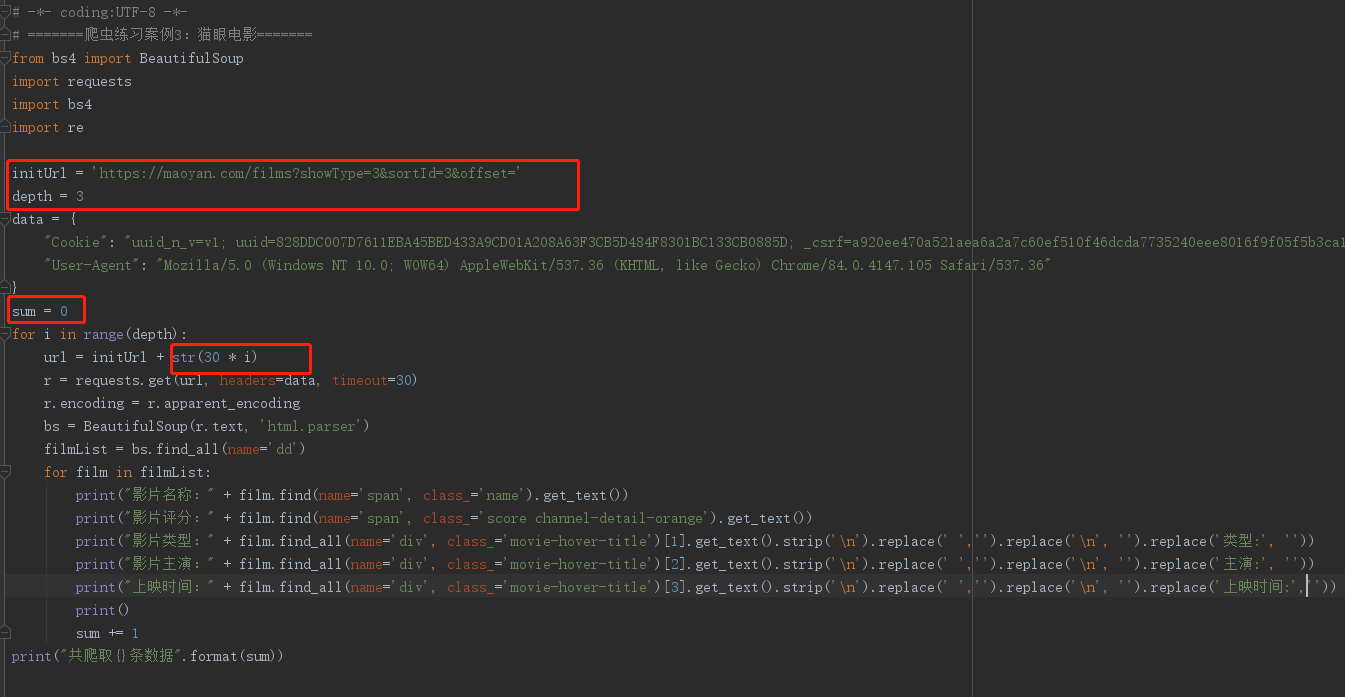
运行结果:

四、代码优化
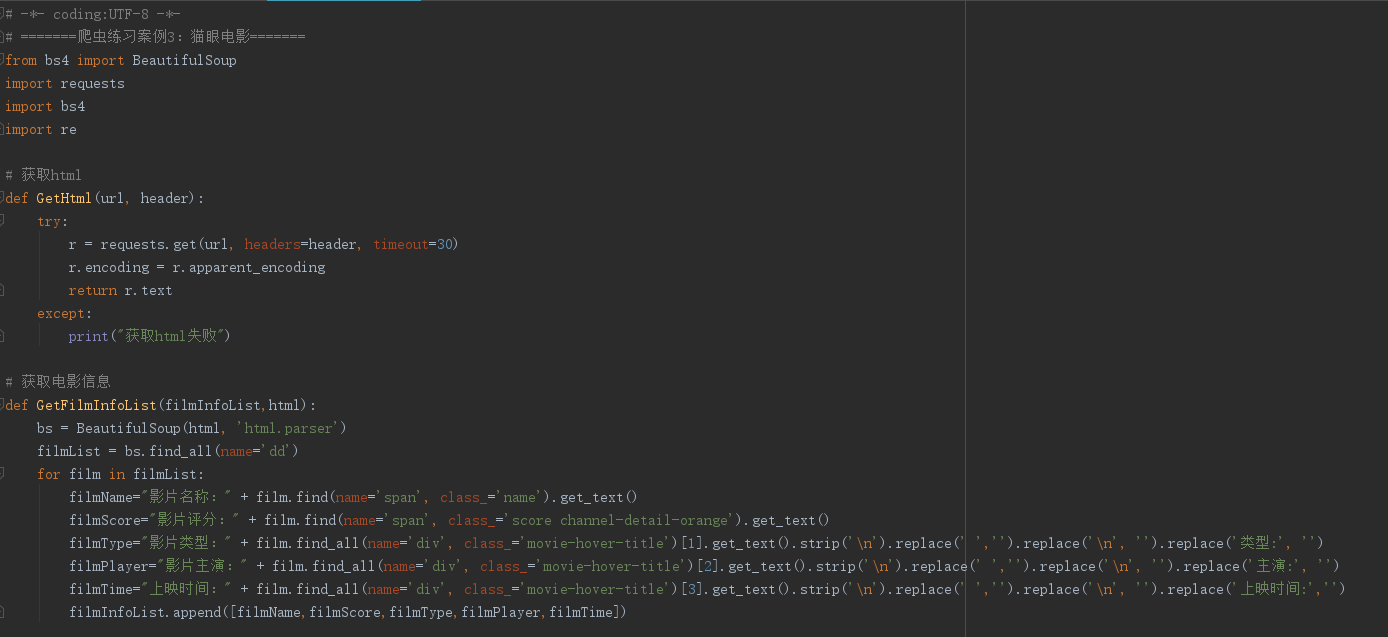
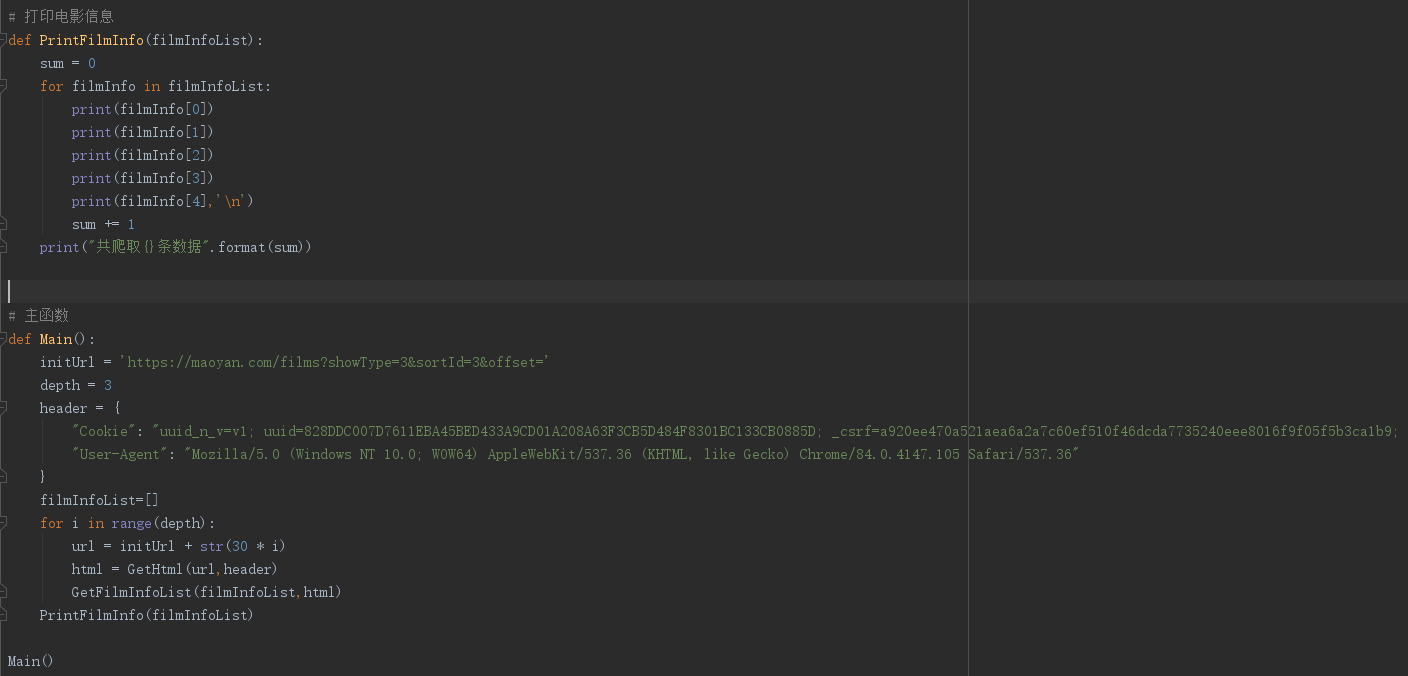
运行结果:

-----end-----

